












前言Hi,大家好,我是麦洛,今天带大家来了解一下SpringCloud Sleuth,这篇文章主要向大家介绍一下以下内容

Sleuth介绍
你或许曾经听过这么一句话,一个新技术的出现是为了解决一个痛点问题。在介绍Sleuth之前,我们需要了解一下在没有Sleuth之前,我们的微服务遇到了什么问题?
1.微服务的现状?
前段时间在一个交流群吹水,一个大佬说他们公司总共有上百个微服务。假如这句话真实,那么他们公司微服务调用可能会如下图所示:
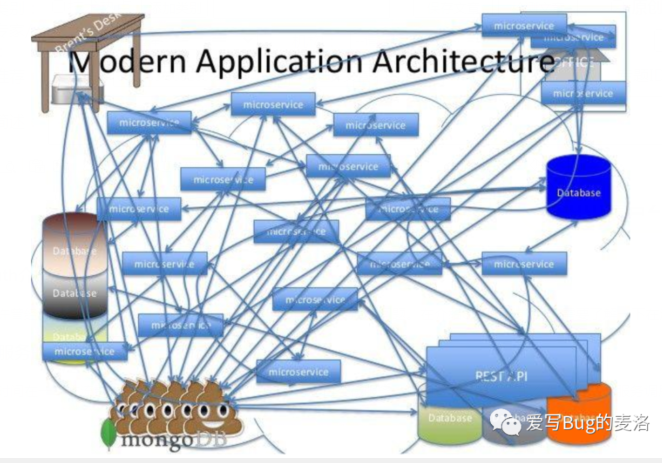
来自网络的这张图很好的说明了微服务调用之间的复杂性。每一次前端请求往往需要涉及到多个服务。这些服务有可能是由不同的团队开发、可能使用不同的编程语言来实现、有可能布在了几千台服务器,横跨多个不同的数据中心。因此,就需要一些可以帮助理解系统行为、用于分析性能问题的工具,以便发生故障的时候,能够快速定位和解决问题。所以,链路追踪这个思想就被人提了出来,而我们今天要讨论的Sleuth就是借鉴该思想演变来的分布式追踪解决方案。
2.微服务跟踪解决了什么问题?
微服务跟踪(sleuth)其实是一个工具,它在整个分布式系统中能跟踪一个用户请求的过程(包括数据采集,数据传输,数据存储,数据分析,数据可视化),捕获这些跟踪数据,就能构建微服务的整个调用链的视图,这是调试和监控微服务的关键工具。SpringCloudSleuth有4个特点

Sleuth基本术语
Spring Cloud Sleuth采用的是Google的开源项目Dapper的专业术语。
Span:基本工作单元,发送一个远程调度任务 就会产生一个Span,Span是一个64位ID唯一标识的,Trace是用另一个64位ID唯一标识的,Span还有其他数据信息,比如摘要、时间戳事件、Span的ID、以及进度ID。
Trace:一系列Span组成的一个树状结构。请求一个微服务系统的API接口,这个API接口,需要调用多个微服务,调用每个微服务都会产生一个新的Span,所有由这个请求产生的Span组成了这个Trace。
Annotation:用来及时记录一个事件的,一些核心注解用来定义一个请求的开始和结束 。这些注解包括以下:
- cs - Client Sent -客户端发送一个请求,这个注解描述了这个Span的开始
- sr - Server Received -服务端获得请求并准备开始处理它,如果将其sr减去cs时间戳便可得到网络传输的时间。
- ss - Server Sent (服务端发送响应)–该注解表明请求处理的完成(当请求返回客户端),如果ss的时间戳减去sr时间戳,就可以得到服务器请求的时间。
- cr - Client Received (客户端接收响应)-此时Span的结束,如果cr的时间戳减去cs时间戳便可以得到整个请求所消耗的时间。
Sleuth入门案例
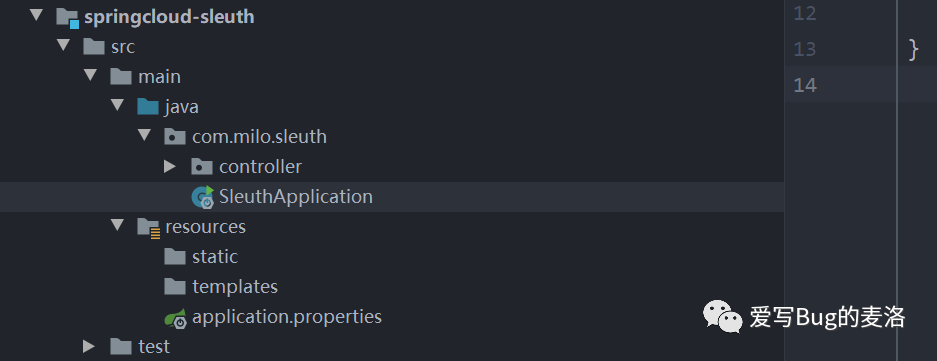
首先我们搞一个项目,大概如下面样子
我们引入下面的依赖
- <dependencies>
- <dependency>
- <groupId>org.springframework.boot</groupId>
- <artifactId>spring-boot-starter-web</artifactId>
- </dependency>
- <!--关键依赖-->
- <dependency>
- <groupId>org.springframework.cloud</groupId>
- <artifactId>spring-cloud-starter-sleuth</artifactId>
- </dependency>
- <dependency>
- <groupId>org.projectlombok</groupId>
- <artifactId>lombok</artifactId>
- </dependency>
- <dependency>
- <groupId>org.springframework.boot</groupId>
- <artifactId>spring-boot-starter-test</artifactId>
- <scope>test</scope>
- <exclusions>
- <exclusion>
- <groupId>org.junit.vintage</groupId>
- <artifactId>junit-vintage-engine</artifactId>
- </exclusion>
- </exclusions>
- </dependency>
我们创建一个测试类:
- package com.milo.sleuth.controller;
- import lombok.extern.slf4j.Slf4j;
- import org.springframework.web.bind.annotation.RequestMapping;
- import org.springframework.web.bind.annotation.RestController;
- @RestController
- @Slf4j
- public class Example {
- @RequestMapping("/")
- String home() {
- log.info("Hello world!");
- return "Hello World!";
- }
- }
启动项目以后,我们访问一下:
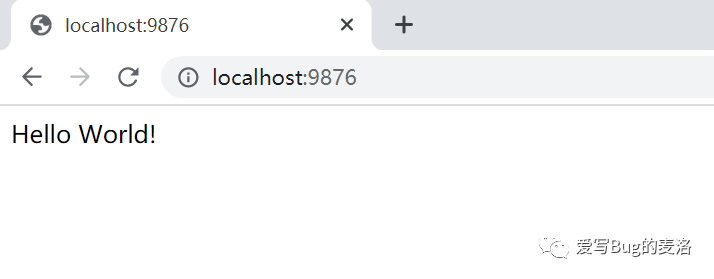
这时候,我们来看看日志情况:

我们来看看它们分别代表什么意思
- 第一个就是我们服务名称,对应我们配置文件中的spring.application.name
- 第二个就是traceId
- 第三个就是spanId
虽然我们现在通过日志文件也可以识别调用路径,貌似并不是很方便,很直观,接下里我们来了解一下Zipkin
Zipkin介绍
Zipkin是一个分布式跟踪系统。它有助于收集解决服务体系结构中的延迟问题所需的时序数据。功能包括该数据的收集和查找。
如果您在日志文件中有跟踪ID,则可以直接跳至该跟踪ID。否则,您可以基于诸如服务,操作名称,标签和持续时间之类的属性进行查询。将为您汇总一些有趣的数据,例如服务中花费的时间百分比以及操作是否失败。
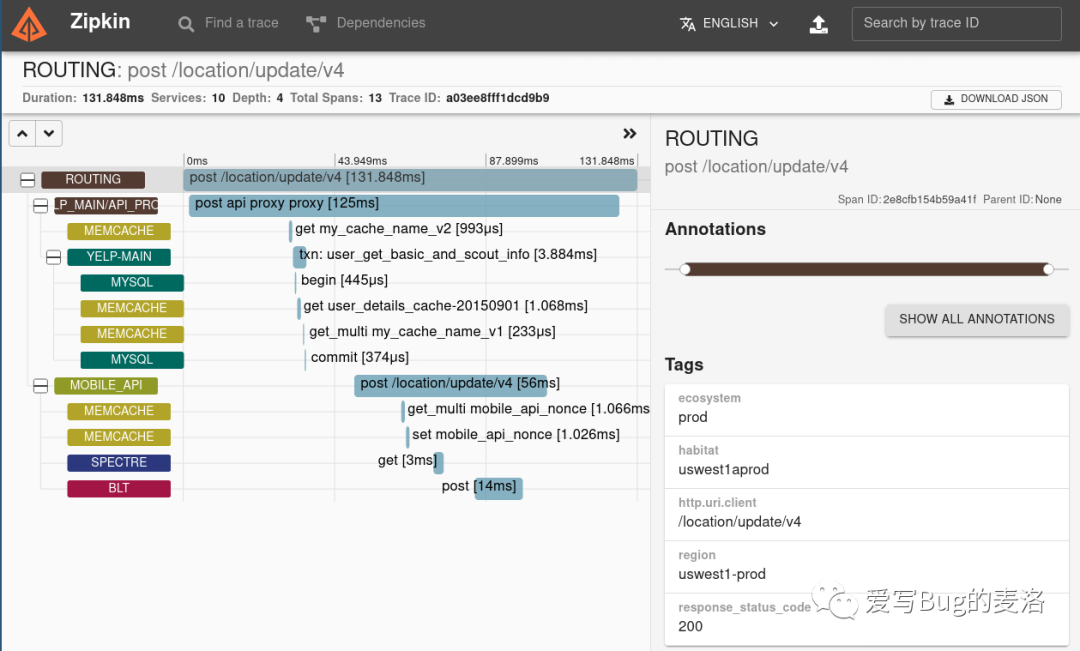
跟踪视图屏幕截图
Zipkin UI还提供了一个依赖关系图,该关系图显示了每个应用程序中跟踪了多少个请求。这对于识别包括错误路径或对不赞成使用的服务的调用在内的汇总行为可能会有所帮助。
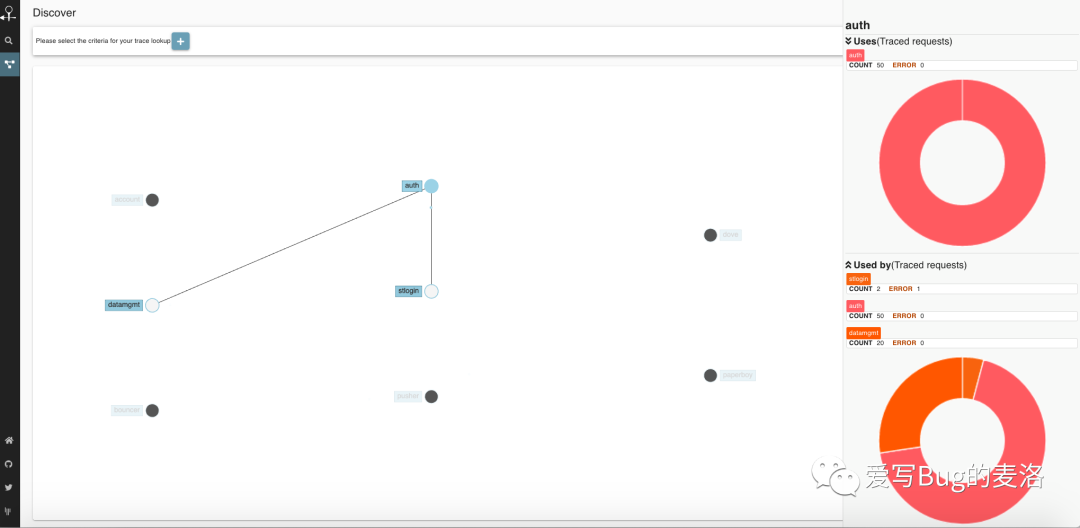
依赖图屏幕截图
需要对应用程序进行“仪表化”以将跟踪数据报告给Zipkin。这通常意味着配置跟踪器或仪器库。向Zipkin报告数据的最流行方法是通过HTTP或Kafka,尽管存在许多其他选项,例如Apache ActiveMQ,gRPC和RabbitMQ。提供给UI的数据存储在内存中,或持久存储在受支持的后端(例如Apache Cassandra或Elasticsearch)中。
Sleuth整合
ZipkinZipkin 分为两端,一个是 Zipkin 服务端,一个是 Zipkin 客户端,客户端也就是微服务的应用,客户端会配置服务端的 URL 地址,一旦发生服务间的调用的时候,会被配置在微服务里面的 Sleuth 的监听器监听,并生成相应的 Trace 和 Span 信息发送给服务端。发送的方式有两种,一种是消息总线的方式如 RabbitMQ 发送,还有一种是 HTTP 报文的方式发送。
客户端
首先,在刚刚的依赖文件中,我们加一个新成员
- <dependency>
- <groupId>org.springframework.cloud</groupId>
- <artifactId>spring-cloud-starter-zipkin</artifactId>
- </dependency>
接着修改配置文件
- # 应用名称
- spring:
- application:
- name: springcloud-sleuth
- # 应用服务 WEB 访问端口
- server:
- port: 9876
- zipkin:
- base-url: http://localhost:9411/ # 服务端地址
- sender:
- type: web # 数据传输方式,web 表示以 HTTP 报文的形式向服务端发送数据
- sleuth:
- sampler:
- probability: 1.0 # 收集数据百分比,默认 0.1(10%)
服务端
Zipkin的服务端是一个可执行的jar文件,我们需要去下载
下载地址:https://search.maven.org/remote_content?g=io.zipkin&a=zipkin-server&v=LATEST&c=exec
上面地址默认下载最新版本,大家也可以去下面的网址下载指定版本
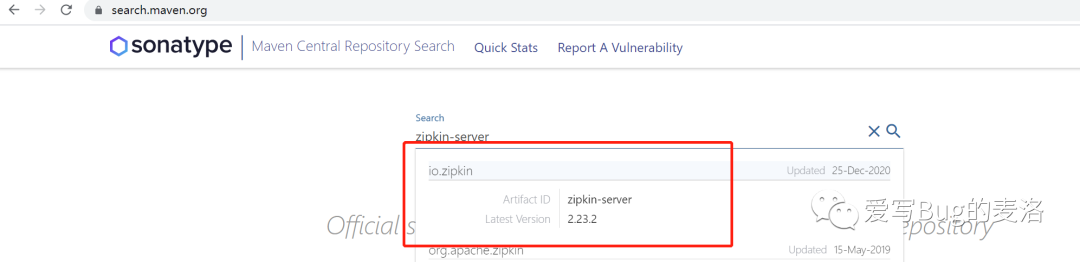

现在我们启动jar包
- java -jar zipkin-server-2.23.2-exec.jar

测试效果
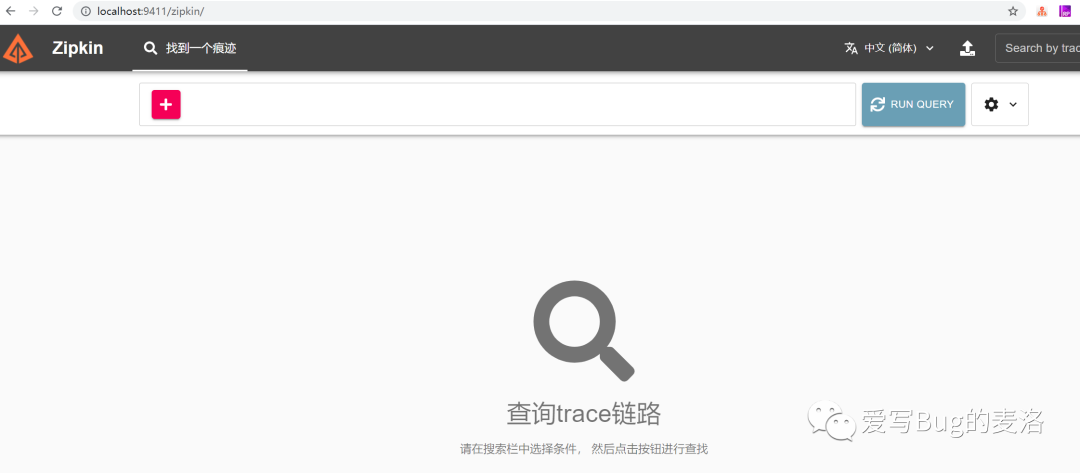
接下来我们访问一下http://localhost:9411/zipkin/,结果如下:
环境搭架好了,现在我们测试一把,看看接入Zipkin之后,我们会看到什么效果?
我们访问http://localhost:9876/之后,点击Zipkin控制台的Run Query查询一下,看到如下效果:

继续点击show,我们去看看详情
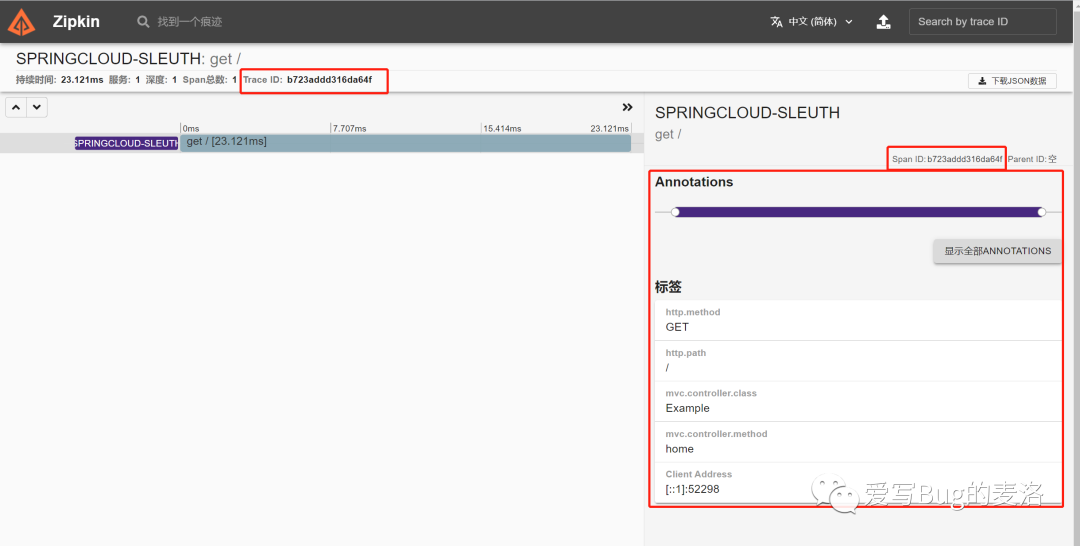
果然很强大,执行时间,什么请求方式,请求路径,那个类,那个方法一目了然
鉴于我们刚刚新建的只是一次很简单的调用,不足以模拟微服务场景,接下来我们来看一个复杂一点的场景;
这里为了偷懒,我们就不去创建自己的微服务,使用官方给我们提供的测试案例brave-example,如下所示
我们把代码搞下来,这个项目好像整合了好多技术的测试案例,看不懂,我就研究了下面的这个跑起来测试一下
我们用idea把这个项目导入进来,大概长这个鬼样子

- Backend代表后端服务
- Frontend代表前端服务
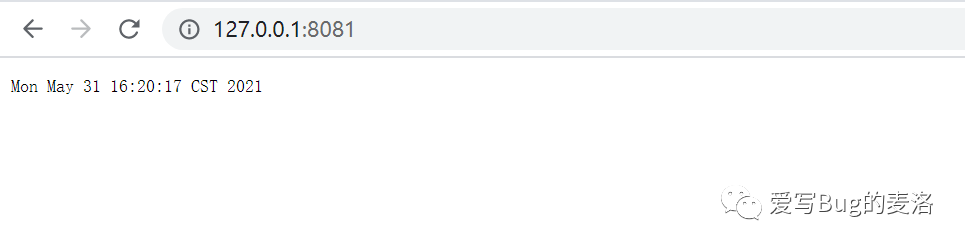
现在,我们首先保证我们Zipkin的服务端是ok的,这时候你首先启动后端服务,然后启动前端服务,其实就是执行以下main方法,接下来我们访问一下http://127.0.0.1:8081/,如下图所示
现在我们去zipkin查询一下,发现了一个新大陆,开心
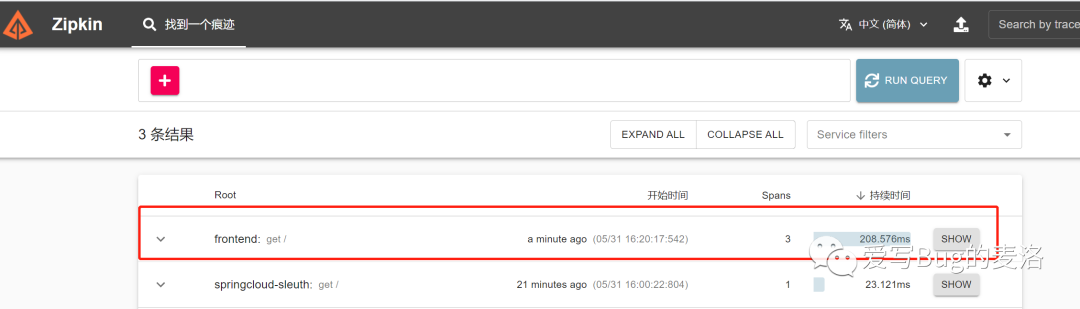
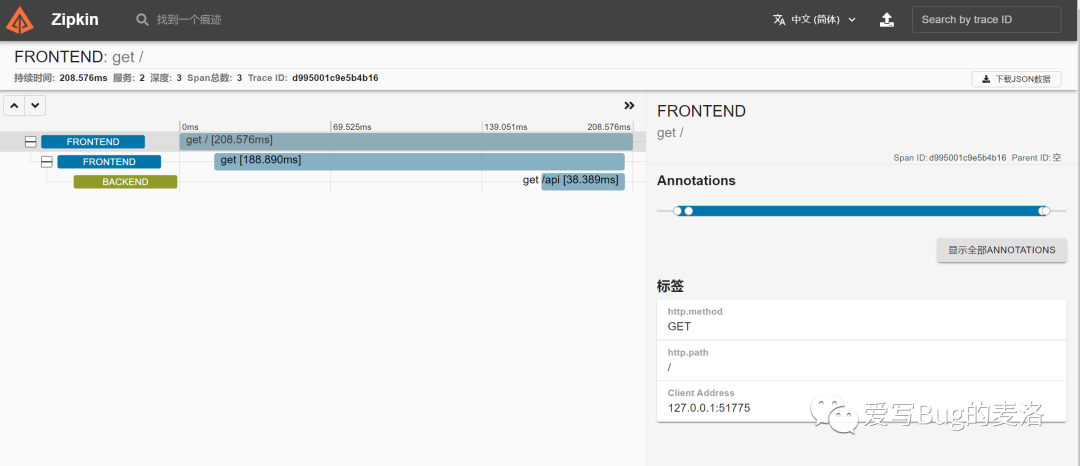
就行show一下,看看里面啥情况
总结本篇文章主要介绍了Sleuth的入门知识,并且整合Zipkin来可视化显示调用链路的整体情况,但是目前Zipkin数据存在于内存中,我们可以在接入Elasticsearch等工具来做数据持久化。谢谢大家,今天的分享就到这里





















