在德国法兰克福举行的国际超级计算大会上,2021第57版世界TOP500超级计算机排名正式公布,这一版Top10排名相比上一版只有很小的变化,唯一的一个新入围的超级计算机是来自美国新能源部劳伦斯伯克利国家实验室的Perlmutter系统。
全球超级计算机500强是指国际TOP500组织发布的,全球已安装的超级计算机系统排名,始于1993年,由美国与德国超算专家联合编制,以超级计算机基准程序Linpack测试值为序进行 排名 ,每年发布两次,其目的是促进国际超级计算机领域的交流和合作,促进超级计算机的推广应用。

这台超算基于 HPE Cray“Shasta”平台和由 GPU 加速和 CPU 节点的异构系统。Perlmutter 实现了 64.6 Pflop/s的算力,使这台超级计算机在新列表中排名第 5。
来自日本的“富岳”超级计算机仍然高居榜首,并且遥遥领先。
富岳由日本理化研究所和富士通联合研发,在HPL标准下算力为442Pflop/s,这样的性能表现超过了排名第二的美国顶点超级计算机的3倍。
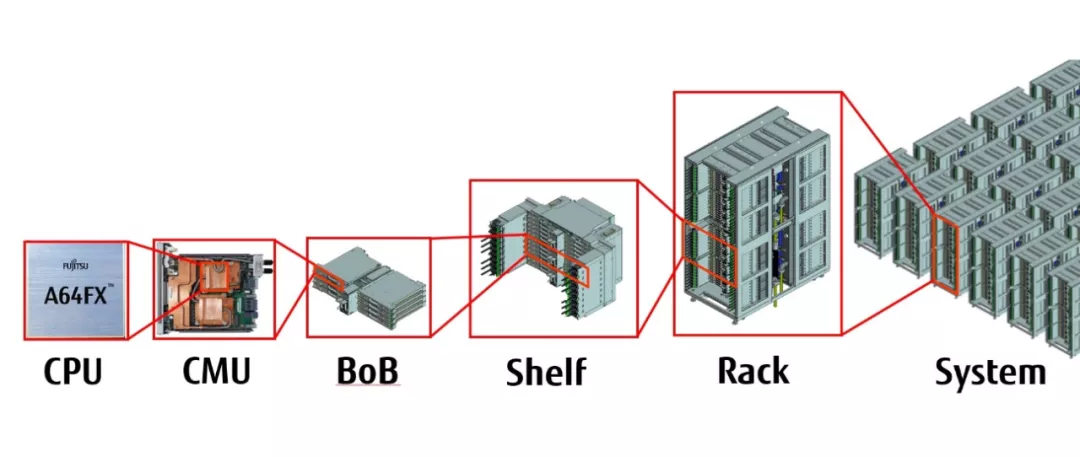
这套系统基于富士通定制的ARM A64FX处理器,另外,在人工智能领域经常使用的降精度计算中,这台计算机的峰值性能超过了每秒钟1exaflop,也就是每秒百万亿亿次浮点运算。
富岳是世界上第一台算力达到exaflop级别的超级计算机。
尽管前十名榜单变化不大,但是从整体排名来看,还是能发现一些重要的趋势。
首先就是采用AMD处理器的超级计算机显著增加,比如刚入选TOP10榜单的Perlmutter就是在用的AMD EPYC 7763处理器,排在第6的Selene也采用了AMD EPYC 7742.

另外一个现象是在TOP500榜单中,尽管其中中国超级计算机的绝对数量还是遥遥领先,但是由上一次的212变为现在186台,相应的,美国则由上一次的113台增至如今的123台。尚不清楚是否是由于芯片供应问题导致的负面效应。
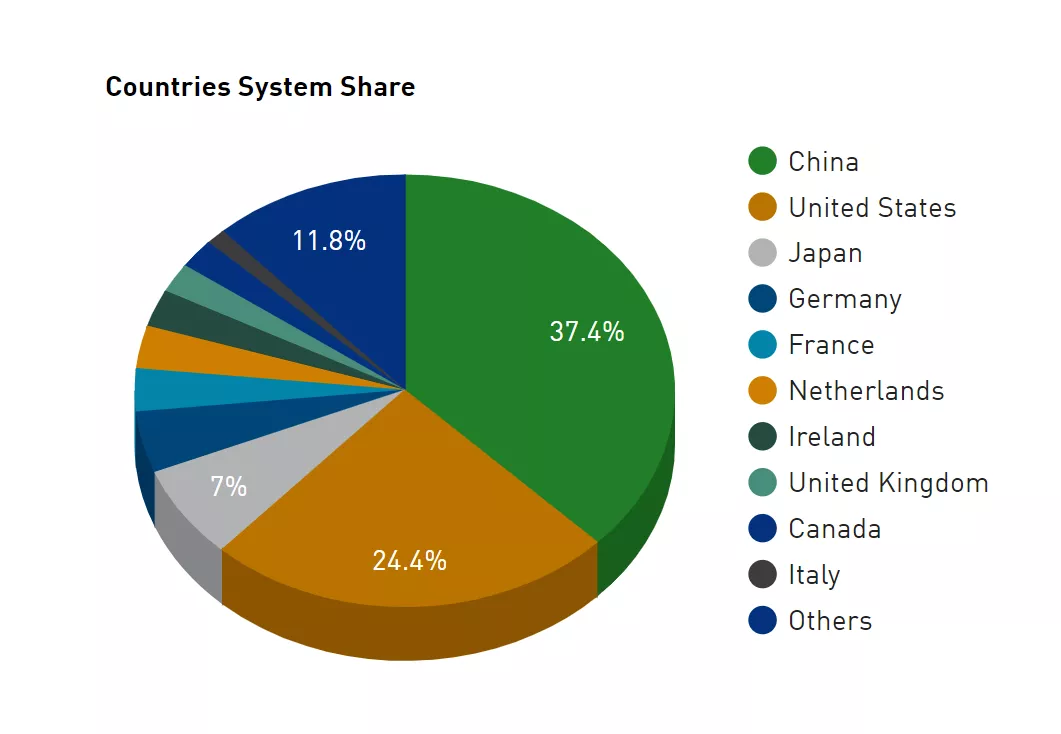
在综合性能指标上,来自美国的超级计算机仍然处于领先,目前总算力达到了856.8Pflop/s,而中国则为445.3Pflop/s。
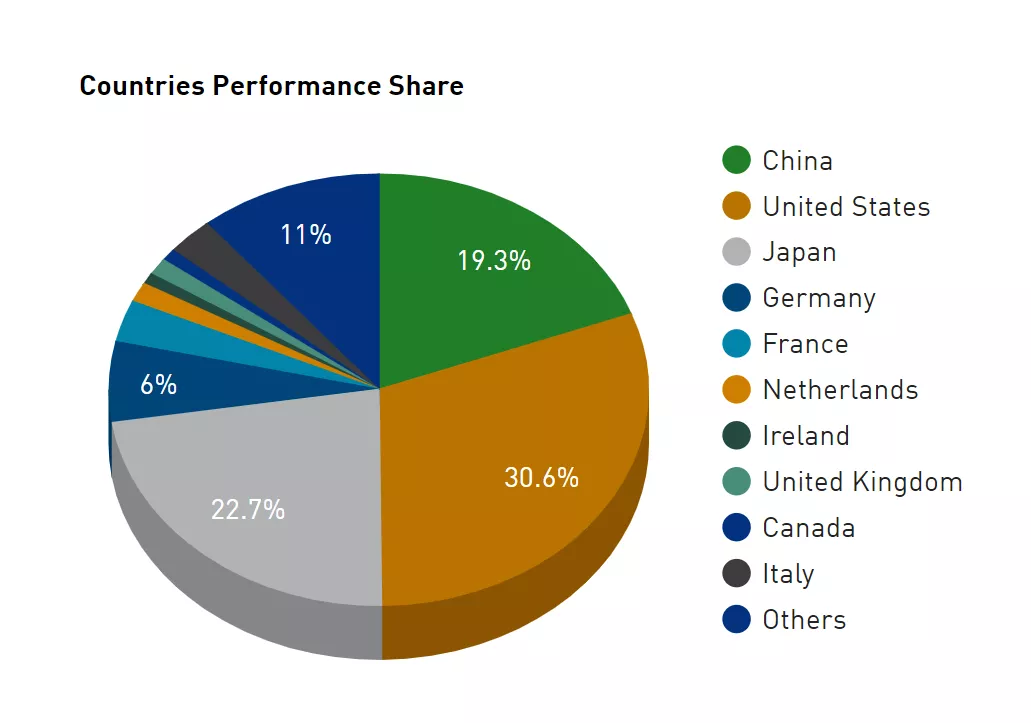
从制造商维度来看,中国联想目前是世界最大的超级计算机制造商,在TOP500中占据了35.8%的份额,而浪潮则紧随其后。
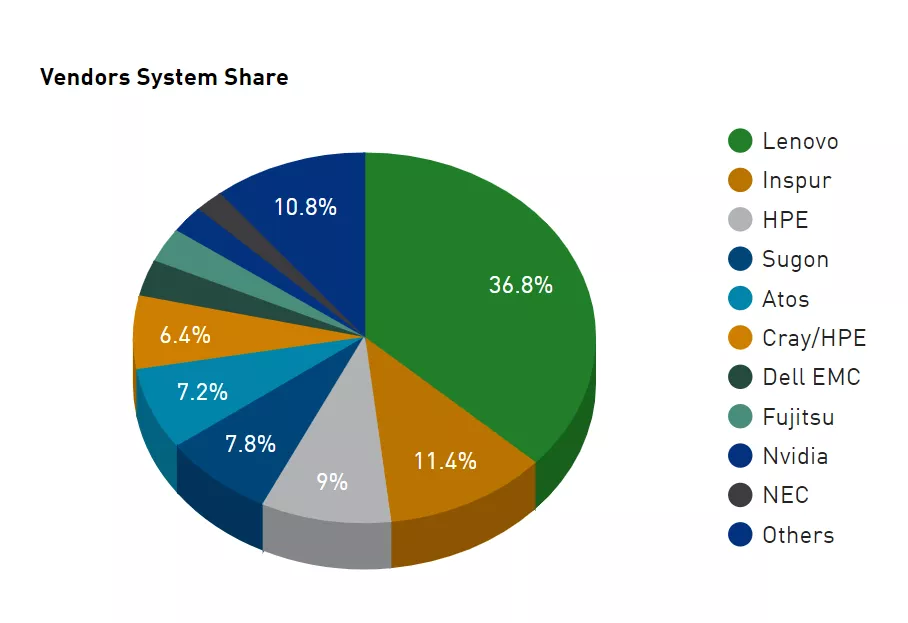
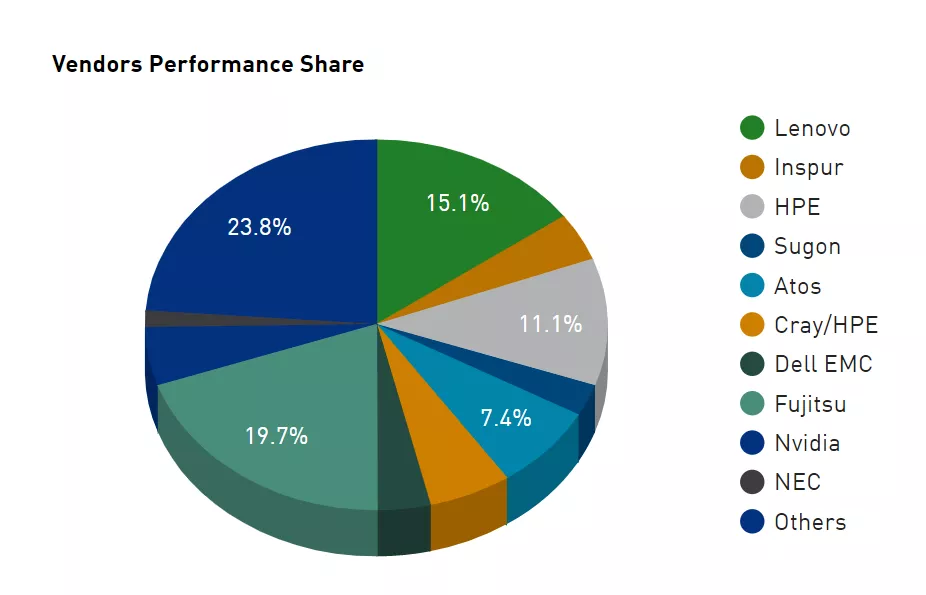
而在性能表现上,富士通由于打造了富岳这台怪物,所以在总算力上超过了联想排在第一。
全球TOP10超级计算机排名
|
排名 |
系统 |
核心数 |
测试性能 TFlop/s |
峰值性能 TFlop/s |
|
1 日本 |
富岳 |
7,630,848 |
442,010.0 |
537,212.0 |
|
2 美国 |
顶点 |
2,414,592 |
148,600.0 |
200,794.9 |
|
3 美国 |
山脊 |
1,572,480 |
94,640.0 |
125,712.0 |
|
4 中国 |
神威·太湖之光 |
10,649,600 |
93,014.6 |
125,435.9 |
|
5 美国 |
Perlmutter |
706,304 |
64,590.0 |
89,794.5 |
|
6 美国 |
月之女神Selene |
555,520 |
63,460.0 |
79,215.0 |
|
7 中国 |
天河二号 |
4,981,760 |
61,444.5 |
100,678.7 |
|
8 德国 |
JUWELS Booster Module |
449,280 |
44,120.0 |
70,980.0 |
|
9 意大利 |
HPC5 |
669,760 |
35,450.0 |
51,720.8 |
|
10 美国 |
Frontera |
448,448 |
23,516.4 |
38,745.9 |
富岳
「富岳」超算系统拥有158,976个节点,4.85 PB总内存,163 PB/s 内存带宽,15.9 PB NVMe L1存储。
|
算力 |
CPU默频:2GHz |
CPU超频:2.2GHz |
|
64位双精度FP |
488 PFLOP/s |
537 PFLOP/s |
|
32位单精度FP |
977 PFLOP/s |
1.07 EFLOP/s |
|
16位半精度 FP (AI 训练) |
1.95 EFLOP/s |
2.15 EFLOP/s |
|
8位整数(AI 推理) |
3.90 Exaops |
4.30 Exaops |
与那些使用X86+显卡的超算不同,「富岳」使用的是基于ARM架构的A64FX处理器。

A64FX拥有48个计算内核,以及提供给操作系统使用的2或4个辅助内核。
其采用全新的内核设计,ARM V8架构、64位生态系统、Tofu-D互联网络和PCIe Gen3 ×16。
同时还封装有HBM2内存,理论峰值内存带宽可达163 PB/s。
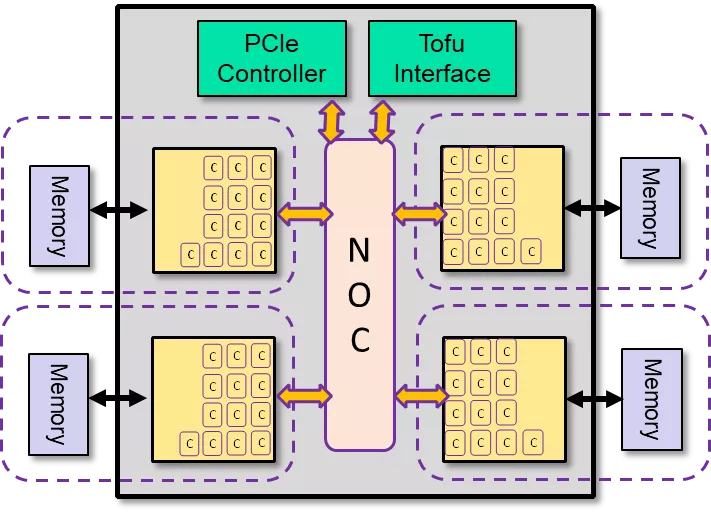
Tofu-D是什么?
Tofu是指「torus fusion」——「环形融合」,代表设计的尺寸组合与独立配置和路由算法。D是指高「密度」节点和「动态」数据包切片的「双轨 」传输。
这个难道真的不是日语的「豆腐」的谐音梗么。
虽然处理器没有 GPU 加速器,但它具有SVE 512 位× 2向量扩展,可以在整数1、2、4 和8字节以及浮点16、32 和 64 位级别上运行。
中国的超算
高性能计算主用在理论、实验难以解决的科学问题;大型、复杂、甚至不可重复和危险的工程设计和实验等。
早在2015年美国就开始对中国施行超算芯片禁售,从产业链条和技术层面进行遏制。
不过,我国目前正在进行超算生态系统的国产化。
「天河一号」和「天河二号」已经开始试用自主研制的飞腾CPU,而「神威·太湖之光」更是搭载了40960个我国自主研发的「申威26010」众核处理器。
然而,目前更多的超算仍使用英特尔芯片。
好消息是,神威E级原型机的处理器、网络芯片组、存储和管理系统等核心器件全部实现国产化。
「天河三号」E级原型机则采用自主的飞腾处理器、天河高速互联通信和麒麟操作系统,实现了芯片的全国产化,告别了前代的英特尔芯片。
神威•太湖之光
2016-2017年排名第一
研制厂商:国家并行计算机工程技术研究中心
部署单位:国家超级计算无锡中心
测试性能:93.015 PFLOPS
系统峰值:125.436 PFLOPS
主要参数:
40960 个计算节点
40960 颗 申威 26010 260C 1.45GHz CPU
1.31PB 内存
230TB 储存
天河二号
2013-2015年排名世界第一
研制厂商:国防科技大学
部署单位:广州超级计算中心
测试性能:61.45 PFLOPS
系统峰值:100.68 PFLOPS
主要参数:
17792 个计算节点
35584 颗 Intel Xeon E5 - 2692 2.2GHz 12 核心 CPU
35584 颗 MATrix2000(1.2GHZ,2.46TFlops/ 颗)
5696 颗 Xeon Phi 31S1P 加速协处理器
3PB 内存