













【51CTO.com快译】深度神经网络因其具有的处理视觉信息的强大能力而闻名。在过去几年中,它们已成为许多计算机视觉应用程序的关键组成部分。
神经网络可以解决的关键问题之一是检测和定位图像中的对象。对象检测用于许多不同的领域,其中包括自动驾驶、视频监控、医疗保健等。

以下简要回顾帮助计算机检测对象的深度学习架构:
卷积神经网络(CNN)
卷积神经网络(CNN)是基于深度学习的计算机视觉应用的一个关键组成部分。卷积神经网络(CNN) 是由深度学习技术先驱Yann LeCun在上世纪80年代开发的一种神经网络,可以有效捕捉多维空间中的模式。这使得卷积神经网络(CNN)特别适用于检测图像,尽管它们也用于处理其他类型的数据。为了更简单地叙述,在本文中考虑的卷积神经网络是二维的。
每个卷积神经网络都由一个或多个卷积层组成,这是一个从输入图像中提取有意义值的软件组件。每个卷积层都由多个过滤器和矩阵组成,这些过滤器和矩阵在图像上滑动,并在不同位置注册像素值的加权和。每个过滤器具有不同的值,并从输入图像中提取不同的特征。而卷积层的输出是一组“特征图”。
当堆叠在一起时,卷积层可以检测视觉模式的层次结构。例如,较低层将为垂直和水平边、角和其他简单模式生成特征图。较高的层可以检测复杂的图案,例如网格和圆形。而最高层可以检测更复杂的对象,例如汽车、房屋、树木和人员。


神经网络的每一层都对输入图像中的特定特征进行编码。
大多数卷积神经网络使用池化层来逐渐减小其特征图的大小,并保留最突出的部分。最大池化(Max-pooling)是目前卷积神经网络(CNN)中使用的主要池化层类型,它保持像素块中的最大值。例如,如果使用大小为2像素的池化层,它将从前一层生成的特征图中提取2×2像素的块并保留最大值。这一操作将其特征图的大小减半,并保留最相关的特征。池化层使卷积神经网络(CNN)能够泛化其能力,并且对跨图像的对象位移不那么敏感。
最后,卷积层的输出被展平为一个一维矩阵,该矩阵是图像中包含的特征的数值表示。然后将该矩阵输入到一系列“完全连接”的人工神经元层中,这些层将特征映射到网络预期的输出类型。

卷积神经网络(CNN)的架构
卷积神经网络最基本的任务是图像分类,其中网络将图像作为输入并返回一系列值,这些值表示图像属于多个类别之一的概率。例如,假设你要训练一个神经网络来检测流行的开源数据集ImageNet中包含的所有1,000类对象。在这种情况下,输出层将有1,000个数字输出,每个输出都包含图像属于这些类别之一的概率。
你可以从头开始创建和测试自己的卷积神经网络。但大多数机器学习研究人员和开发人员使用几种主流的卷积神经网络,例如AlexNet、VGG16和ResNet-50。
对象检测数据集
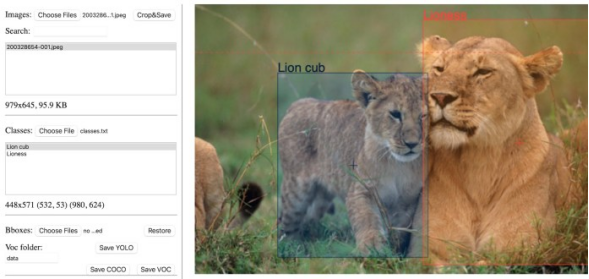
对象检测网络需要在精确标注的图像上进行训练
虽然图像分类网络可以判断图像是否包含某个对象,但它不会说明对象在图像中的位置。对象检测网络提供图像中包含的对象类别,并提供该对象坐标的边界框。
对象检测网络与图像分类网络非常相似,并使用卷积层来检测视觉特征。事实上,大多数对象检测网络使用图像分类的卷积神经网络(CNN)并将其重新用于对象检测。
对象检测是一个有监督的机器学习问题,这意味着必须在标记的示例上训练模型。训练数据集中的每张图像都必须附有一个文件,其中包含其包含的对象的边界和类别。有几个开源工具可以创建对象检测注释。
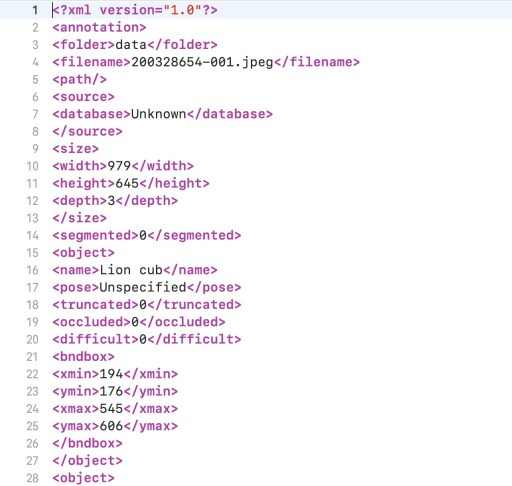
对象检测训练数据的注释文件示例
对象检测网络在注释数据上进行训练,直到它可以在图像中找到与每种对象对应的区域。
以下了解一些对象检测神经网络架构。
R-CNN深度学习模型

R-CNN架构
基于区域的卷积神经网络(R-CNN)由加州大学伯克利分校的人工智能研究人员于2014年提出。R-CNN由三个关键组件组成:
首先,区域选择器使用“选择性搜索”算法,在图像中查找可能代表对象的像素区域,也称为“感兴趣区域”(RoI)。区域选择器为每个图像生成大约2,000个感兴趣区域(RoI)。
其次,感兴趣区域(RoI)被压缩成预定义的大小,并传递给卷积神经网络。卷积神经网络(CNN)对每个区域进行处理,通过一系列卷积操作分别提取特征,卷积神经网络(CNN)使用全连接层将特征图编码为一维数值向量。
最后,分类器机器学习模型将从卷积神经网络(CNN)获得的编码特征映射到输出类。分类器有一个单独的“背景”输出类,它对应于任何不是对象的东西。

使用R-CNN进行对象检测
最初有关R-CNN的一篇论文建议研究人员使用AlexNet卷积神经网络进行特征提取,并使用支持向量机(SVM)进行分类。但在这篇论文发表后的几年后,研究人员使用更新的网络架构和分类模型来提高R-CNN的性能。
R-CNN存在一些问题。首先,模型必须为每张图像生成和裁剪2,000个单独的区域,这可能需要很长时间。其次,模型必须分别计算2,000个区域的特征。这需要大量计算并减慢了过程,使得R-CNN不适合实时对象检测。最后,该模型由三个独立的组件组成,这使得集成计算和提高速度变得困难。
Fast R-CNN

Fast R-CNN架构
2015年,这篇R-CNN论文的第一作者提出了一种名为Fast R-CNN的新架构,解决了其前身的一些问题。FastR-CNN将特征提取和区域选择集成到单个机器学习模型中。
Fast R-CNN接收图像和一组感兴趣区域(RoI),并返回图像中检测到的对象的边界框和类的列表。
Fast R-CNN的关键创新之一是“RoI池化层”,该操作采用卷积神经网络(CNN)特征图和图像的感兴趣区域,并为每个区域提供相应的特征。这使得Fast R-CNN能够在一次性提取图像中所有感兴趣区域的特征,而R-CNN则分别处理每个区域。这显著提高了处理速度。
然而还有一个问题仍未解决。Fast R-CNN仍然需要提取图像区域并将其作为输入提供给模型。FastR-CNN还没有准备好进行实时对象检测。
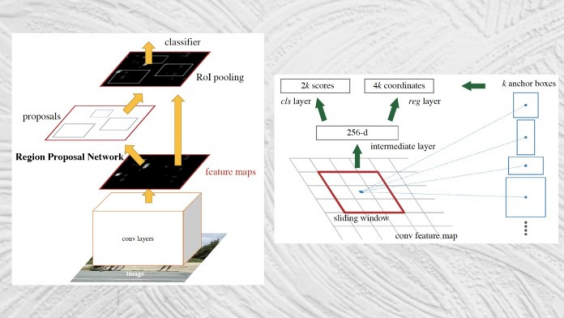
Faster R-CNN

Faster R-CNN架构
Faster R-CNN于2016年推出,通过将区域提取机制集成到对象检测网络中,解决了对象检测最后的难题。
Faster R-CNN将图像作为输入,并返回对象类及其相应边界框的列表。
Faster R-CNN的架构在很大程度上类似于FastR-CNN的架构。它的主要创新是“区域提议网络”(RPN),该组件采用卷积神经网络生成的特征图,并提出一组可能定位对象的边界框。然后将提议的区域传递给RoI池化层。其余的过程类似于Fast R-CNN。
通过将区域检测集成到主要的神经网络架构中,Faster R-CNN实现了接近实时的目标检测速度。
YOLO

YOLO架构
2016年,华盛顿大学、艾伦人工智能研究所和Facebook人工智能研究所的研究人员推出了“YOLO”,这是一个神经网络家族,通过深度学习提高了对象检测的速度和准确性。
YOLO的主要改进是将整个对象检测和分类过程集成在一个网络中。YOLO不是分别提取特征和区域,而是通过一个个网络在一次传递中执行所有操作,因此被称之为“你只看一次” (YOLO)。
YOLO能够以视频流帧率执行对象检测,适用于需要实时推理的应用程序。
在过去的几年中,深度学习对象检测取得了长足的进步,从一个由不同组件拼凑而成的单一神经网络发展成为功能强大并且更加高效的神经网络。如今,许多应用程序使用对象检测网络作为其主要组件,这一技术存在于人们的手机、计算机、相机、汽车等设备中。而人们如果了解更加先进的神经网络能够实现什么功能,这将是有趣的事情,可能也会令人毛骨悚然。
原文标题:An introduction to object detection with deep learning,作者:Ben Dickson
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】




















