概念
- Kafka 是一种高吞吐量、分布式、基于发布/订阅的消息系统,最初由 LinkedIn 公司开发,使用 Scala (JAVA)语言编写,目前是Apache 的开源项目。
- 主要解决应用解耦、异步消息、流量削峰等问题。
- Kafka实际上也是一个主从架构,有一个Controller角色即控制器,协调管理整个集群。
关键术语
broker
Kafka 服务器,负责消息存储和转发。
topic
消息类别,Kafka 按照topic 来分类消息;似于关系型数据库的表。
partition
topic 的分区,一个 topic 可以包含多个 partition ,topic 消息保存在各个 partition 上。
offset
消息在日志中的位置,可以理解是消息在partition 上的偏移量,也是代表该消息的唯一序号。
Producer
消息生产者,将消息push到Kafka集群中的Broker。
Consumer
消息消费者,从Kafka集群中pull消息,消费消息。
Consumer Group
消费者分组,每个Consumer 必须属于一个group
Zookeeper
保存着集群broker、topic、partition 等meta 数据;另外,还负责broker 故 障发现,partition leader 选举,负载均衡等功能。
从抽象到具体理解Kafka架构设计
从宏观的层面来理解,它就是一个存储系统。
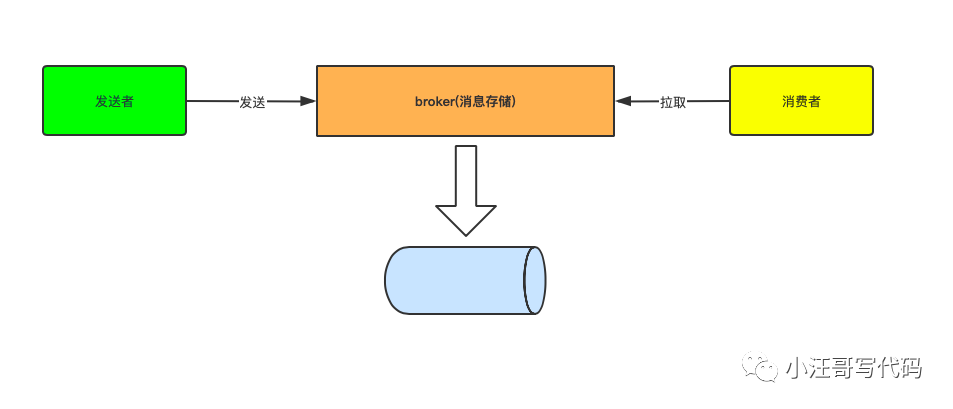
细分一下,又有多个生产者,多个消费者,Broker 集群和Kafka 组成。
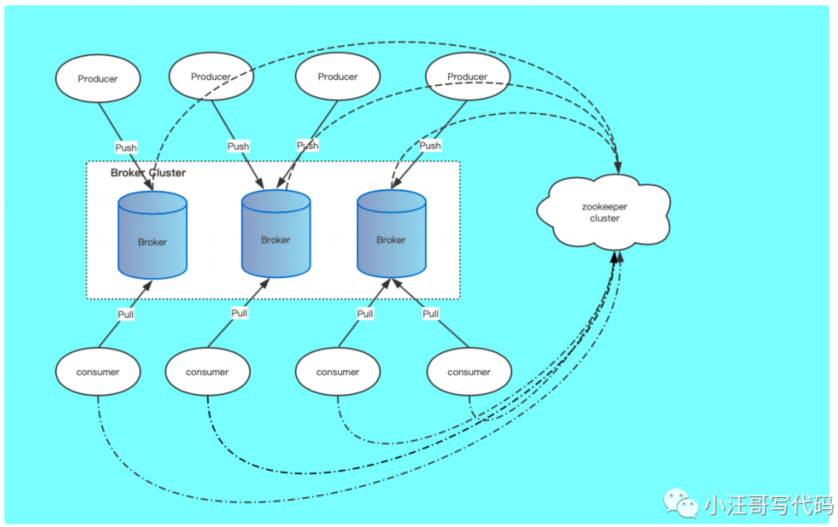
再次细分,broker有一个controller角色,每一个broker 可能存多个Topic的不同partion,每个partion 都有 leader 和follower 。这些信息都会注册到zk上。
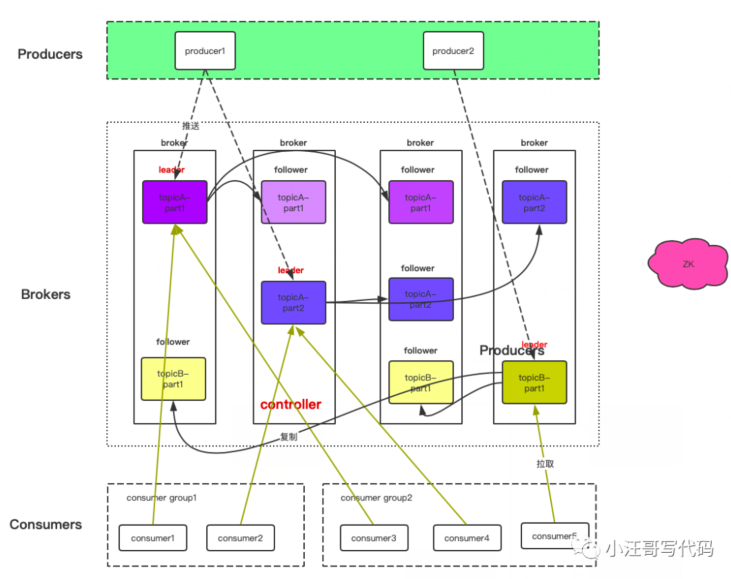
集群架构的理解及新版优化
控制器 controller
我们熟知一个规律:在大数据分布式文件系统里面,95%的都是主从式的架构,个别是对等式的架构,比如ElasticSearch。
kafka也是主从式的架构,主节点就叫controller,其余的为从节点,controller是需要和zookeeper进行配合管理整个kafka集群。
作用
协调与管理整个集群。
职责
- 主题增删改
- 分区重分配
- leader选举
- 元数据管理
- broker成员管理,宕机或加入
控制器选举
基于zookeeper实现,利用了zookeeper的znode模型与监听机制。
控制器故障转移
存在单点故障,但是每个broker节点都可以成为controller;
故障转移即failover也是基于zookeeper实现的,znode模型与监听机制,/controller节点。
kafka和zookeeper如何配合工作
- kafka严重依赖于zookeeper集群。
- 所有的broker在启动的时候都会往zookeeper进行注册,目的就是选举出一个controller
- 选举过程非常简单粗暴,就是一个谁先谁当的过程,不涉及什么算法问题。
- 成为controller之后,它会监听zookeeper里面的多个目录.
- 注册时各个节点必定会暴露自己的主机名,端口号等等的信息,此时controller就要去读取注册上来的从节点的数据(通过监听机制),生成集群的元数据信息,之后把这些信息都分发给其他的服务器,让其他服务器能感知到集群中其它成员的存在。
新版Kafka将要抛弃ZooKeeper!!!!!!
2021年3月30日,Kafka背后的企业Confluent发布博客表示,在即将发布的 2.8 版本里,用户可在完全不需要 ZooKeeper 的情况下运行 Kafka,该版本将依赖于 ZooKeeper 的控制器改造成了基于 Kafka Raft 的 Quorm 控制器。
在之前的版本中,如果没有 ZooKeeper,Kafka 将无法运行。但管理部署两个不同的系统不仅让运维复杂度翻倍,还让 Kafka 变得沉重,进而限制了 Kafka 在轻量环境下的应用,同时 ZooKeeper 的分区特性也限制了 Kafka 的承载能力。
第一次,用户可以在没有 ZooKeeper 的情况下运行 Kafka。
这是一次架构上的重大升级,让一向“重量级”的 Kafka 从此变得简单了起来。轻量级的单进程部署可以作为 ActiveMQ 或 RabbitMQ 等的替代方案,同时也适合于边缘场景和使用轻量级硬件的场景。
为什么要抛弃使用了十年的 ZooKeeper?
zk的缺点:
- zookeeper 的一个缺点就是 同步数据不能太大。
- zookeeper集群中leader和follower同步数据的极限值是500M,这500M的数据,加载到内存中,大约占用3个G的内存。
- 数据过大,在每次选举之后,需要从server同步到follower,容易造成下面2个问题:
- 触发重新选举
- io 太久
ZooKeeper 充当 Kafka 的领导者,以更新集群中的拓扑更改;根据 ZooKeeper 提供的通知,生产者和消费者发现整个 Kafka 集群中是否存在任何新 Broker 或 Broker 失败。大多数的运维操作,比如说扩容、分区迁移等等,都需要和 ZooKeeper 交互。
也就是说,Kafka 代码库中有很大一部分是负责实现在集群中多个 Broker 之间分配分区(即日志)、分配领导权、处理故障等分布式系统的功能。而早已经过业界广泛使用和验证过的 ZooKeeper 是分布式代码工作的关键部分。
假设没有 ZooKeeper 的话,Kafka 甚至无法启动进程,但严重依赖 ZooKeeper,也给 Kafka 带来了掣肘。
不过目前大部分用的还是和zk结合版本的kafka。