数据在机器学习中扮演着重要角色。在推荐系统的研究中,对用户建模来说,用户行为和附带信息都非常有帮助。因此,大规模真实场景下的用户丰富行为是非常有用的数据。但是,这些数据很难获取,因为这种数据大部分都被公司拥有并且保护起来。
本文中,知乎联合清华大学对外开放基于知乎的大规模富文本查询和推荐数据集ZhihuRec。该数据集中的曝光数接近 1 亿,并具有目前为止最丰富的上下文信息,覆盖 10 天、79.8 万用户、16.5 万个问题、55.4 万个回答、24 万个作者、7 万话题以及 50.1 万用户搜索行为日志。它可以被用于各种推荐方法,如协同过滤、基于内容的推荐、基于序列的推荐、知识增强的推荐和混合推荐等。此外,由于 ZhihuRec 数据集中信息丰富,不仅可以将它应用于推荐研究,还可以将它应用于用户建模(如性别预测、用户兴趣预测)、跨平台应用(查询平台和推荐平台)等有趣的课题。据了解,这是用于个性化推荐的最大的实际交互数据集。
总结来说 ZhihuRec 数据集主要具有三个优点:
- ZhihuRec 是最大的公共推荐数据集,包含从知乎收集的各种用户交互,该数据集是开源的。
- ZhihuRec 数据集提供了丰富的内容信息,包括问题、回答、个人资料、话题。特别是用户的搜索日志也会显示出来,这些以前没有包含过。
- 除 top-N 推荐、上下文感知推荐等推荐研究外,ZhihuRec 还可用于各种研究领域,例如用户建模、集成搜索和推荐研究。

- 论文地址:https://arxiv.org/pdf/2106.06467.pdf
- 数据集地址:https://github.com/THUIR/ZhihuRec-Dataset
数据集简介
下表 1 展示了 ZhihuRec 与其他一些经典推荐数据集之间的差异,结果表明,ZhihuRec 数据集比传统推荐数据集包含更多的信息和类型,如文本、用户画像、物品属性、时间戳等。
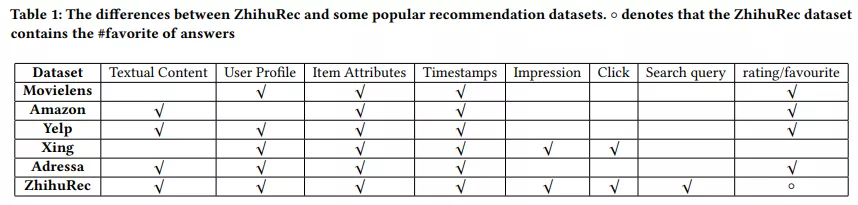
表格中 O 表示 ZhihuRec 数据集中虽然没有记录用户具体的评分 / 收藏行为,但是记录了用户的收藏回答总量。
下图给出了 ZhihuRec 数据集的构建过程,可以看出数据集包含的上下文信息有用户对回答的点击和浏览行为日志、用户查询词记录、用户画像信息、答案属性信息、问题属性信息、作者画像信息和话题属性等各类信息,以及每个用户最多 20 个最近查询关键词。
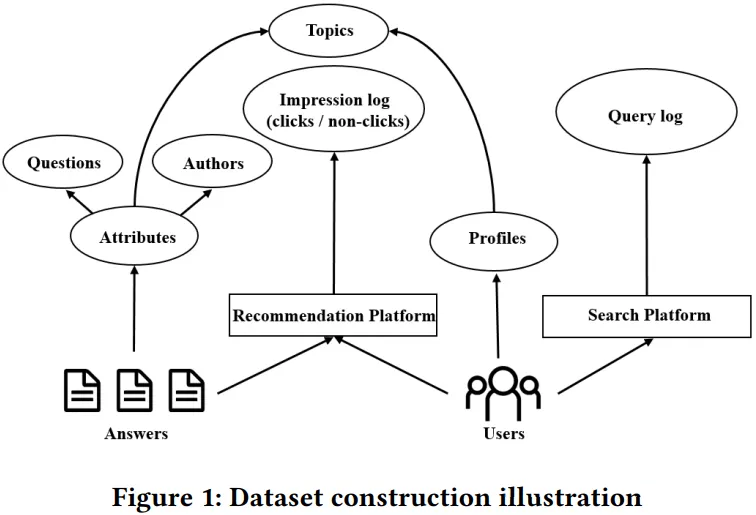
表 2 显示了 ZhihuRec 中每个印象记录的字段及其说明。根据答案的读取时间,所有用户的点击和未点击的印象都记录在数据集中。
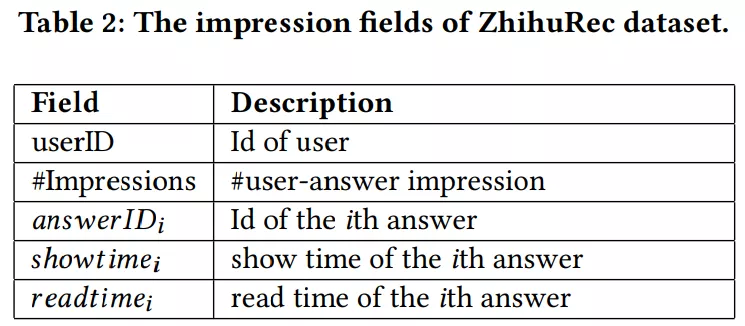
表 3 显示了 ZhihuRec 数据集中的每个搜索记录的字段及其说明。所有用户的搜索关键字和时间戳都记录在数据集中。

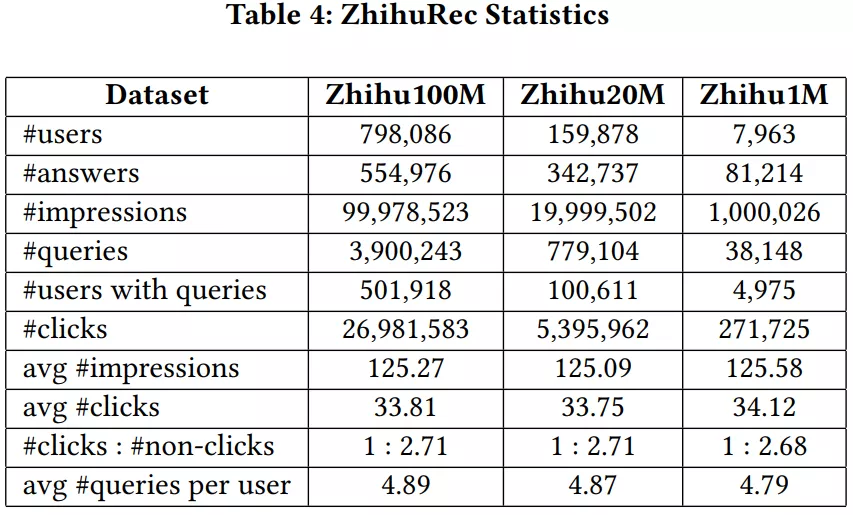
由于 ZhihuRec 数据集包含约 1 亿个用户 - 答案交互,因此也称为 Zhihu100M。此外,还构造了两个从 Zhihu100M 数据集中随机抽取的较小数据集,称为 Zhihu20M 和 Zhihu1M,以满足各种应用需求。它们包含大约 2000 万和 1M 的用户答案日志,可以将其视为中等大小的数据集和相对较小的数据集。表 4 中显示了它们的一些统计信息。
用户画像和属性都记录在 ZhihuRec 中。该数据集保留用户、问题、回答和作者的内容信息。表 5 显示了用户的属性,表 6 显示了回答的属性,表 7 显示了问题的属性,表 8 显示了作者的属性。
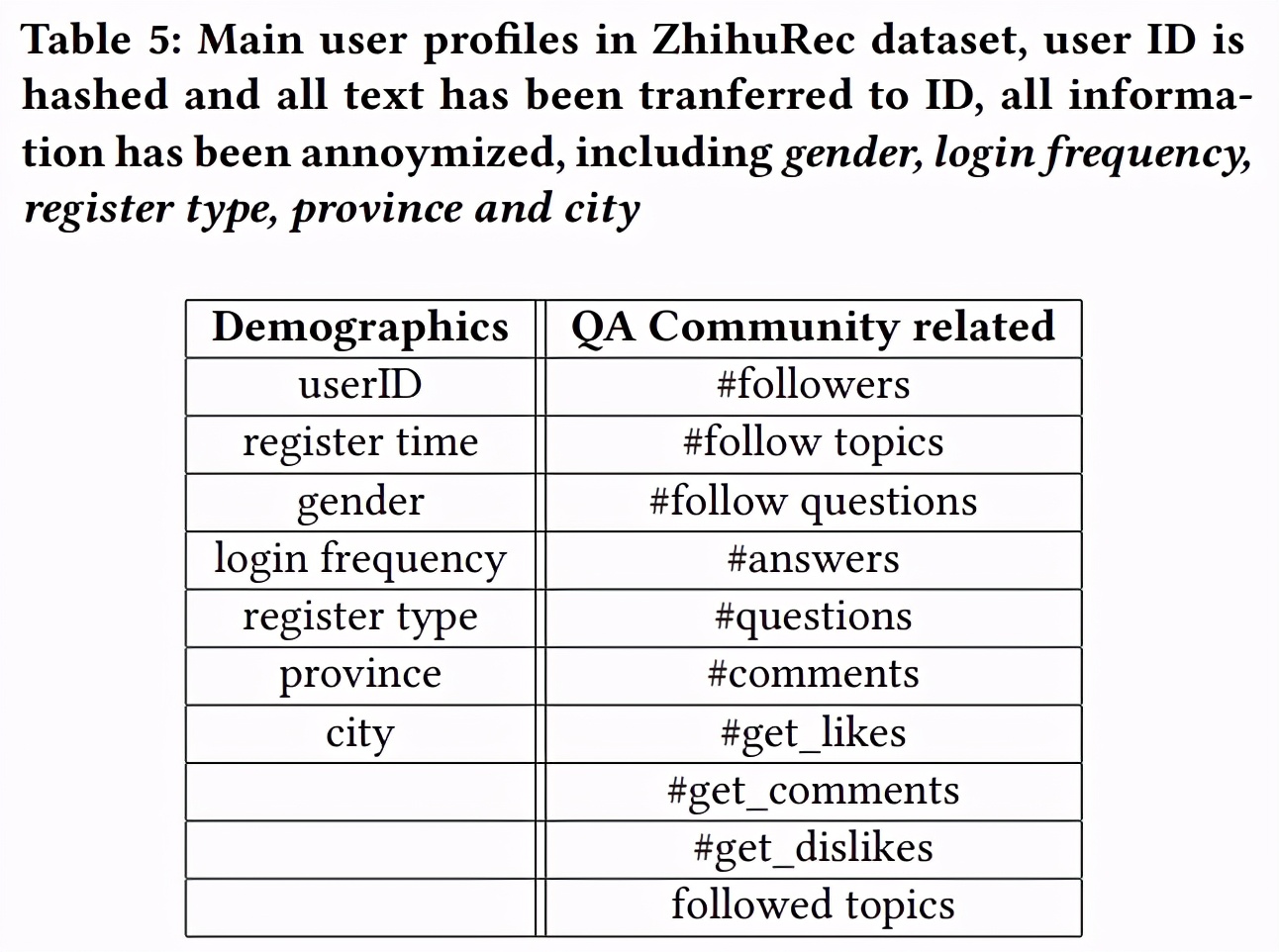
用户的属性。
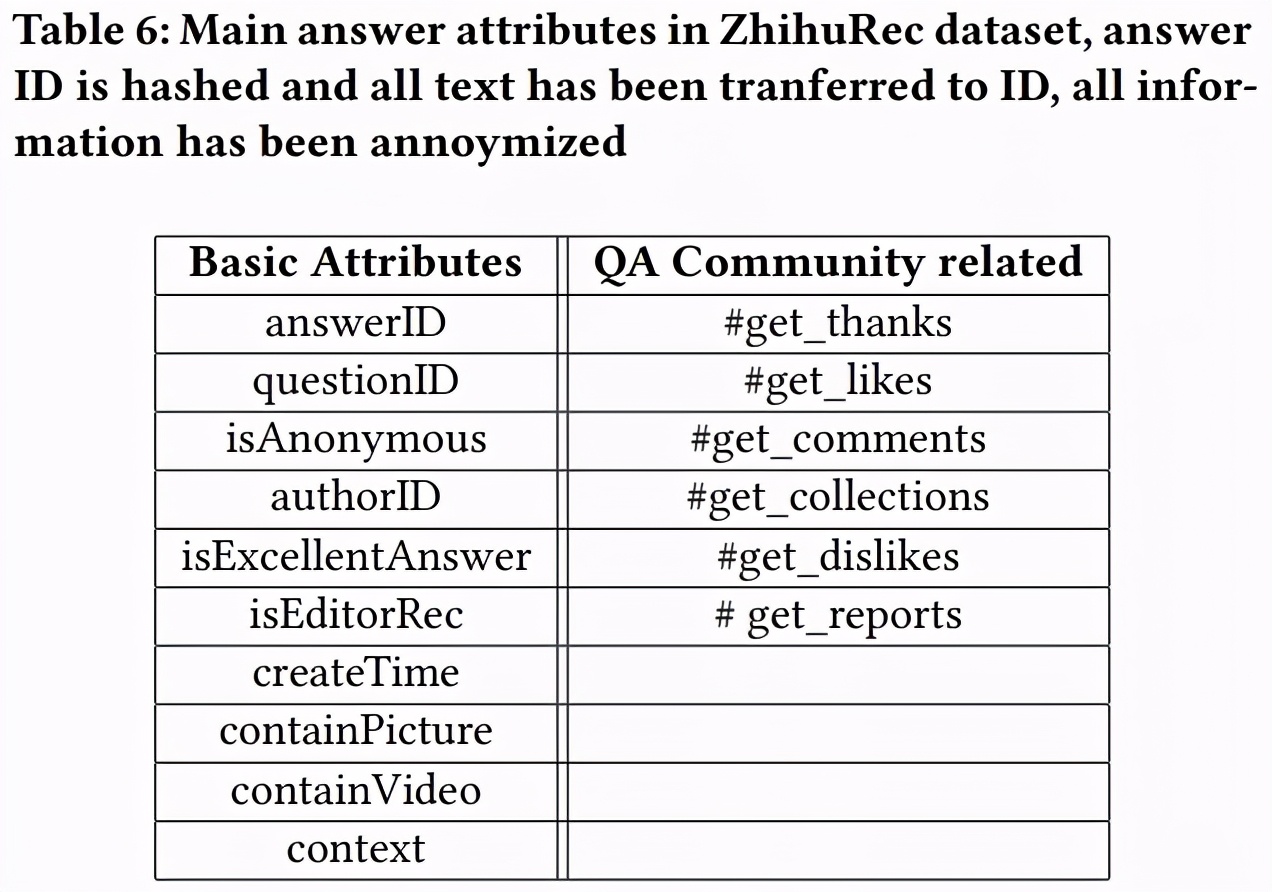
回答的属性。

问题的属性。

作者的属性。
如表中所示,关于用户、问题、回答和作者的功能十分丰富,可以对用户和内容(回答)进行全面建模。问题属性中没有 authorID,原因是随着时间的推移,许多人可以修改知乎问答社区中的问题。
请注意,authorID 与 userID 是不同的,这意味着如果一个人在数据集中同时扮演用户和作者的角色,则其 authorID 和 userID 是不同的,因为发布者和阅读者是不同的角色。
每个用户或问题还具有几个话题(从 0 到 70,308),由用户本人(用户话题)或系统用户(问题话题,所有用户都可以对其进行编辑)标记。它提供了一种更明确的方式来帮助了解用户的兴趣和问题的类型,这对于推荐也很有用。每个话题都有一个话题 ID 和话题描述作为其属性,话题 ID 进行了散列处理,并且话题描述中的所有上下文都已转换为数字编号。
数据集隐私保护
由于整个数据集都是从真实场景中的真实用户那里收集的,因此有必要保护用户隐私。因此,并非用户的所有内容信息都被释放。
ZhihuRec 数据集中的所有 ID 均被匿名和散列处理。所有文本信息(例如问题的标题、回答的内容、话题的描述和搜索关键字)均被分解为单词,并且所有单词均被数字替换。用户画像中的所有文本功能(例如性别、注册类型、登录频率、省、城市)也都已转换为数字号码。因此,无法从 ZhihuRec 数据集中获取用户个人资料和内容属性的详细信息。
ZhihuRec 数据集删除了用户的出生日期、工作经历、教育经历等敏感信息。用户的网络信息 (如 IP 地址) 也已被删除。用户对回答的显式反馈如赞同、感谢、收藏、评论、反对和举报等都被隐藏,ZhihuRec 数据集只保存了相关的总的统计量,如用户总的赞同数、收藏数、评论数、反对数和举报数等。
数据集统计特性
图 2 显示了用户注册时间的分布;可以发现,随着时间的推移,每月注册用户的数量逐渐增加。
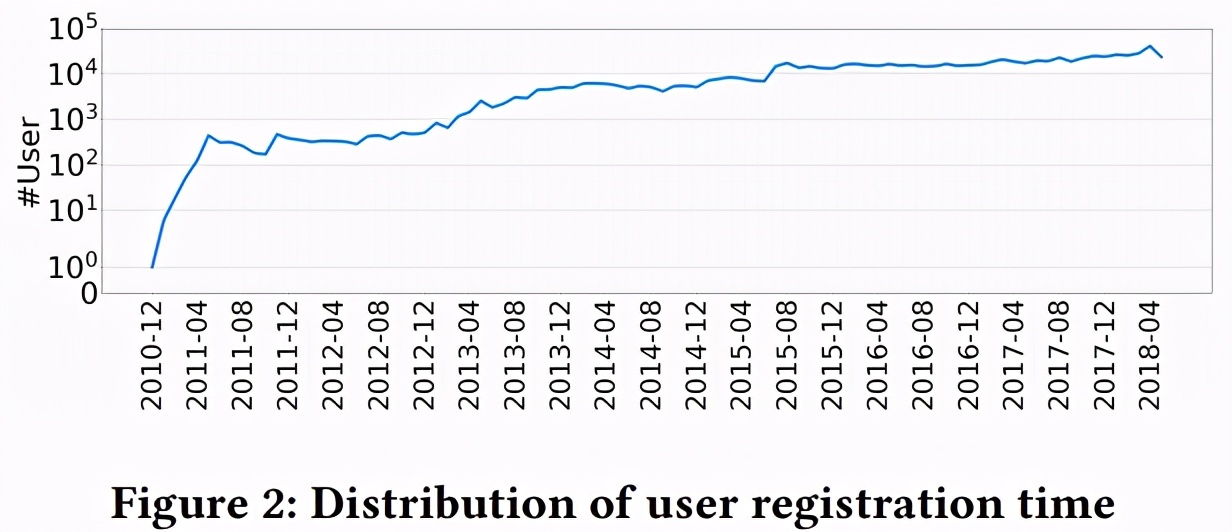
图 3 显示了每个话题的用户分布数:
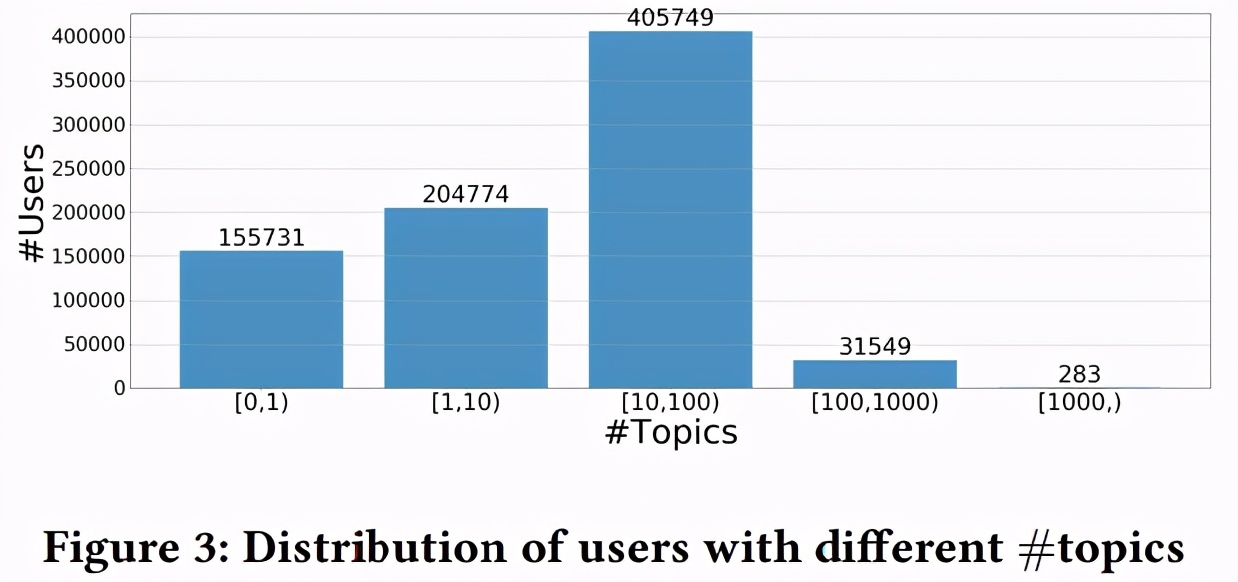
图 4 显示了每个话题下的问题分布数:
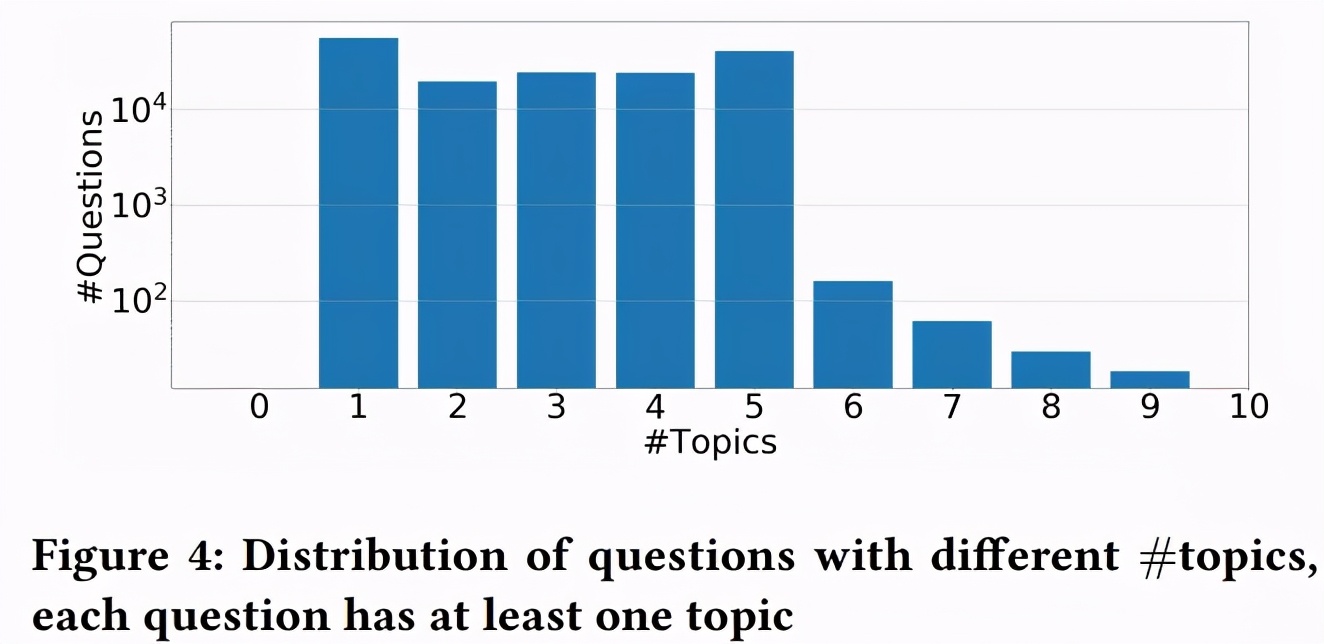
图 5 显示了每个话题下的回答分布数。它显示大多数用户关注的话题少于 100 个,大多数回答和问题绑定不止一个话题。
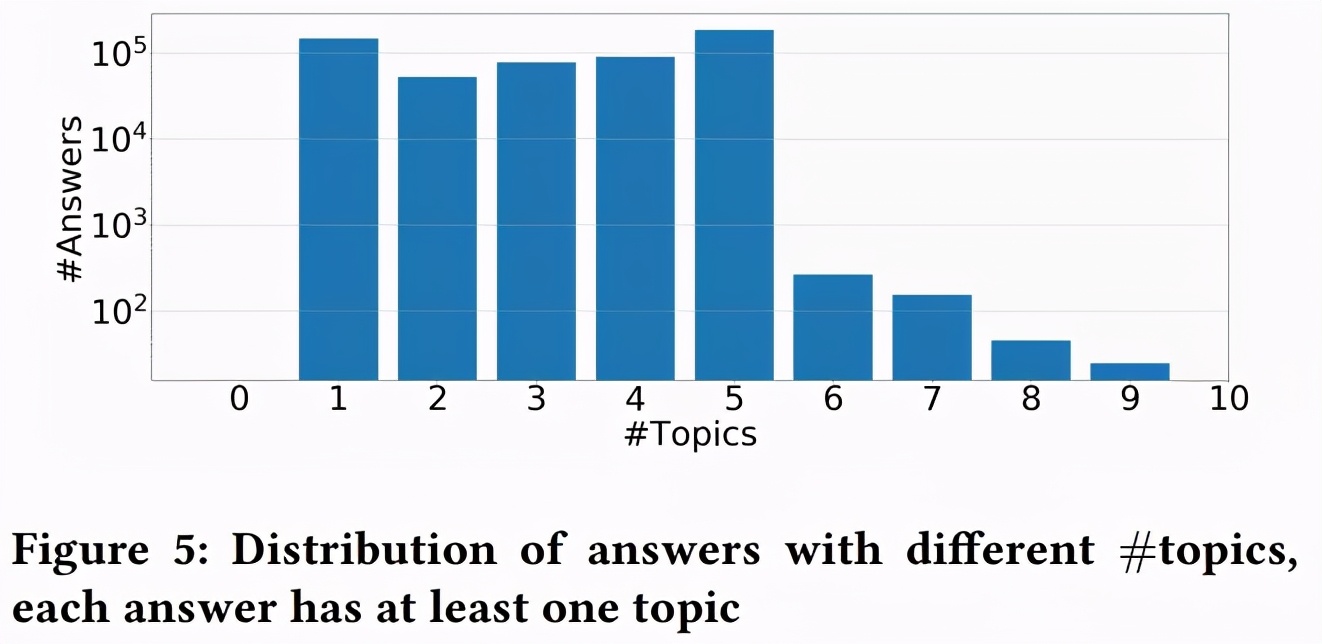
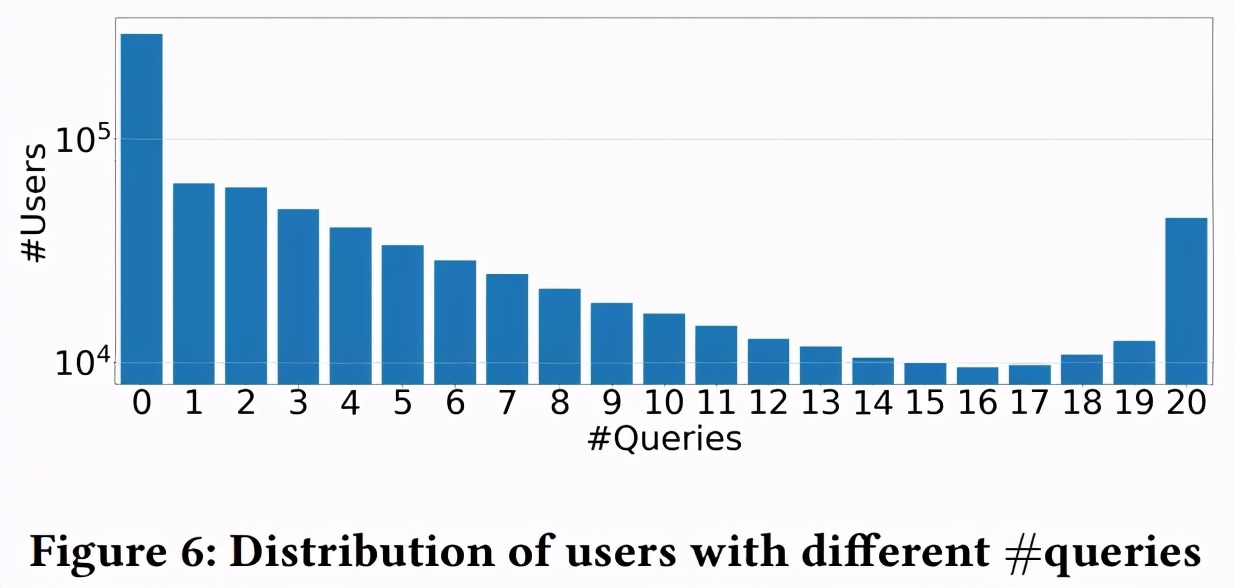
图 6 显示了 ZhihuRec 数据集中每个搜索的用户分布数量。大多数用户的搜索少于 3 个,并且分布显示出类似对数的衰减。但是,有许多用户有 20 个搜索,原因是研究者在此处进行了截断(最多将保留该用户的 20 个最近搜索关键字)。
数据集在多项推荐任务中的应用
topN 推荐
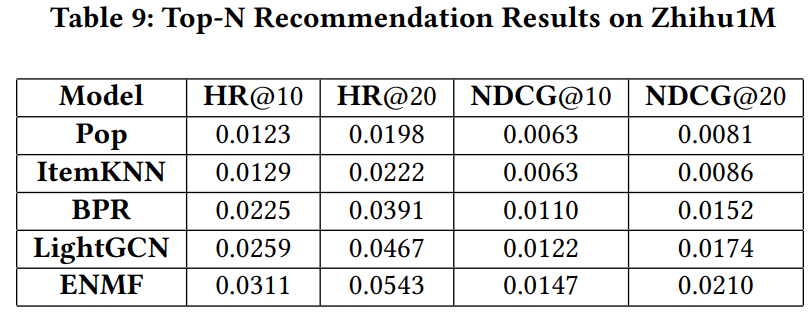
用户的交互日志包含在 ZhihuRec 数据集中;从推荐系统的角度来看,可以将用户在日志中交互的回答视为商品。该信息适用于协同过滤,其中包含通用的 topN 推荐的主要方法。为了评估 ZhihuRec 数据集的性能,在 Zhihu1M 数据集中应用了 5 种推荐算法。
- Pop:此基准始终会推荐训练集中最受欢迎的回答(用户点击)。
- ItemKNN:此方法选择前 K 个最近邻,并使用其信息进行预测。
- BPR:此方法应用贝叶斯个性化排名目标函数来优化矩阵分解。
- LightGCN:此方法使用图卷积网络来增强协同过滤的性能。
- ENMF:使用高效神经矩阵分解的非采样神经网络推荐模型。
实验已使用 RecBole 完成。对于所有方法,用户和回答的 embedding 大小为 64。ItemKNN 的邻居数为 100。采用留一法(Leave-one-out)。实验结果如表 9 所示:
序列推荐
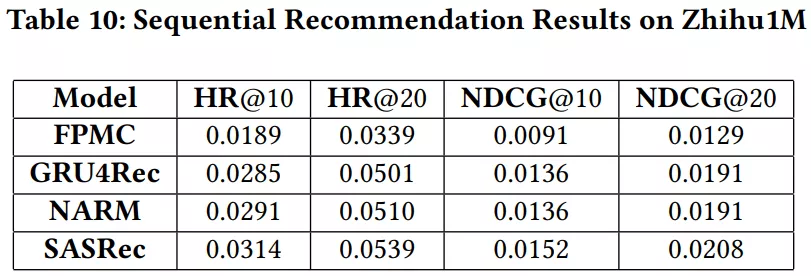
序列推荐在改善许多推荐任务的性能方面起着重要作用,因为它们可以揭示用户的动态偏好,这也是前 N 个推荐。通常,序列推荐与传统推荐之间的区别在于序列推荐需要清晰的时间信息。它使用用户交互的商品序列作为输入,并根据交互时间戳对商品进行排序。推荐系统中对商品的展示也有排序。由于所有用户的交互都记录在 ZhihuRec 数据集中,因此本文已在 Zhihu1M 数据集中应用了四个最新的序列模型(FPMC 、GRU4Rec、NARM 、SASRec)。
- FPMC:此方法基于基础马尔可夫链上的个性化过渡图,并结合了 MF。
- GRU4Rec:基于会话的模型,使用 RNN 捕获序列依赖关系并进行预测。
- NARM:此方法使用具有注意力机制的混合编码器来捕获用户的意图。
- SASRec:采用自注意力层来捕获动态用户交互序列的顺序模型。
实验已使用 RecBole 完成。对于所有方法,用户和回答的 embedding 大小为 64。使用留一法。实验结果如表 10 所示:
上下文感知推荐
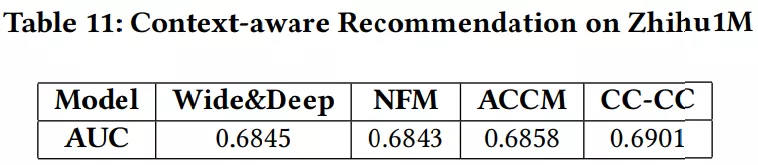
上下文感知推荐模型使用来自用户、商品和上下文来增强模型性能。上下文感知推荐结合了不同推荐模型的优势,例如协同过滤,基于内容的模型以获得更好的推荐;该数据集非常适合上下文感知推荐。如点击预测任务中通常描述的那样,一个用户点击一个回答的交互标记为 1,而该用户有被展示但不点击一个回答的交互标记为 0。本文在 Zhihu1M 数据集中应用了 4 个最新的上下文感知模型。
- Wide&Deep :由 Google 提出,它结合了深度神经网络和线性模型,并广泛用于实际场景中。
- NFM :使用双向交互层对二阶特征交互进行建模的神经模型。
- ACCM:这是一个注意力协同和内容模型,它将内容和用户交互结合在一起。
- CC-CC:此方法使用自适应 “特征采样” 策略。
实验已使用 CC-CC 工具箱完成。所有方法的用户和回答的 embedding 大小为 64。对于每个用户,最后一次点击和最后一次点击之后的展示均被视为测试集,最后一次点击之前的点击以及最后一次点击之前的点击和最后一次点击之间发生的展示被视为验证集,其他被视为训练集。实验结果如表 11 所示:
跨场景推荐
如上所述,用户的搜索关键字也包含在 ZhihuRec 数据集中;搜索使用的关键词可以视为其明确的需求信息。虽然以前的推荐系统的研究主要集中于从用户的隐式反馈中学习,但如果更多的研究人员尝试整合搜索和推荐,将很有帮助,这将有助于更好地了解用户的信息需求并提供更好的信息服务。该数据集由于其丰富的搜索和推荐日志可以应用于此类研究。
基于负反馈的推荐
当用户与回答进行交互时,他们会给答案以正反馈和负反馈。正面反馈是指用户对回答进行点击、收藏、点赞等。负反馈则是用户删除、跳过回答等。传统的推荐数据集存在缺乏负反馈问题。ZhihuRec 数据集同时记录了用户的正反馈和负反馈。利用用户的负向偏好可以提高推荐质量,该数据集适用于基于负反馈的推荐模型。
由于 ZhihuRec 数据集具备了丰富的上下文信息,它还可以被用在推荐之外的任务上,例如识别最有价值的回答者、识别优质回答等。
结论
本文介绍了来自在线知识共享社区的一个新数据集,旨在为个性化推荐做出贡献。据了解,这是一个包含详细信息的最大的公开数据集,包括用户、内容、行为、作者、话题以及包含搜索和对推荐结果是否点击的用户交互日志。该研究呈现了有关最新算法在该数据集上的实验结果。该数据集可用于以下方面的研究:上下文感知推荐、序列推荐、利用负反馈的推荐、集成搜索和推荐以及用户画像和内容属性的建模。该数据集是公开可用的,并且在交互日志和搜索关键字中包含大量信息,适合跨平台研究。