本文转载自微信公众号「Java极客技术」,作者鸭血粉丝。转载本文请联系Java极客技术公众号。
阿粉的一个小学妹最近刚从某个小互联网公司跳槽,然后最近面试的挺多的,一个不善言语的小姑娘,技术还是 OK 的,本来之前是做 UI 的,但是时间长了,感觉没太大意思,所以就开始学了后端,然后从原有公司慢慢的转为了后端开发人,也就是我们所说的 “程序猿”,最近面试给阿粉谈了谈她的面试经验。阿粉比较印象深刻的一句话就是,我给你画个图,你看一下,这是对面试官说的,事情是什么样子的呢?
你了解 Redis 穿透和雪崩么?
为什么这么说,因为面试官当你说到 Redis 的时候,面试官问的现在已经不是 "你说一下 Redis 的几种数据结构" ,现在面试问的时候,很多都是对 Redis 的实际使用开始问了,比如说,
- Redis 都有哪些架构模式?单机版,主从复制,哨兵机制,集群(proxy 型),集群(直连型)
- 使用过 Redis 分布式锁么,它是怎么实现的?
- 使用过 Redis 做异步队列么,你是怎么用的?有什么缺点?
- 什么是缓存穿透?如何避免?什么是缓存雪崩?何如避免?
而阿粉的小学妹遇到的就是关于 Redis 的缓存穿透和雪崩问题了。这个问题学妹配合了一波自己的 UI 功底图加上口头的解释,于是成功的拿到了这个 Offer,也可能是因为小学妹比较美丽并且技术还过的去。所以,就准备入职了。
我们来看看小学妹到底画了什么图,让面试官问了一波之后就入职了。
缓存穿透
如图:图是阿粉找小学妹专门画出来的,大家看一下
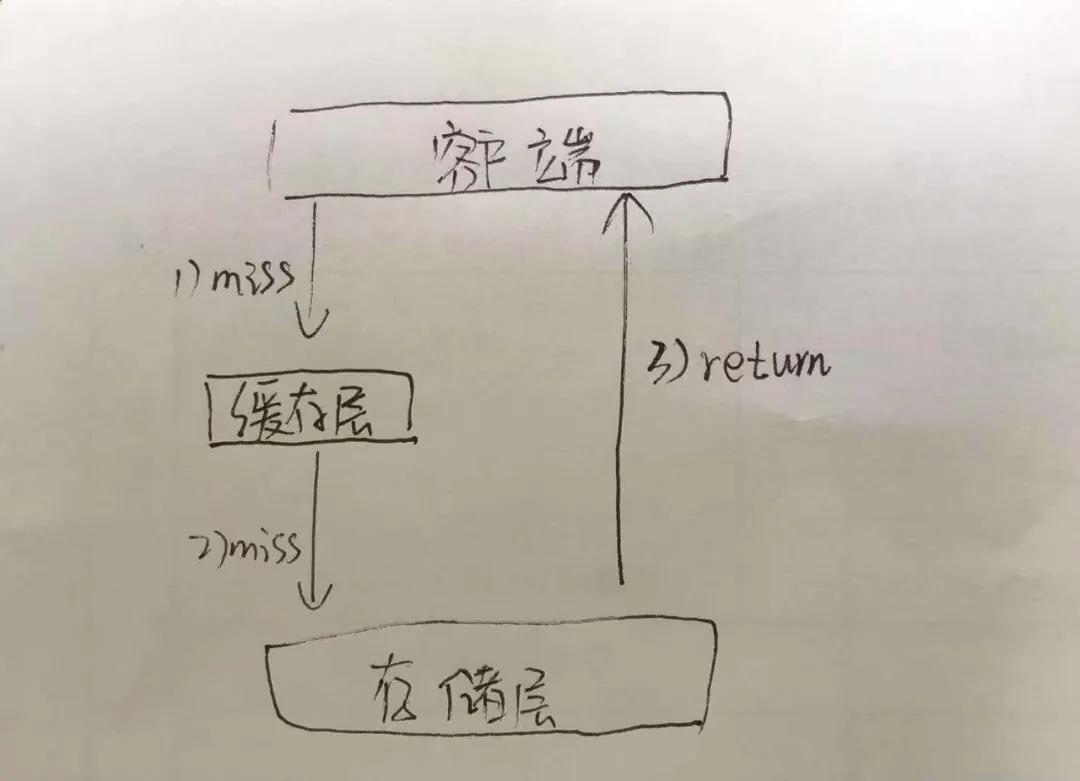
既然我们看完图了,相信大家也都看到了什么是缓存穿透了,也就是说,在我们的缓存系统中,也就是 Redis 中,我们都是拿着我们的 Key 去 Redis 中去寻找 Value 中,如果说我们在 Redis 中找不到我们的数据之后,我们就会去数据库中去寻找我们的数据,如果只是单一请求的话,也不能算是个太大的问题,只能称之为击穿而已,但是如果说要是请求并发量很大的话,就会对我们的数据库造成很大的压力,这其实就称之为缓存穿透,而穿透出现的严重后果,就会是缓存的雪崩了,我们先说穿透,一会再说雪崩。
那么都会有什么情况会造成缓存被穿透呢?
- 自身代码问题
- 一些恶意攻击、爬虫造成大量空的命中。
如果有个黑客对你们公司的项目和数据库比较感兴趣,他就可能会给你整出巨多的一些不存在的ID,然后就疯狂的去调用你们的某项接口,这些本身不存在的 ID 去查询缓存的数据的时候,那就是压根没有的,这时候就会有大量的请求去访问数据库,虽然可能数据能支撑一段时间,但是早晚会让人家给你整的凉了。
那么应该怎么去解决缓存穿透的问题呢?
- 利用互斥锁,缓存失效的时候,先去获得锁,得到锁了,再去请求数据库。没得到锁,则休眠一段时间重试。
- 采用异步更新策略,无论 Key 是否取到值,都直接返回。Value 值中维护一个缓存失效时间,缓存如果过期,异步起一个线程去读数据库,更新缓存。需要做缓存预热(项目启动前,先加载缓存)操作。
- 提供一个能迅速判断请求是否有效的拦截机制,比如,利用布隆过滤器,内部维护一系列合法有效的 Key。迅速判断出,请求所携带的 Key 是否合法有效。如果不合法,则直接返回。
- 布隆过滤器实际上是一种比较推荐的方式。
布隆过滤器的实现原理则是这样的:
当一个变量被加入集合时,通过 K 个映射函数将这个变量映射成位图中的 K 个点,把它们置为 1。查询某个变量的时候我们只要看看这些点是不是都是 1 就可以大概率知道集合中有没有它了,如果这些点有任何一个 0,则被查询变量一定不在;如果都是 1,则被查询变量很可能在。注意,这里是可能存在,不一定一定存在!这就是布隆过滤器的基本思想。
而当你说出布隆过滤器的时候,可能这才是面试官想要问你的内容,这时候你就得好好的和面试官开始聊聊什么事布隆过滤器了。
我们还是继续用大众都想看到的图解来解释布隆过滤器。
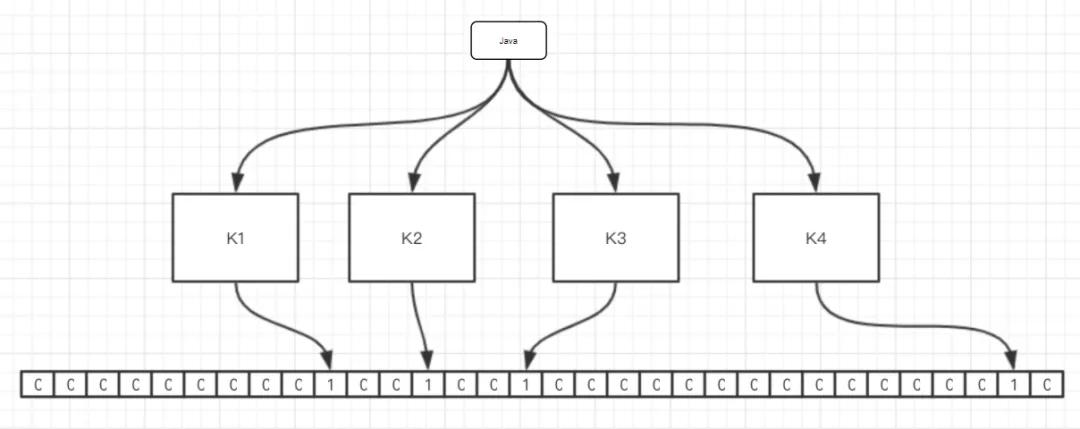
字符串 "Java" 在经过四个映射函数操作后在位图上有四个点被设置成了 1。当我们需要判断 “ziyou” 字符串是否存在的时候只要在一次对字符串进行映射函数的操作,得到四个 1 就说明 “Java” 是可能存在的。
注意语言,是可能存在,而不是一定存在,
那是因为映射函数本身就是散列函数,散列函数是会有碰撞的,意思也就是说会存在一个字符串可能是 “Java1” 经过相同的四个映射函数运算得到的四个点跟 “Java” 可能是一样的,这种情况下我们就说出现了误算。
另外还有可能这四个点位上的 1 是四个不同的变量经过运算后得到的,这也不能证明字符串 “Java” 是一定存在的。
而我们使用布隆过滤器其实就是提供一个能迅速判断请求是否有效的拦截机制,判断出请求所携带的 Key 是否合法有效。如果不合法,则直接返回。
而阿粉的小学妹给面试官解释了一波这操作之后,看样子,面试官对这个“程序猿”开始有点印象了,接下来就顺着问了,那什么事缓存的雪崩呢?
缓存雪崩
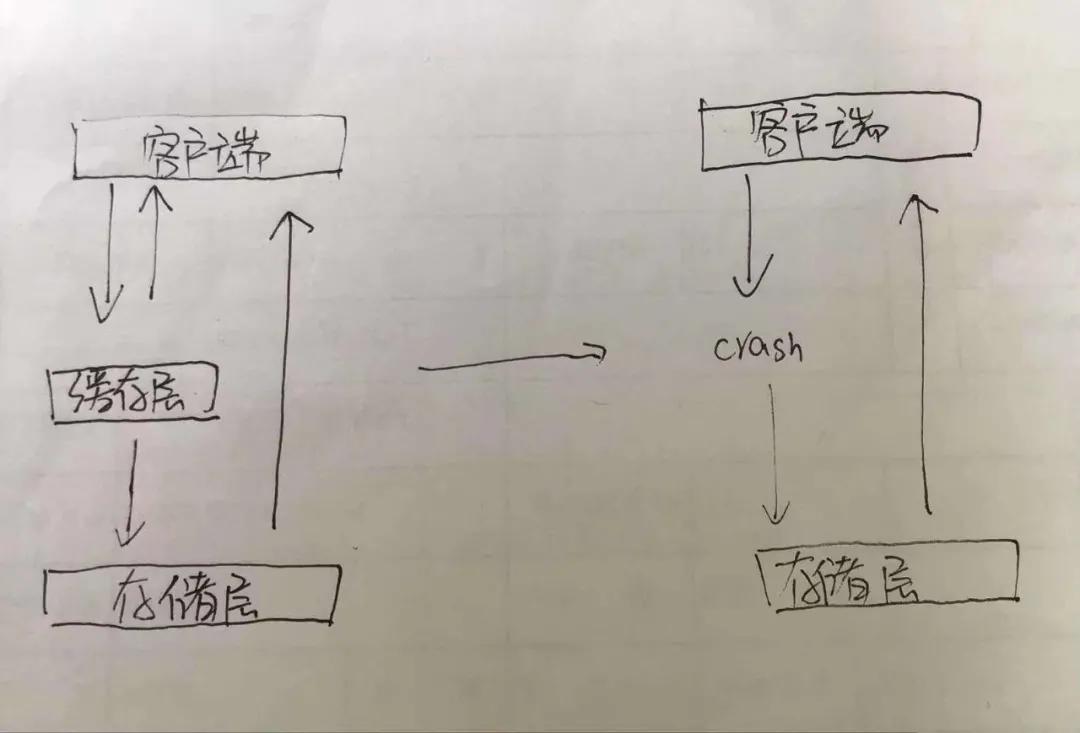
这时候也就是说,当我们有多个请求访问缓存的时候,这时候,缓存中的数据是没有的,也就是说缓存同一时间大面积的失效,这个时候又来了一波请求,结果请求都怼到数据库上,从而导致数据库连接异常
他和穿透实际上相似但是又有所不同,相似的地方是都是搞数据库,不同的是缓存穿透是指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库
而解决缓存雪崩的策略也是比较多的,而且都是比较实用的。比如:
- 给缓存的失效时间,加上一个随机值,避免集体失效。
- 双缓存。我们有两个缓存,缓存 A 和缓存 B。缓存 A 的失效时间为 20 分钟,缓存 B 不设失效时间
双缓存策略比较有意思,当请求来临的时候,我们先从 A 缓存中获取,如果 A 缓存有数据,那么直接给他返回,如果 A 中没有数据,那么就直接从 B 中获取数据,直接返回,与此同时,我们启动一个更新的线程,更新 A 缓存和 B 缓存,这就是双缓存的策略。
上述的处理缓存雪崩的情况实际上都是从代码上来进行实现,而我们换个思路考虑呢,也就是从架构的方向去考虑的话,解决方案就是以下的几种了。
- 限流
- 降级
- 熔断
那么怎么实现限流呢?
说到限流降级了,那就不能单纯的去针对 Redis 出现的问题而进行处理了,而实际上是为了保证用户保护服务的稳定性来进行的。
那么为什么要去限流呢?你要单纯的说是为了保证系统的稳定性,那面试官估计得崩溃,这和没说有啥区别,你得举个简单的例子才能正儿八经的忽悠住面试官,比如:
假设,我们当前的程序能够处理10个请求,结果第二天,忽然有200多请求一起过来,整整翻了20倍,这时候,程序就凉了,但是如果第一天晚上的时候,领导给你说,明天你写的那个程序大约会有200多个请求要处理,你这时候是不是得想办法,比如说,能不能再写出另外的一段程序来进行分担请求,这时候其实就相当于需要我们去限流了。
限流算法之漏桶算法
同样的,我们整个图来理解一下这个算法到底是怎么实现的。
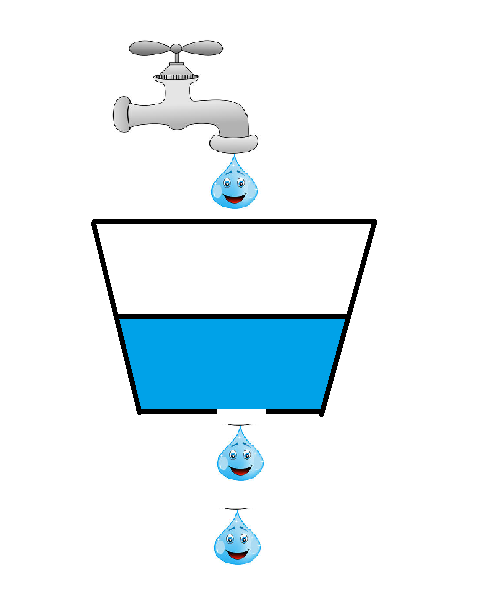
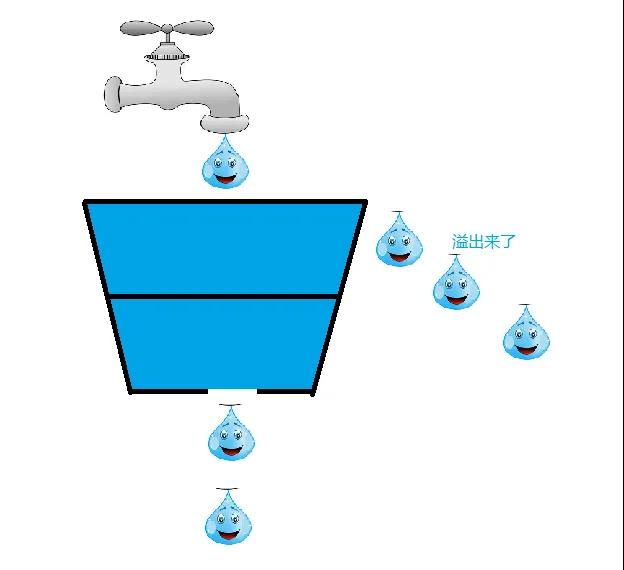
如果一桶有一个细眼,我们往里面装水,可以看到水是一滴一滴匀速的下落的,如果桶满了就拒绝水滴继续滴入,没满的话就继续装水,实际上就是这样的水滴实际上就相当于是请求,如果水桶没满的时候,还能继续处理我们进来的请求,当水桶满了的时候,就拒绝处理,让他溢出。
前提是我们的这个桶是个固定的容器,不能随着水的增多桶会变大,要不然那还用什么限流算法。
简单的漏桶算法的实现:
- public class LeakyBucket {
- public long timeStamp = System.currentTimeMillis(); // 当前时间
- public long capacity; // 桶的容量
- public long rate; // 水漏出的速度
- public long water; // 当前水量(当前累积请求数)
- public boolean grant() {
- long now = System.currentTimeMillis();
- // 先执行漏水,计算剩余水量
- water = Math.max(0, water - (now - timeStamp) * rate);
- timeStamp = now;
- if ((water + 1) < capacity) {
- // 尝试加水,并且水还未满
- water += 1;
- return true;
- } else {
- // 水满,拒绝加水
- return false;
- }
- }
- }
上面的代码是来自悟空,不得不说,这个简单的例子虽然简单,但是把这个漏桶算法的简单原理描述的还是差不多的,而在这里最需要注意的,就是桶的容量,还有就是水桶漏洞的出水的速度。
既然我们了解了漏桶算法是如何实现限流的,那么必然也会有他处理不来的情况,因为我们已经定义了水漏出的速度,而这时候如果应对突发的流量忽然涌进来,他处理起来效率就不够高了,因为水桶满了之后,请求都拒绝了,都不处理了。
其实我们所说的漏桶算法还可以看作是一个带有常量服务时间的单服务器队列,如果漏桶(包缓存)溢出,那么数据包会被丢弃。
而我们的漏桶算法主要是能够强行限制数据的传输速率。
那么又有什么算法能够不进行强制限制传输速率,并且实现限流呢?
令牌桶算法
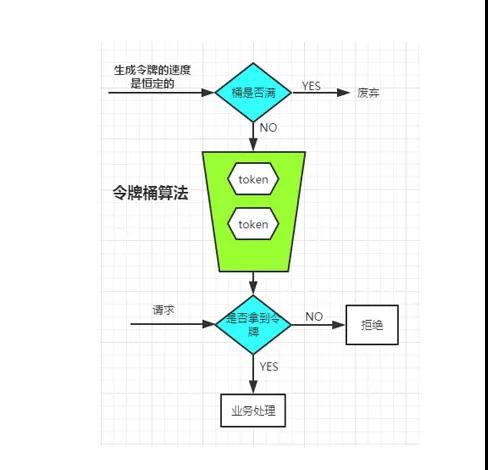
我们感谢百度,我从百度图片中找了个一个比较给力的图来描述令牌桶的算法。
令牌桶算法的基本过程是这个样子的:
- 用户配置的平均发送速率为r,则每隔1/r秒一个令牌被加入到桶中
- 假设桶最多可以存发b个令牌。如果令牌到达时令牌桶已经满了,那么这个令牌会被丢弃
- 当一个n个字节的数据包到达时,就从令牌桶中删除n个令牌,并且数据包被发送到网络
- 如果令牌桶中少于n个令牌,那么不会删除令牌,并且认为这个数据包在流量限制之外
乍一看,怎么感觉这个令牌桶和漏桶这么像,一个是水滴,一个是令牌,实际上不是。
令牌桶这种控制机制基于令牌桶中是否存在令牌来指示什么时候可以发送流量。令牌桶中的每一个令牌都代表一个字节。如果令牌桶中存在令牌,则允许发送流量;而如果令牌桶中不存在令牌,则不允许发送流量。
而且他是能够应对突发限制的,虽然传输的速率受到了限制.所以它适合于具有突发特性的流量的一种算法。
而在 Google 开源工具包中的限流工具类RateLimiter ,这个类就是根据令牌桶算法来完成限流。大家有兴趣的可以去看看呀。
漏桶算法和令牌桶算法的区别
漏桶算法与令牌桶算法实际上看起来有点相似,但是不能混淆哈,这就是阿粉在上面说的:
漏桶算法能够强行限制数据的传输速率。
令牌桶算法能够在限制数据的平均传输速率的同时还允许某种程度的突发传输