













并发编程是 java 高级程序员的必备的基础技能之一。但是想要写好并发程序并非易事。
那究竟是什么原因导致大把的“格子衫”朋友无法写出优质和性能稳定的并发程序呢?根本原因就是大家对并发编程的核心理论的模糊和不理解。想要运用好一项技术。理论知识和核心概念是一定要理解透彻的。
今天我们就来一起看下并发编程三大核心基础理论:原子性、可见性、有序性
1、原子性
先来看下什么叫原子性
第一种理解:原子(atomic)本意是“不能被进一步分割的最小粒子”,而原子操作(atomic operation)意 为“不可被中断的一个或一系列操作”
第二种理解:原子性,即一个操作或多个操作,要么全部执行并且在执行的过程中不被打断,要么全部不执行。(提供了互斥访问,在同一时刻只有一个线程进行访问)
原子,在物理学中定义是组成物体的不可分割的最小的单位。在 java 并发编程中我们可以将其理解为:一组要么成功要么失败的操作。
1.1、原子性问题的产生的原因
原子性问题产生的根本原因是什么?我们只要知道了症状才能准确的对症下药,本小节,我们就来一起探讨下原子性问题的由来。
我们都知道,程序在执行的时候,一定是以线程为单位在执行的,因为线程是 CPU 进行任务调度的基本单位。
电脑的 CPU 会根据不同的任务调度算法去执行线程的调度,将时间分片并派分给各个线程。
当某个线程获得CPU的时间片之后就获取了CPU的执行权,就可以执行任务,当时间片耗尽之后,就会失去CPU使用权。
进而本任务会暂时的停止执行。多线程场景下,由于时间片在线程间轮换,就会发生原子性问题。
看完理论似乎并不能直观的理解原子性问题。下面我们就通过代码的方式来具体阐述下原子性问题的产生原因。
1.2、案例分析
我们以常见的 i++ 为例,这是一个老生常谈的原子性问题了,先来看下代码
- public class AtomicDemo {
- private int count = 0;
- public void add() {
- count++;
- }
- public int get() {
- return count;
- }
- public static void main(String[] args) throws InterruptedException {
- CountDownLatch countDownLatch = new CountDownLatch(100);
- AtomicDemo atomicDemo = new AtomicDemo();
- IntStream.rangeClosed(0, 100).forEach(item -> {
- new Thread(() -> {
- IntStream.rangeClosed(1, 100).forEach(i -> {
- atomicDemo.add();
- });
- }).start();
- countDownLatch.countDown();
- });
- countDownLatch.await();
- System.out.println(atomicDemo.get());
- }
- }
上面 代码的作用是将初始值为0的 count 变量,通过100线程每个线程累加100次的方式来累加。想要得到一个结果为 10000 的值。但是实际上结果很难达到10000。
产生这个问题的原因:
count++ 的执行实际上这个操作不是原子性的,因为 count++ 会被拆分成以下三个步骤执行(这样的步骤不是虚拟的,而是真实情况就是这么执行的)
第一步:读取 count 的值;
第二步:计算 +1 的结果;
第三步:将 +1 的结果赋值给 count变量
那问题又来了。分三步又咋样?让他执行完不就行了?
理论上是这样子的,大家都很友好,你执行完我执行,我执行完你继续。你想象的可能是这样的”乌托邦图“

image-20210430131612018
但是实际上这些线程已经”黑化”了。他们绝不可能互相谦让。CPU或者是程序的世界观里面。大家做任何事情都是在”争抢“。我们来看下面这张图:
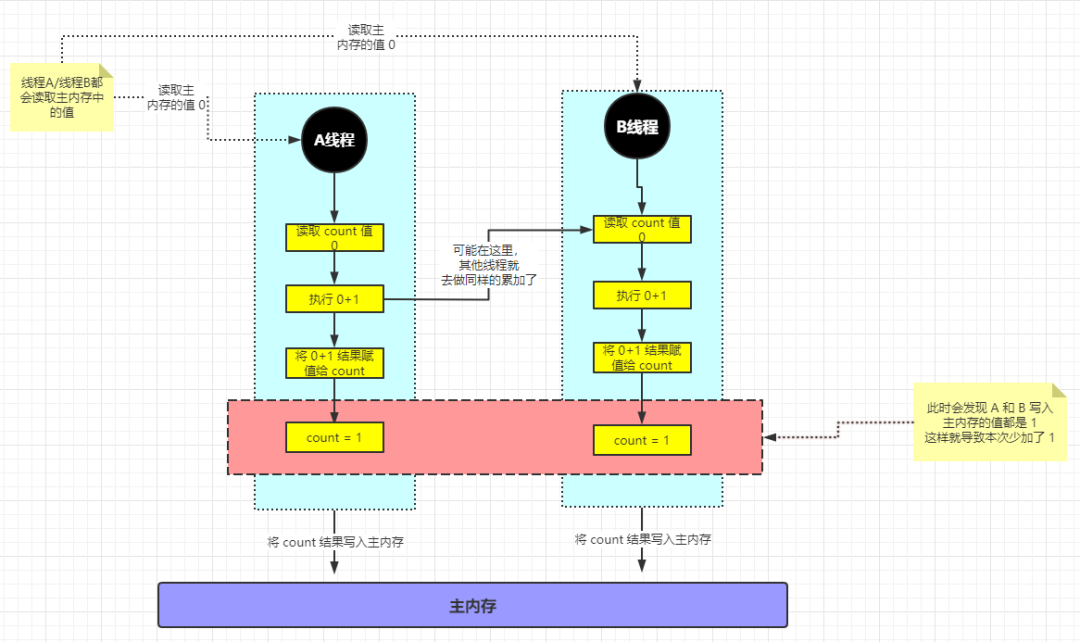
上图详细分析:
第一步:A线程从主内存中读取 count 的值 0;
第二步:A线程开始对 count 值进行累加;
第三步:B线程从主内存中读取 count 的值 0(PS:具体第三步从哪里开始都不是重点,重点是:A线程将 count 值写入主内存之前 B 线程就开始读取 count 并执行。此时 B线程 读取到的 count 值依旧是还未被操作过的原始值);
第四步:(PS:到这里其实已经不重要了。因为不管 A线程和B线程现在怎么操作。结果已经不可逆转,已经错了)B线程开始对 count 值进行累加;
第五步:A 线程将累加后的结果赋值给 count 结果为 1;
第六步:B 线程将累加后的结果赋值给 count 结果为 1;
第七步:A 线程将结果 count =1 刷回到主内存;
第八步:B 线程将结果 count =1 刷回到主内存;
相信大家此时已经非常清晰地分析出了原子性产生的根本原因了。
至于解决方案可以通过锁或者是 CAS 的方式。具体方案就不再这里赘述了。
2、可见性
万丈高楼平地起,再复杂的技术我们也需要从基本的概念看起来:
可见性:一个线程对共享变量的修改,另外一个线程能够立刻看到,我们称为可见性。
2.1、可见性问题产生的原因
在很多年前,那个嫁妆只需要一个手电筒的年代你或许还不会出现可见性这样的问题,因为大家都是单核处理器,不存在并发的情况。
而对于现在“视金钱如粪土”的年代。多核处理器已经是现代超级计算机的基础硬件。高速的CPU处理器和缓慢的内存之前数据的通信成了矛盾。
所以为了解决和缓和这样的情况,每个CPU和线程都有自己的本地缓存,所谓本地缓存即该缓存仅仅对它所在的处理器可见,CPU缓存与内存的数据不容易保证一致。
为了避免这种因为写数据速度不一致而导致 CPU 的性能浪费的情况,处理器通过使用写缓冲区来临时保存待写入主内存的数据。写缓冲区合并对同一内存地址的多次写,并以批处理的方式刷新,也就是说写缓冲区不会立即将数据刷新到主内存中。
缓存不能及时刷新到主内存就是导致可见性问题产生的根本原因。
2.2、案例分析
- public class AtomicDemo {
- private int count = 0;
- public void add() {
- count++;
- }
- public int get() {
- return count;
- }
- public static void main(String[] args) throws InterruptedException {
- CountDownLatch countDownLatch = new CountDownLatch(100);
- AtomicDemo atomicDemo = new AtomicDemo();
- IntStream.rangeClosed(0, 100).forEach(item -> {
- new Thread(() -> {
- IntStream.rangeClosed(1, 100).forEach(i -> {
- atomicDemo.add();
- });
- }).start();
- countDownLatch.countDown();
- });
- countDownLatch.await();
- System.out.println(atomicDemo.get());
- }
- }
“what * *”,怎么和上面代码一样。。。结果就不截图了,必然不是10000。
我们来看下执行的流程图(PS:不要纠结于为什么和上面的不一样,特定问题特定分析。在阐述一种问题的时候,一定会在某些层面上屏蔽另外一种问题的干扰)
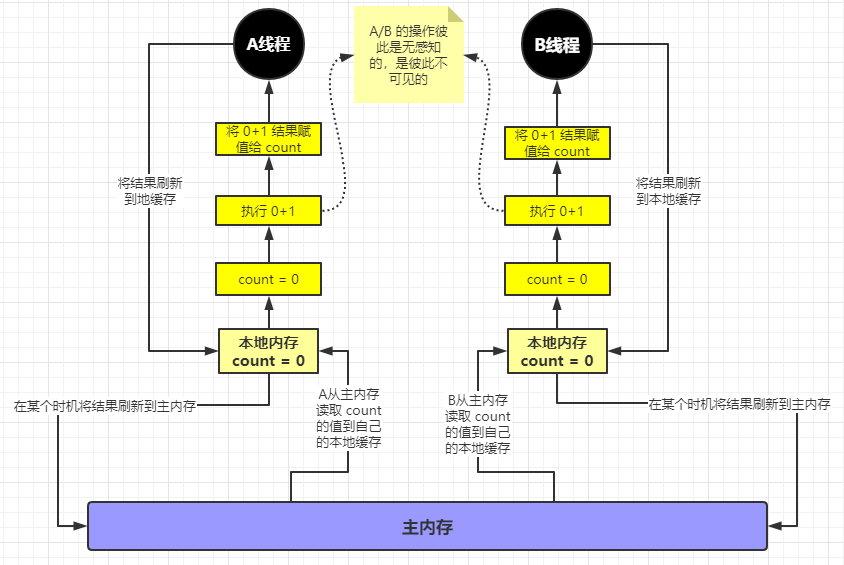
假设 A 线程和 B 线程同时开始执行,首先 A 线程和 B 线程会将主内存中的 count 的值加载/缓存到自己的本地内存中。然后会读取各自的内存中的值去执行操作,也就是说此时 A 线程和 B 线程就好像是两个世界的人,彼此不会产生任何关联。
操作完之后 A 线程将结果写回到自己的本地内存中,同样 B 线程将结果写回到自己的本地内存中。然后回来某个时机各自将结果刷回到主内存。那最终必然是一方的数据被另一方覆盖。这就是缓存的可见性问题。
3、有序性
不积跬步无以至千里,我们还是先来看概念
有序性:程序执行的顺序按照代码的先后顺序执行。
这有啥的,程序老老实实按照程序员写的代码执行就完事了,这还会有什么问题吗?
3.1、有序性问题产生的原因
实际上编译器为了提高程序执行的性能。会改变我们代码的执行顺序的。即你写在前面的代码不一定是先被执行完的。
例如:int a = 1;int b =4;从表面和常规角度来看,程序的执行应该是先初始化 a ,然后初始化 b 。但是实际上非常有可能是先初始化 b,然后初始化 a。因为在编译器看了来,先初始化谁对这两个变量不会有任何影响。即这两个变量之间没有任何的数据依赖。
指令重排序有三种类型,分别为:
① 编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
② 指令级并行的重排序。现代处理器采用了指令级并行技术(Instruction-Level Parallelism,ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应 机器指令的执行顺序。
③ 内存系统的重排序。由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上 去可能是在乱序执行。
3.2、案例分析
有序性的案例最常见的就是 DCL了(double check lock)就是单例模式中的双重检查锁功能。先来看下代码
- public class SingletonDclDemo {
- private SingletonDclDemo(){}
- private static SingletonDclDemo instance;
- public static SingletonDclDemo getInstance(){
- if (Objects.isNull(instance)) {
- synchronized (SingletonDclDemo.class) {
- if (Objects.isNull(instance)) {
- instance = new SingletonDclDemo();
- }
- }
- }
- return instance;
- }
- public static void main(String[] args) {
- IntStream.rangeClosed(0,100).forEach(item->{
- new Thread(SingletonDclDemo::getInstance).start();
- });
- }
- }
这个代码还是比较简单的。
在获取对象实例的方法中,程序首先判断 instance 对象是否为空,如果为空,则锁定SingletonDclDemo.class 并再次检查instance是否为空,如果还为空则创建 Singleton的一个实例。看似很完美,既保证了线程完全的初始化单例,又经过判断 instance 为 null 时再用 synchronized 同步加锁。但是还有问题!
instance = new SingletonDclDemo(); 创建对象的代码,分为三步:① 分配内存空间;② 初始化对象SingletonDclDemo;③ 将内存空间的地址赋值给instance;
但是这三步经过重排之后:① 分配内存空间 ② 将内存空间的地址赋值给instance ③ 初始化对象SingletonDclDemo
会导致什么结果呢?
线程 A 先执行 getInstance() 方法,当执行完指令②时恰好发生了线程切换,切换到了线程B上;如果此时线程B也执行 getInstance() 方法,那么线程B在执行第一个判断时会发现instance!=null,所以直接返回instance,而此时的instance是没有初始化过的,如果我们这个时候访问instance的成员变量就可能触发空指针异常。
继续来张图来更直观的理解下:
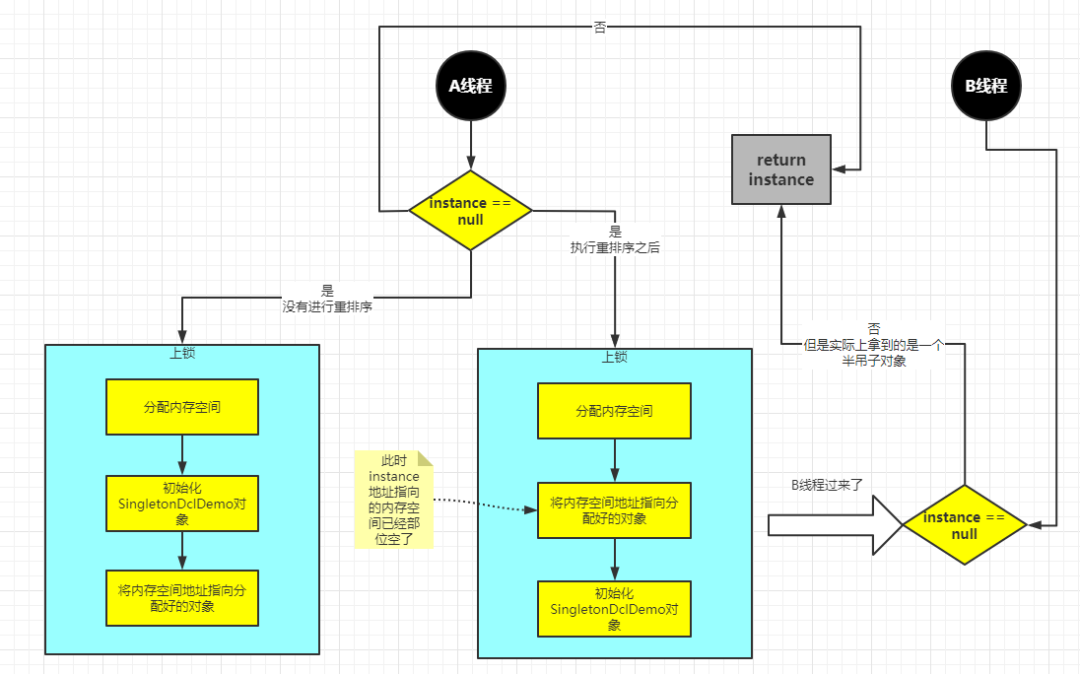
具体的执行流程在上面已经分析了。相信这张图片一定能让你彻底理解。
4、本文小结
并发编程的学习和使用并非一朝一夕的事情,也并非会几个理论就能写好优质的并发程序。这需要长时间的实践和总结。好的代码很少是写出来的,都是迭代和优化的。

















