













我在 Shopee 维护一个 Service Mesh 系统,大部分的 RPC 调用要经过这个系统,这个系统每分钟要处理上千万的请求。我们在本文中就把它叫做 Oitsi 系统吧,方便描述一些。干的事情其实和 Istio 是差不多的。
Oitsi 将对 RPC 调用设置了很多错误码,类似于 HTTP 协议的 404, 502 等等。Application 报出来的错误码在一个区间,Oitsi 内部产生的错误在另一个区间,比如 0-1000,类似于 System Internal Error,监控这些错误码可以让我们知道这个系统的运行情况。
这个系统自从接手之后就有一个问题,就是它每时每刻都在报出来很多内部错误,比如发生内部超时,路由信息找不到,等等,每分钟有上万个错误。然而,系统的运行是完全正常的。
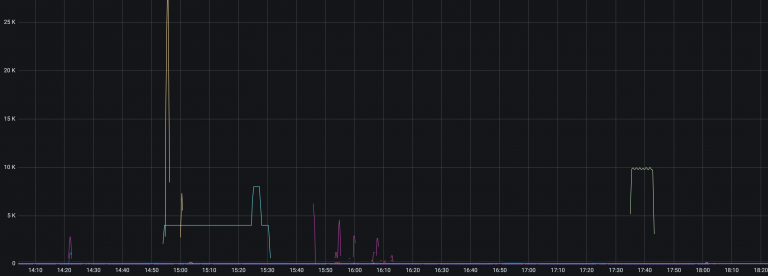
Oitsi 系统在正常情况下的错误
从这个脱敏之后的监控可以看到,经常有一些错误一下子动辄上万,除了图中几 K 的那些错误,在 1K 以下有更多密集的错误,只不过它们都被其他巨量的错误给拉平了,在这张图不明显。
这就给我们造成了很多问题:到底是 Oitsi 真出了问题,还是属于“正常的错误”?很难判断,每次发生这种情况都费时费力。大部分情况都是排查一番,然后发现是用户“滥用”造成的问题,不需要关心。而它又掩盖了很多真实的问题,比如一个新的版本发布之后偶尔会有一些内部的错误,是不应该发生的,却被真实的问题掩盖住了。基于这样的监控数据我们也无法设置告警,因为这些噪音太多了,即使有告警,也和没有一样。
这让我想起之前在蚂蚁的工作,我们有类似的问题。我有一年多的时间都在一个叫做“故障定位”的项目上。在蚂蚁我们也有很多告警(99%的)都是无效的,给 On Call 的同事带来很多噪音和打扰。在蚂蚁的思路是:开发一个“智能系统”(AI Ops),当告警发生的时候,自动地判断这个告警是不是噪音,是不是真正的问题,问题出在了哪里。拿到 Oitsi 的例子上说,当现在一个错误的数量突增,那么这个智能故障定位系统就去检查 Oitsi 的一些指标是否正常,导致告警的服务具体是什么,它之前是不是一直有类似的监控曲线模式,如果有,说明它一直在发生,是正常的,我们可以不管。
这样做了一年,效果还是不怎么样。我倒是发现,很多告警的规则本身就有问题,比如一个请求量每分钟只有两位数的服务,领导的要求是 “1分钟发现故障,5分钟定位故障”,不要说自动定位,就算是人去判断都不靠谱。为了达成这个目标,监控团队设置了很多非常敏锐的告警,交给定位团队说:“我们负责发现问题,你们负责定位问题。如果出问题了,1分钟之内有告警触发,那么我们的工作就达标了。但是至于没有问题我们也触发了很多噪音告警,就是你们的工作了。” 它们的 KPI 确实是完成了,只要有故障必定有告警。但事实是,在很多情况下,告警发出来,大家打开监控,盯着监控:“在等等看,看下一分钟,有请求进来了,服务没问题!”
所以这一年工作里,我有一个想法,就是在源头解决问题比使用高级的魔法系统去解决问题要简单、彻底很多。我们真的需要这么多人来开发一个“魔法系统”来帮我们诊断这种问题吗?
比如监控配置的不对,那就优化监控。监控为什么配置的不对?监控系统太难用,UI 让人捉摸不透,配置了告警无法调试,监控只能保存7天的数据,不能基于历史的监控数据配置告警。很多人为了“规则”,对服务配上了告警然后就走了,至于后面告警触发了,也不去响应。
回到 Oitsi 的问题上,我找了几个服务,发现这些 Oitsi 内部错误上并不能完全说是“正常的错误”,毕竟它是错误,没有错误会是正常的。只能说它没有导致线上问题而已。它们是可以被修复的。于是一个月前,我决定从源头去解决这些问题。把所有不应该报告出来的错误都消灭掉。
乍一看这么多错误数,用那么多团队在用,看起来是难以管理的,性价比非常低的工作。但是毕竟也没有人催我要快点完成,我可以一点一点去做。做一点错误就少一些(只要我解决问题的速度比新的问题出现的速度快)。
于是我按照下面的流程开始处理:
- 在 Jira(我们内部的工单系统)建立一个专题 tag,叫做 oitsi-abuse,后面的工单可以关联这个 tag,这样,可以在处理的时候方便参考之前的 Case;
- 创建一个监控,专门针对错误做一个面板,点击面板右侧的 Legend 可以直接跳到服务的监控面板,在服务的监控面板上显示下游,并且关联 CMDB 的 PIC(Person in charge);
- 这样,我从错误数最高的服务开始,查看监控,看下游服务,以及机器上的日志,看相关的错误码是什么时候开始的,到底是什么引起的,确定了是服务的问题就创建工单给这个服务的负责人,然后跟他联系,说明这个有什么问题,会对我们的监控、告警造成什么影响,需要修复;
- 等他确认问题,然后要求提供一个 ETA(预计修复的时间),把 ETA 写到工单中,到了时间去检查确认;
- 如果是 Oitsi 本身的问题,去找 Oitsi 开发同事排查问题;
- 等所有的问题都解决了的话,对错误设置告警,一有错误就去联系开发。一般情况下,都是他们做的配置变更或者发布引起了问题。这样对于业务其实是更加健康的,我们发现问题的能力更强了。
就这样,其实这样坐下来就发现只有那么几类问题,排查的速度越来越快。中间还发现一个库,它会去对 Oitsi 服务做心跳检查,这个检查设置不当会有一些错误。很多引用了这个库的应用都有一只在报错误的问题。但是我们系统本身其实已经做了探活可以保证心跳之类的问题了,沟通之后这个库的心跳检查行为可以下线。于是库发布了新的版本,我找所有的引用者去升级版本,很多错误一下子就消失了,非常有成就感。
这项工作的进度比我想象中的要快,一个多月,联系了 20 多个团队。虽然说也遇到了一些很扯的事情,明明是服务 A 的问题,就直接让我去找下游,让我们排查半天,最后又说回来找服务 A 负责人,拉了个群,摆出来日志,才承认是自己的问题,开始排查。但是大部分团队都非常配合,说明问题之后马上去排查,发现问题下一个版本就修复了。如此默契的合作让我感到惊讶又幸福!现在,系统错误维持在 200 以下了,并且现有的错误都已经找到了根因,还有3个服务待修复。最晚的会在 2 个周之后发布修复。可以预见到在不远的未来,这个系统将会成为一个 0 错误的系统!
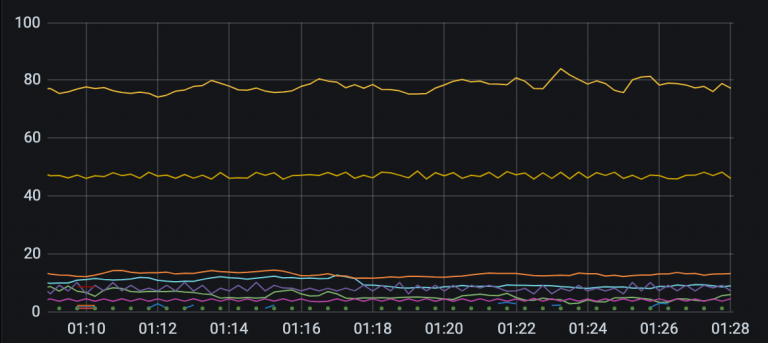
今天系统报出的错误,还是有一些服务在一直报错,不过已经大大减少了。
这项工作虽然不涉及任何的 KPI 之类的,也没有什么技术含量,还都是一些“沟通”的工作,但是却带给我很大的成就感。我相信它也会在未来节省我很多时间。比如说我们评估系统的 SLI 和 SLO,由于 false alarm 太多,导致要花很多工作确定 down time 有多少,现在直接通过监控就可以确定了。
这项工作带给我的一些感想:
- 从源头解决问题最彻底;
- 不要害怕沟通;
- 错误的发生都有原因,排查下去,零就是零,一就是一(从这个 Case 看,也确实所有的错误都可以被解决的);
- 每个公司都有脏活,累活(毕业去的第一家公司维护爬虫,也有很多脏活、累活),这些都需要有人去做。
需要补充一下,我并不是完全否定做故障定位的思路。毕竟之前在蚂蚁,有四五个组在做相同的东西,我们(和其他做一样东西的组)尝试过非常多的思路,也有很多人因为这些晋升了(你说去联系了无数个团队,排查了很多问题,这有什么 impact 呢?你说自己做了一个“智能定位”系统,晋升就稳了吧。)。印象比较深刻的是有个项目制定了上千个(他们称为)决策树,简单来说就是:如果发生这个,就去检查这个。颇有成效,很多配置不当的告警就被这种规则给过滤掉了(虽然我觉得直接改报警要好一些)。我非常佩服他们的毅力。
说了这么多湿货,再说点干货。我们其实还有一个问题没有解决。如果读者有思路,欢迎评论。
在 Service Mesh 中,所有的服务都是通过 Agent 来调用的。比如 App1 要调用 App2,它会把请求发到本地的 Agent 中,由 Agent 去调用 App2 所在机器的 Agent。
这里,超时的问题就难处理。比如我们设置了 1s 超时。假如说 server 端的 Application 超时了,那么 Server 段的 Agent 可以报告一个应用超时错误,不算做我们 Oitsi 系统错误。但是对于客户端的 Agent 呢?它无法知道到底是 Server 的应用超时了,还是 Server 的 Agent 超时了。所以对于 Server 超时的情况下,客户端的 Agent 总会报出一个内部超时错误。
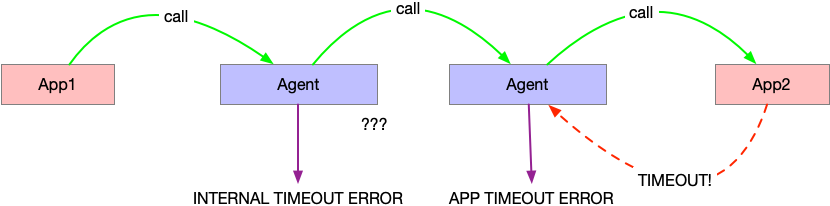
这种错误,我们当前还是无法区分是否是由应用引起的。

















