












本文将对Kafka Consumer做一个简单的介绍,是深入研究Kafka Conumer的一扇窗。主要从如下三个方面展开:
- 核心参数
- 核心组件
- 核心API
1、Kafka Consumer核心参数览
个人觉得,要想深入了解Kafka Consumer的核心工作机制可以从它的核心参数切入,为后续深入了解它的队列负载机制、消息拉取模型、消费模型、位点提交等机制打下基础。
kafka Consumer的核心属性定义在ConsumerConfig中。
1.1 基础功能参数
- group.id
消费组名称。
- client.id
客户端标识id,默认为consumer-序号,在实践中建议包含客户端IP,在一个消费组中不能重复。
- bootstrap.servers
broker服务端地址列表。
- client.dns.lookup
客户端寻找bootstrap地址的方式,支持如下两种方式:
- resolve_canonical_bootstrap_servers_only
这种方式,会依据bootstrap.servers提供的主机名(hostname),根据主机上的名称服务返回其IP地址的数组(InetAddress.getAllByName),然后依次获取inetAddress.getCanonicalHostName(),再建立tcp连接。
一个主机可配置多个网卡,如果启用该功能,应该可以有效利用多网卡的优势,降低Broker的网络端负载压力。
- use_all_dns_ips
这种方式会直接使用bootstrap.servers中提供的hostname、port创建tcp连接,默认选项。
- enable.auto.commit
是否开启自动位点提交,默认为true。
- auto.commit.interval.ms
如果开启自动位点提交,位点的提交频率,默认为5s。
- partition.assignment.strategy
消费端队列负载算法,默认为按区间平均分配(RangeAssignor),可选值:轮询(RoundRobinAssignor)
- auto.offset.reset
重置位点策略,但kafka提交位点时,对应的消息已被删除时采取的恢复策略,默认为latest,可选:earliest、none(会抛出异常)。
- key.deserializer
使用的key序列化类
- value.deserializer
消息体序列化类
- interceptor.classes
消费端拦截器,可以有多个。
- check.crcs
在消费端时是否需要校验CRC,默认为true。
1.2 网络相关参数
- send.buffer.bytes
网络通道(TCP)的发送缓存区大小,默认为128K。
- receive.buffer.bytes
网络通道(TCP)的接收缓存区大小,默认为32K。
- reconnect.backoff.ms
重新建立链接的等待时长,默认为50ms,属于底层网络参数,基本无需关注。
- reconnect.backoff.max.ms
重新建立链接的最大等待时长,默认为1s,连续两次对同一个连接建立重连,等待时间会在reconnect.backoff.ms的初始值上成指数级递增,但超过max后,将不再指数级递增。
- retry.backoff.ms
重试间隔时间,默认为100ms。
- connections.max.idle.ms
连接的最大空闲时间,默认为9s。
- request.timeout.ms
请求的超时时间,与Broker端的网络通讯的请求超时时间。
1.3 核心工作参数
- max.poll.records
每一次poll方法调用拉取的最大消息条数,默认为500。
- max.poll.interval.ms
两次poll方法调用的最大间隔时间,单位毫秒,默认为5分钟。如果消费端在该间隔内没有发起poll操作,该消费者将被剔除,触发重平衡,将该消费者分配的队列分配给其他消费者。
- session.timeout.ms
消费者与broker的心跳超时时间,默认10s,broker在指定时间内没有收到心跳请求,broker端将会将该消费者移出,并触发重平衡。
- heartbeat.interval.ms
心跳间隔时间,消费者会以该频率向broker发送心跳,默认为3s,主要是确保session不会失效。
- fetch.min.bytes
一次拉取消息最小返回的字节数量,默认为1字节。
- fetch.max.bytes
一次拉取消息最大返回的字节数量,默认为1M,如果一个分区的第一批消息大小大于该值也会返回。
- max.partition.fetch.bytes
一次拉取每一个分区最大拉取字节数,默认为1M。
- fetch.max.wait.ms
fetch等待拉取数据符合fetch.min.bytes的最大等待时间。
- metadata.max.age.ms
元数据在客户端的过期时间,过期后客户端会向broker重新拉取最新的元数据,默认为5分钟。
- internal.leave.group.on.close
消费者关闭后是否立即离开订阅组,默认为true,即当客户端断开后立即触发重平衡。如果设置为false,则不会立即触发重平衡,而是要等session过期后才会触发。
2、KafkaConsumer核心组件与API
通过KafkaConsumer核心参数,我们基本可以窥探Kafka中的核心要点,接下来再介绍一下KafkaConsumer的核心组件,为后续深入研究Kafka消费者消费模型打下基础。
2.1 核心组件
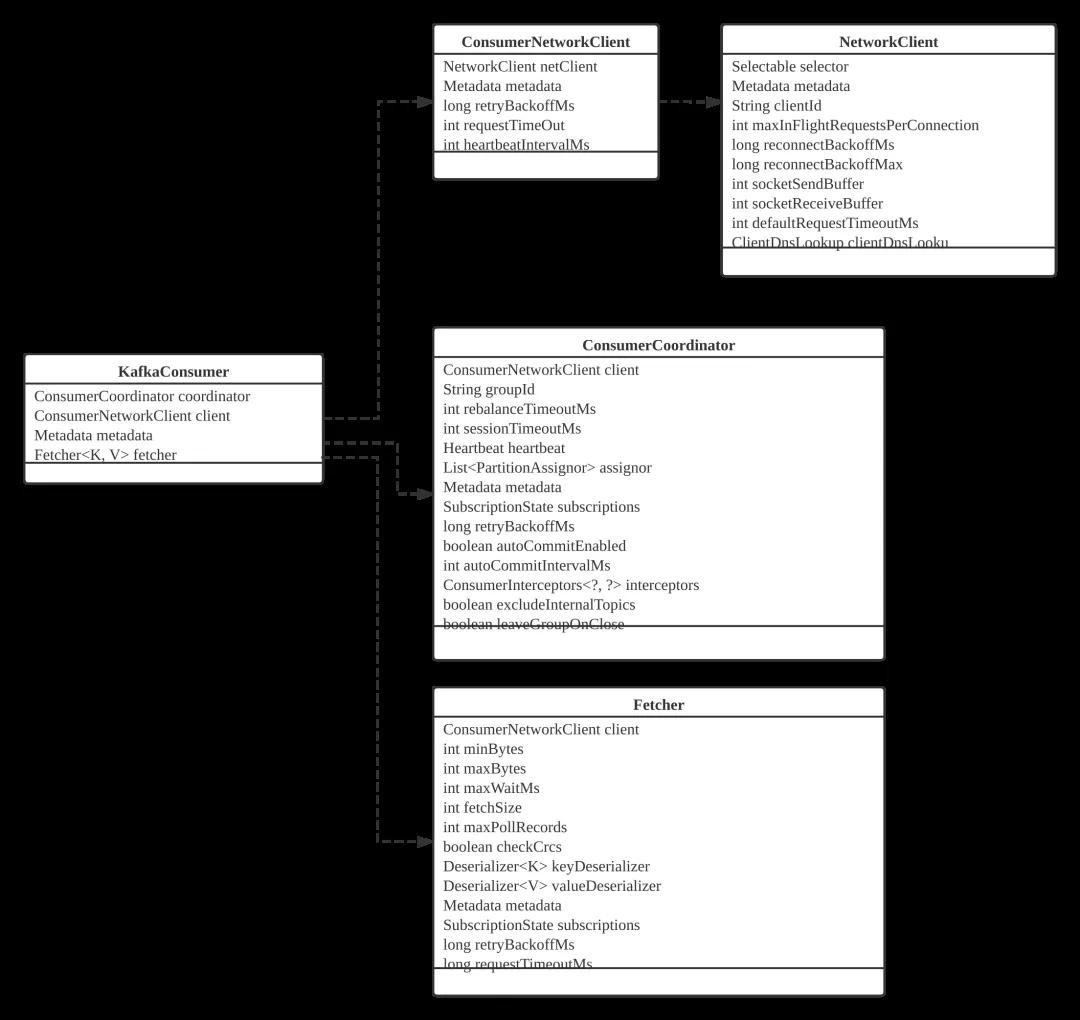
KafkaConsumer由如下几个核心组件构成:
- ConsumerNetworkClient
消费端网络客户端,服务底层网络通讯,负责客户端与服务端的RPC通信。
- ConsumerCoordinator
消费端协调器,在Kafka的设计中,每一个消费组在集群中会选举一个broker节点成为该消费组的协调器,负责消费组状态的状态管理,尤其是消费组重平衡(消费者的加入与退出),该类就是消费者与broker协调器进行交互。
- Fetcher
消息拉取。
温馨提示:本文不打算对每一个组件进行详细解读,这里建议大家按照本文第一部分关于各个参数的含义,然后对照这些参数最终是传resume递给哪些组件,进行一个关联思考。
2.2 核心API概述
最后我们再来看一下消费者的核心API。

- Set< TopicPartition> assignment()
获取该消费者的队列分配列表。
- Set< String> subscription()
获取该消费者的订阅信息。
- void subscribe(Collection< String> topics)
订阅主题。
- void subscribe(Collection< String> topics, ConsumerRebalanceListener callback)
订阅主题,并指定队列重平衡的监听器。
- void assign(Collection< TopicPartition> partitions)
取代 subscription,手动指定消费哪些队列。
- void unsubscribe()
取消订阅关系。
- ConsumerRecords
poll(Duration timeout)
拉取消息,是 KafkaConsumer 的核心方法,将在下文详细介绍。
- void commitSync()
同步提交消费进度,为本批次的消费提交,将在后续文章中详细介绍。
- void commitSync(Duration timeout)
同步提交消费进度,可设置超时时间。
- void commitSync(Map
offsets)
显示同步提交消费进度, offsets 指明需要提交消费进度的信息。
- void commitSync(final Map
offsets, final Duration timeout)
显示同步提交消费进度,带超时间。
- void seek(TopicPartition partition, long offset)
重置 consumer#poll 方法下一次拉消息的偏移量。
- void seek(TopicPartition partition, OffsetAndMetadata offsetAndMetadata)
seek 方法重载方法。
- void seekToBeginning(Collection< TopicPartition> partitions)
将 poll 方法下一次的拉取偏移量设置为队列的初始偏移量。
- void seekToEnd(Collection< TopicPartition> partitions)
将 poll 方法下一次的拉取偏移量设置为队列的最大偏移量。
- long position(TopicPartition partition)
获取将被拉取的偏移量。
- long position(TopicPartition partition, final Duration timeout)
同上。
- OffsetAndMetadata committed(TopicPartition partition)
获取指定分区已提交的偏移量。
- OffsetAndMetadata committed(TopicPartition partition, final Duration timeout)
同上。
- Map metrics()
统计指标。
- List< PartitionInfo> partitionsFor(String topic)
获取主题的路由信息。
- List< PartitionInfo> partitionsFor(String topic, Duration timeout)
同上。
- Map listTopics()
获取所有 topic 的路由信息。
- Map listTopics(Duration timeout)
同上。
- Set< TopicPartition> paused()
获取已挂起的分区信息。
- void pause(Collection< TopicPartition> partitions)
挂起分区,下一次 poll 方法将不会返回这些分区的消息。
- void resume(Collection< TopicPartition> partitions)
恢复挂起的分区。
- Map
offsetsForTimes(MaptimestampsToSearch)
根据时间戳查找最近的一条消息的偏移量。
- Map
offsetsForTimes(MaptimestampsToSearch, Duration timeout)
同上。
- Map
beginningOffsets(Collection< TopicPartition> partitions)
查询指定分区当前最小的偏移量。
- Map
beginningOffsets(Collection< TopicPartition> partitions, Duration timeout)
同上。
- Map
endOffsets(Collection< TopicPartition> partitions)
查询指定分区当前最大的偏移量。
- Map
endOffsets(Collection< TopicPartition> partitions, Duration timeout)
同上。
- void close()
关闭消费者。
- void close(Duration timeout)
关闭消费者。
- void wakeup()
唤醒消费者。
Kafka提供的消费者并不像RocketMQ提供了Push模式自动拉取消息,需要应用程序自动组织这些API进行消息拉取。
值得注意的kafka消费者也支持位点自动提交机制,kafka的消费者(KafkaConsumer)对象是线程不安全的。
基于KafkaConsumer的pause(暂停某些分区的消费)与resume(恢复某些分区的消费),可以轻松实现消费端限流机制。
本文主要是对消费者有一个大概的了解,后续文章将持续逐一解开消费者的核心运作机制,请持续关注。
本文转载自微信公众号「中间件兴趣圈」,可以通过以下二维码关注。转载本文请联系中间件兴趣圈公众号。






















