Part1常见的数据库日志
传统数据库的日志,例如 redo log(重做日志),记录的是修改后的数据。其实就是 MySQL 里经常说到的 WAL 技术,它的关键点就是先写日志,再写磁盘。
- redo log 是 InnoDB 引擎特有的;binlog 是 MySQL 的 Server 层实现的,所有引擎都可以使用。redo log 是物理日志,记录的是“在某个数据页上做了什么修改”;
- binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如“给 ID=2 这一行的 c 字段加 1 ”。redo log 是循环写的,空间固定会用完;
- binlog 是可以追加写入的。“追加写”是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
redis使用AOF(Append Only File),这样做的好处是会在执行命令成功后保存,不需要提前验证命令是否正确。AOF会保存服务器执行的所有写操作到日志文件中,在服务重启以后,会执行这些命令来恢复数据。而 AOF 里记录的是 Redis 收到的每一条命令,这些命令是以文本形式保存的。
etcd会判断命令是否合法,然后Leader 收到提案后,通过 Raft 模块的事件总线保存待发给 Follower 节点的消息和待持久化的日志条目,日志条目是封装的entry。etcdserver 从 Raft 模块获取到以上消息和日志条目后,作为 Leader,它会将 put 提案消息广播给集群各个节点,同时需要把集群 Leader 任期号、投票信息、已提交索引、提案内容持久化到一个 WAL(Write Ahead Log)日志文件中,用于保证集群的一致性、可恢复性。
Part2wal源码分析
etcd server在启动时,会根据是否wal目录来确定之前etcd是否创建过wal,如果没有创建wal,etcd会尝试调用wal.Create方法,创建wal。否则使用wal.Open及wal.ReadAll方法是reload之前的wal,逻辑在etcd/etcdserver/server.go的NewServer方法里,存在wal时会调用restartNode,下面分创建wal和加载wal两种情况作介绍。
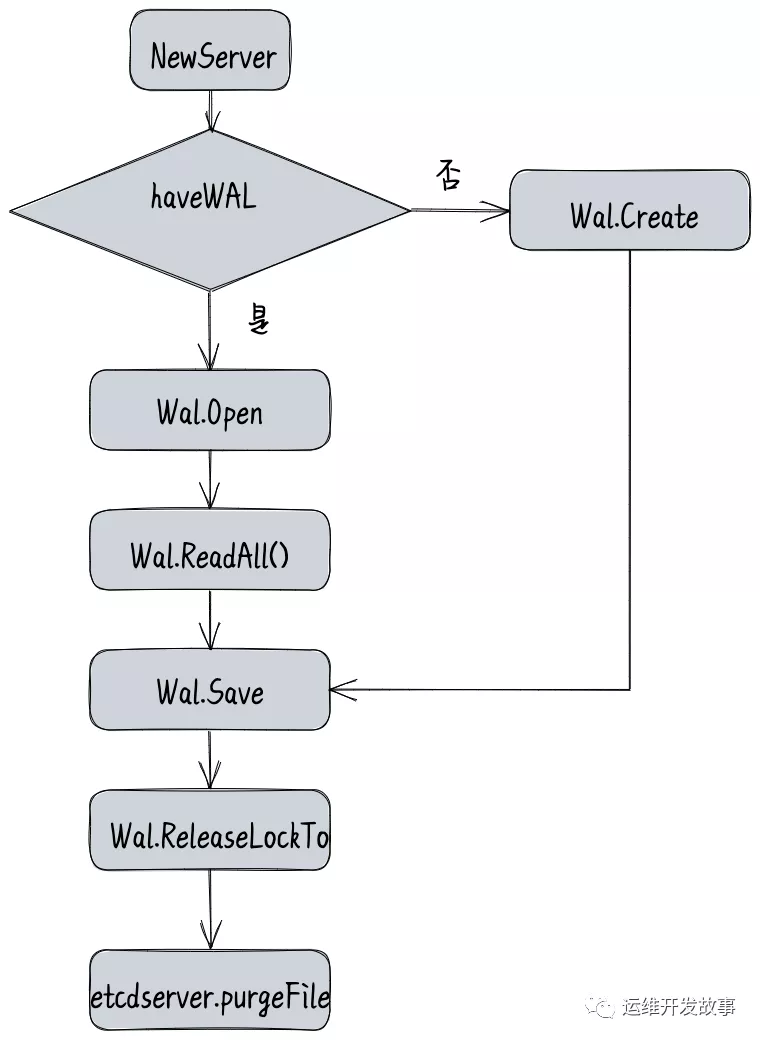
wal的关键对象介绍如下
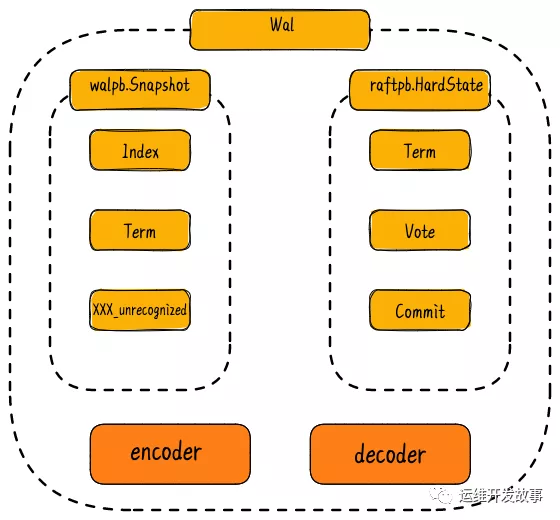
wal日志结构.png
dir:wal文件保存的路径
dirFile:dir打开后的一个目录fd对象
metadata:创建wal时传入的字节序列,etcd里面主要是序列化的是节点id及集群id相关信息,后续每创建一个wal文件就会将其写到wal的首部。
state:wal在append过程中保存的hardState信息,每次raft传出的hardState有变化都会被更新,并会及时刷盘,在wal有切割时会在新的wal头部保存最新的
hardState信息,etcd重启后会读取最后一次保存的hardState用来恢复宕机或机器重启时storage中hardState状态信息,hardState的结构如下:
- type HardState struct {
- Term uint64 `protobuf:"varint,1,opt,name=term" json:"term"`
- Vote uint64 `protobuf:"varint,2,opt,name=vote" json:"vote"`
- Commit uint64 `protobuf:"varint,3,opt,name=commit" json:"commit"`
- XXX_unrecognized []byte `json:"-"`
- }
start:记录最后一次保存的snapshot的元数据信息,主要是snapshot中最后一条日志Entry的index和Term,walpb.Snapshot的结构如:
- type Snapshot struct {
- Index uint64 `protobuf:"varint,1,opt,name=index" json:"index"`
- Term uint64 `protobuf:"varint,2,opt,name=term" json:"term"`
- XXX_unrecognized []byte `json:"-"`
- }
decoder:负责在读取WAL日志文件时,将protobuf反序列化成Record实例。
readClose:用于关闭decoder关联的reader,关闭wal读模式,通过是在readALL之后调用该函数实现的
enti:最后一次保存到wal中的日志Entry的index
encoder:负责将写入WAL日志文件的Record实例进行序列化成protobuf。
size :创建临时文件时预分配空间的大小,默认是 64MB (由wal.SegmentSizeBytes指定,该值也是每个日志文件的大小)。
locks:当前WAL实例管理的所有WAL日志文件对应的句柄。
fp:filePipeline实例负责创建新的临时文件。
WAL创建
先来看一下wal.Create()方法,该方法不仅会创建WAL实例,而是做了很多初始化工作,其大致步骤如下:
(1)创建临时目录,并在临时目录中创建编号为“0-0”的WAL日志文件,WAL日志文件名由两部分组成,一部分是seq(单调递增),另一部分是该日志文件中的第一条日志记录的索引值。
(2)尝试为该WAL日志文件预分配磁盘空间。
(3)向该WAL日志文件中写入一条crcType类型的日志记录、一条metadataType类型的日志记录及一条snapshotType类型的日志记录。
(4)创建WAL实例关联的filePipeline实例。
(5)将临时目录重命名为WAL.dir字段指定的名称。这里之所以先使用临时目录完成初始化操作再将其重命名的方式,主要是为了让整个初始化过程看上去是一个原子操作。这样上层模块只需要检查wal的目录是否存在。
wal.Create()方法的具体实现如下:
- // Create creates a WAL ready for appending records. The given metadata is
- // recorded at the head of each WAL file, and can be retrieved(检索) with ReadAll.
- func Create(dirpath string, metadata []byte) (*WAL, error) {
- // keep temporary wal directory so WAL initialization appears atomic
- //先使用临时目录完成初始化操作再将其重命名的方式,主要是为了让整个初始化过程看上去是一个原子操作。
- tmpdirpath := filepath.Clean(dirpath) + ".tmp"
- if fileutil.Exist(tmpdirpath) {
- if err := os.RemoveAll(tmpdirpath); err != nil {
- return nil, err
- }
- }
- if err := fileutil.CreateDirAll(tmpdirpath); err != nil {
- return nil, err
- }
- // dir/filename ,filename从walName获取 seq-index.wal
- p := filepath.Join(tmpdirpath, walName(0, 0))
- // 创建对文件上互斥锁
- f, err := fileutil.LockFile(p, os.O_WRONLY|os.O_CREATE, fileutil.PrivateFileMode)
- if err != nil {
- return nil, err
- }
- // 定位到文件末尾
- if _, err = f.Seek(0, io.SeekEnd); err != nil {
- return nil, err
- }
- // 预分配文件,大小为SegmentSizeBytes(64MB)
- if err = fileutil.Preallocate(f.File, SegmentSizeBytes, true); err != nil {
- return nil, err
- }
- // 新建WAL结构
- w := &WAL{
- dir: dirpath,
- metadata: metadata,// metadata 可为nil
- }
- // 在这个wal文件上创建一个encoder
- w.encoder, err = newFileEncoder(f.File, 0)
- if err != nil {
- return nil, err
- }
- // 把这个上了互斥锁的文件加入到locks数组中
- w.locks = append(w.locks, f)
- if err = w.saveCrc(0); err != nil {
- return nil, err
- }
- // 将metadataType类型的record记录在wal的header处
- if err = w.encoder.encode(&walpb.Record{Type: metadataType, Data: metadata}); err != nil {
- return nil, err
- }
- // 保存空的snapshot
- if err = w.SaveSnapshot(walpb.Snapshot{}); err != nil {
- return nil, err
- }
- // 之前以.tmp结尾的文件,初始化完成之后重命名
- if w, err = w.renameWal(tmpdirpath); err != nil {
- return nil, err
- }
- // directory was renamed; sync parent dir to persist rename
- pdir, perr := fileutil.OpenDir(filepath.Dir(w.dir))
- if perr != nil {
- return nil, perr
- }
- // 将parent dir 进行同步到磁盘
- if perr = fileutil.Fsync(pdir); perr != nil {
- return nil, perr
- }
- return w, nil
- }
WAL日志文件遵循一定的命名规则,由walName实现,格式为"序号--raft日志索引.wal"。
- // 根据seq和index产生wal文件名
- func walName(seq, index uint64) string {
- return fmt.Sprintf("%016x-%016x.wal", seq, index)
- }
在创建的过程中,Create函数还向WAL日志中写入了两条数据,一条就是记录metadata,一条是记录snapshot,WAL中的数据都是以Record为单位保存的,结构定义如下:
- // 存储在wal稳定存储中的消息一共有两种,这是第一种普通记录的格式
- type Record struct {
- Type int64 `protobuf:"varint,1,opt,name=type" json:"type"`
- Crc uint32 `protobuf:"varint,2,opt,name=crc" json:"crc"`
- Data []byte `protobuf:"bytes,3,opt,name=data" json:"data,omitempty"`
- XXX_unrecognized []byte `json:"-"`
- }
Record类型
其中Type字段表示该Record的类型,取值可以是以下几种:
- const (
- metadataType int64 = iota + 1
- entryType
- stateType
- crcType
- snapshotType
- // warnSyncDuration is the amount of time allotted to an fsync before
- // logging a warning
- warnSyncDuration = time.Second
- )
对应于raft中的Snapshot(应用状态机的Snapshot),WAL中也会记录一些Snapshot的信息(但是它不会记录完整的应用状态机的Snapshot数据),WAL中的Snapshot格式定义如下:
- // 存储在wal中的第二种Record消息,snapshot
- type Snapshot struct {
- Index uint64 `protobuf:"varint,1,opt,name=index" json:"index"`
- Term uint64 `protobuf:"varint,2,opt,name=term" json:"term"`
- XXX_unrecognized []byte `json:"-"`
- }
在保存Snapshot的(注意这里的Snapshot是WAL里的Record类型,不是raft中的应用状态机的Snapshot)SaveSnapshot函数中:
- // 持久化walpb.Snapshot
- func (w *WAL) SaveSnapshot(e walpb.Snapshot) error {
- // pb序列化,此时的e可为空的
- b := pbutil.MustMarshal(&e)
- w.mu.Lock()
- defer w.mu.Unlock()
- // 创建snapshotType类型的record
- rec := &walpb.Record{Type: snapshotType, Data: b}
- // 持久化到wal中
- if err := w.encoder.encode(rec); err != nil {
- return err
- }
- // update enti only when snapshot is ahead of last index
- if w.enti < e.Index {
- // index of the last entry saved to the wal
- // e.Index来自应用状态机的Index
- w.enti = e.Index
- }
- // 同步刷新磁盘
- return w.sync()
- }
一条Record需要先把序列化后才能持久化,这个是通过encode函数完成的(encoder.go),代码如下:
- // 将Record序列化后持久化到WAL文件
- func (e *encoder) encode(rec *walpb.Record) error {
- e.mu.Lock()
- defer e.mu.Unlock()
- e.crc.Write(rec.Data)
- // 生成数据的crc
- rec.Crc = e.crc.Sum32()
- var (
- data []byte
- err error
- n int
- )
- if rec.Size() > len(e.buf) {
- // 如果超过预分配的buf,就使用动态分配
- data, err = rec.Marshal()
- if err != nil {
- return err
- }
- } else {
- // 否则就使用与分配的buf
- n, err = rec.MarshalTo(e.buf)
- if err != nil {
- return err
- }
- data = e.buf[:n]
- }
- lenField, padBytes := encodeFrameSize(len(data))
- // 先写recode编码后的长度
- if err = writeUint64(e.bw, lenField, e.uint64buf); err != nil {
- return err
- }
- if padBytes != 0 {
- // 如果有追加数据(对齐需求)
- data = append(data, make([]byte, padBytes)...)
- }
- // 写recode内容
- _, err = e.bw.Write(data)
- return err
- }
从代码可以看到,一个Record被序列化之后(这里为protobuf格式),会以一个Frame的格式持久化。Frame首先是一个长度字段(encodeFrameSize完成,在encoder.go文件),64bit,56bit存数据。其中MSB表示这个Frame是否有padding字节,接下来才是真正的序列化后的数据。一般一个page是4096字节,对齐到8字节,不会出现一个double被拆到两个page的情况,在cache中,也不会被拆开:
- func encodeFrameSize(dataBytes int) (lenField uint64, padBytes int) {
- lenField = uint64(dataBytes)
- // force 8 byte alignment so length never gets a torn write
- padBytes = (8 - (dataBytes % 8)) % 8
- if padBytes != 0 {
- // lenField的高56记录padding的长度
- lenField |= uint64(0x80|padBytes) << 56 // 最高位为1用于表示含有padding,方便在decode的时候判断
- }
- return lenField, padBytes
- }
最终,下图展示了包含了两个WAL文件的示例图。
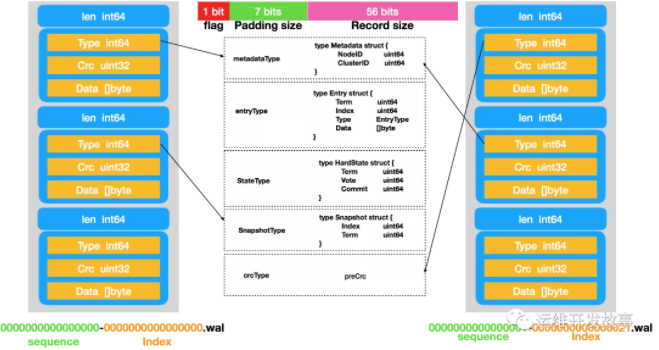
filePipeline类型
filePipeline采用“饿汉式”,即提前创建一些文件备用,这样可以加快文件的创建速度。filePipeline它负责预创建日志文件并为日志文件预分配空间。在filePipeline中会启动一个独立的后台goroutine来创建“.tmp”结尾的临时文件,当进行日志文件切换时,直接将临时文件进行重命名即可使用。结构体filePipeline中各个字段的含义如下。
dir(string类型):存放临时文件的目录。
size (int64 类型):创建临时文件时预分配空间的大小,默认是 64MB (由wal.SegmentSizeBytes指定,该值也是每个日志文件的大小)。
count(int类型):当前filePipeline实例创建的临时文件数。
filec(chan*fileutil.LockedFile 类型):新建的临时文件句柄会通过 filec 通道返回给WAL实例使用。
errc(chan error类型):当创建临时文件出现异常时,则将异常传递到errc通道中。
donec(chan struct{}类型):当filePipeline.Close()被调用时会关闭donec通道,从而通知filePipeline实例删除最后一次创建的临时文件。
在newFilePipeline()方法中,除了创建filePipeline实例,还会启动一个后台goroutine来执行filePipeline.run()方法,该后台goroutine中会创建新的临时文件并将其句柄传递到filec通道中。filePipeline.run()方法的具体实现如下:
- // filePipeline pipelines allocating disk space
- type filePipeline struct {
- // dir to put files
- dir string
- // size of files to make, in bytes
- size int64
- // count number of files generated
- count int
- filec chan *fileutil.LockedFile
- errc chan error
- donec chan struct{}
- }
- func newFilePipeline(dir string, fileSize int64) *filePipeline {
- fp := &filePipeline{
- dir: dir,
- size: fileSize,
- filec: make(chan *fileutil.LockedFile),
- errc: make(chan error, 1),
- donec: make(chan struct{}),
- }
- // 一直执行预分配
- go fp.run()
- return fp
- }
- // Open returns a fresh file for writing. Rename the file before calling
- // Open again or there will be file collisions.
- func (fp *filePipeline) Open() (f *fileutil.LockedFile, err error) {
- select {
- case f = <-fp.filec: // 从filec通道中获取文件描述符,并返回
- case err = <-fp.errc: // 如果创建失败,从errc通道中获取,并返回
- }
- return f, err
- }
- func (fp *filePipeline) Close() error {
- close(fp.donec)
- return <-fp.errc //出现错误,关闭donec通道并向errc通到中发送错误
- }
- func (fp *filePipeline) alloc() (f *fileutil.LockedFile, err error) {
- // count % 2 so this file isn't the same as the one last published
- // 创建临时文件的编号是0或者1。
- fpath := filepath.Join(fp.dir, fmt.Sprintf("%d.tmp", fp.count%2))
- //创建临时文件,注意文件的模式与权限。
- if f, err = fileutil.LockFile(fpath, os.O_CREATE|os.O_WRONLY, fileutil.PrivateFileMode); err != nil {
- return nil, err
- }
- // 尝试预分配,如果当前文件系统不支持预分配空间,则不会报错。
- if err = fileutil.Preallocate(f.File, fp.size, true); err != nil {
- f.Close() //如果出现异常,则会关闭donec通道
- return nil, err
- }
- // 已经分配的文件个数
- fp.count++
- return f, nil //返回创建的临时文件
- }
- // goroutine
- func (fp *filePipeline) run() {
- defer close(fp.errc)
- for {
- // 调用alloc()执行创建临时文件
- f, err := fp.alloc()
- if err != nil {
- fp.errc <- err
- return
- }
- select {
- case fp.filec <- f: // 等待消费方从这个channel中取出这个预创建的被锁的文件
- case <-fp.donec: //关闭时触发,删除最后一次创建的临时文件
- os.Remove(f.Name())
- f.Close()
- return
- }
- }
- }
本文转载自微信公众号「 运维开发故事」,可以通过以下二维码关注。转载本文请联系 运维开发故事公众号。