













面试官:好久不见啊,上次我们聊完了PriorityBlockingQueue,今天我们再来聊聊和它相关的DelayQueue吧?
Hydra:就知道你前面肯定给我挖了坑,DelayQueue也是一个无界阻塞队列,但是和之前我们聊的其他队列不同,不是所有类型的元素都能够放进去,只有实现了Delayed接口的对象才能放进队列。Delayed对象具有一个过期时间,只有在到达这个到期时间后才能从队列中取出。
面试官:有点意思,那么它有什么使用场景呢?
Hydra:不得不说,由于DelayQueue的精妙设计,使用场景还是蛮多的。例如在电商系统中,如果有一笔订单在下单30分钟内没有完成支付,那么就需要自动取消这笔订单。还有,如果我们缓存了一些数据,并希望这些缓存在一定时间后失效的话,也可以使用延迟队列将它从缓存中删除。
以电商系统为例,可以简单看一下这个流程:
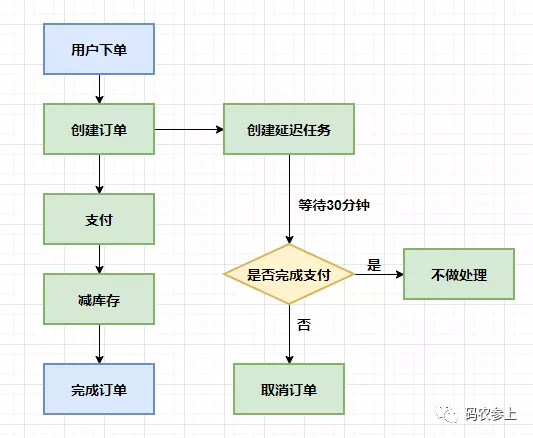
面试官:看起来和任务调度有点类似啊,它们之间有什么区别吗?
Hydra:任务调度更多的偏向于定时的特性,是在指定的时间点或时间间隔执行特定的任务,而延迟队列更多偏向于在指定的延迟时间后执行任务。相对任务调度来说,上面举的例子中的延迟队列场景都具有高频率的特性,使用定时任务来实现它们的话会显得有些过于笨重了。
面试官:好了,你也白话了半天了,能动手就别吵吵,还是先给我写个例子吧。
Hydra:好嘞,前面说过存入队列的元素要实现Delayed接口,所以我们先定义这么一个类:
- public class Task implements Delayed {
- private String name;
- private long delay,expire;
- public Task(String name, long delay) {
- this.name = name;
- this.delay = delay;
- this.expire=System.currentTimeMillis()+delay;
- }
- @Override
- public long getDelay(TimeUnit unit) {
- return unit.convert(this.expire - System.currentTimeMillis(), TimeUnit.MILLISECONDS);
- }
- @Override
- public int compareTo(Delayed o) {
- return (int)(this.getDelay(TimeUnit.MILLISECONDS) - o.getDelay(TimeUnit.MILLISECONDS));
- }
- }
实现了Delayed接口的类必须要实现下面的两个方法:
- getDelay方法用于计算对象的剩余延迟时间,判断对象是否到期,计算方法一般使用过期时间减当前时间。如果是0或负数,表示延迟时间已经用完,否则说明还没有到期
- compareTo方法用于延迟队列的内部排序比较,这里使用当前对象的延迟时间减去被比较对象的延迟时间
在完成队列中元素的定义后,向队列中加入5个不同延迟时间的对象,并等待从队列中取出:
- public void delay() throws InterruptedException {
- DelayQueue<Task> queue=new DelayQueue<>();
- queue.offer(new Task("task1",5000));
- queue.offer(new Task("task2",1000));
- queue.offer(new Task("task3",6000));
- queue.offer(new Task("task4",100));
- queue.offer(new Task("task5",3000));
- while(true){
- Task task = queue.take();
- System.out.println(task);
- }
- }
运行结果如下,可以看到按照延迟时间从短到长的顺序,元素被依次从队列中取出。
- Task{name='task4', delay=100}
- Task{name='task2', delay=1000}
- Task{name='task5', delay=3000}
- Task{name='task1', delay=5000}
- Task{name='task3', delay=6000}
面试官:看起来应用还是挺简单的,但今天也不能这么草草了事吧,还是说说原理吧。
Hydra:开始的时候你自己不都说了吗,今天咱们聊的DelayQueue和前几天聊过的PriorityBlockingQueue多少有点关系。DelayQueue的底层是PriorityQueue,而PriorityBlockingQueue和它的差别也没有多少,只是在PriorityQueue的基础上加上锁和条件等待,入队和出队用的都是二叉堆的那一套逻辑。底层使用的有这些:
- private final transient ReentrantLock lock = new ReentrantLock();
- private final PriorityQueue<E> q = new PriorityQueue<E>();
- private Thread leader = null;
- private final Condition available = lock.newCondition();
面试官:你这样也有点太糊弄我了吧,这就把我敷衍过去了?
Hydra:还没完呢,还是先看入队的offer方法,它的源码如下:
- public boolean offer(E e) {
- final ReentrantLock lock = this.lock;
- lock.lock();
- try {
- q.offer(e);
- if (q.peek() == e) {
- leader = null;
- available.signal();
- }
- return true;
- } finally {
- lock.unlock();
- }
- }
DelayQueue每次向优先级队列PriorityQueue中添加元素时,会以元素的剩余延迟时间delay作为排序的因素,来实现使最先过期的元素排在队首,以此达到在之后从队列中取出的元素都是先取出最先到达过期的元素。
二叉堆的构造过程我们上次讲过了,就不再重复了。向队列中添加完5个元素后,二叉堆和队列中的结构是这样的:

当每个元素在按照二叉堆的顺序插入队列后,会查看堆顶元素是否刚插入的元素,如果是的话那么设置leader线程为空,并唤醒在available上阻塞的线程。
这里先简单的介绍一下leader线程的作用,leader是等待获取元素的线程,它的作用主要是用于减少不必要的等待,具体的使用在后面介绍take方法的时候我们细说。
面试官:也别一会了,趁热打铁直接讲队列的出队方法吧。
Hydra:这还真没法着急,在看阻塞方法take前还得先看看非阻塞的poll方法是如何实现的:
- public E poll() {
- final ReentrantLock lock = this.lock;
- lock.lock();
- try {
- E first = q.peek();
- if (first == null || first.getDelay(NANOSECONDS) > 0)
- return null;
- else
- return q.poll();
- } finally {
- lock.unlock();
- }
- }
代码非常短,理解起来非常简单,在加锁后首先检查堆顶元素,如果堆顶元素为空或没有到期,那么直接返回空,否则返回堆顶元素,然后解锁。
面试官:好了,铺垫完了吧,该讲阻塞方法的过程了吧?
Hydra:阻塞的take方法理解起来会比上面稍微困难一点,我们还是直接看它的源码:
- public E take() throws InterruptedException {
- final ReentrantLock lock = this.lock;
- lock.lockInterruptibly();
- try {
- for (;;) {
- E first = q.peek();
- if (first == null)
- available.await();
- else {
- long delay = first.getDelay(NANOSECONDS);
- if (delay <= 0)
- return q.poll();
- first = null; // don't retain ref while waiting
- if (leader != null)
- available.await();
- else {
- Thread thisThread = Thread.currentThread();
- leader = thisThread;
- try {
- available.awaitNanos(delay);
- } finally {
- if (leader == thisThread)
- leader = null;
- }
- }
- }
- }
- } finally {
- if (leader == null && q.peek() != null)
- available.signal();
- lock.unlock();
- }
- }
阻塞过程中分支条件比较复杂,我们一个一个看:
- 首先获取堆顶元素,如果为空,那么说明队列中还没有元素,让当前线程在available上进行阻塞等待
- 如果堆顶元素不为空,那么查看它的过期时间,如果已到期,那么直接弹出堆顶元素
- 如果堆顶元素还没有到期,那么查看leader线程是否为空,如果leader线程不为空的话,表示已经有其他线程在等待获取队列的元素,直接阻塞当前线程。
- 如果leader为空,那么把当前线程赋值给它,并调用awaitNanos方法,在阻塞delay时间后自动醒来。唤醒后,如果leader还是当前线程那么把它置为空,重新进入循环,再次判断堆顶元素是否到期。
当有队列中的元素完成出队后,如果leader线程为空,并且堆中还有元素,就唤醒阻塞在available上的其他线程,并释放持有的锁。
面试官:我注意到一个问题,在上面的代码中,为什么要设置first = null呢?
Hydra:假设有多个线程在执行take方法,当第一个线程进入时,堆顶元素还没有到期,那么会将leader指向自己,然后阻塞自己一段时间。如果在这期间有其他线程到达,会因为leader不为空阻塞自己。
当第一个线程阻塞结束后,如果将堆顶元素弹出成功,那么first指向的元素应该被gc回收掉。但是如果还被其他线程持有的话,它就不会被回收掉,所以将first置为空可以帮助完成垃圾回收。
面试官:我突然有一个发散性的疑问,定时任务线程池ScheduledThreadPoolExecutor,底层使用的也是DelayQueue吗?
Hydra:问题很不错,但很遗憾并不是,ScheduledThreadPoolExecutor在类中自己定义了一个DelayedWorkQueue内部类,并没有直接使用DelayQueue。不过如果你看一下源码,就会看到它们实现的逻辑基本一致,同样是基于二叉堆的上浮、下沉、扩容,也同样基于leader、锁、条件等待等操作,只不过自己用数组又实现了一遍而已。说白了,看看两个类的作者,都是Doug Lea大神,所以差异根本没有多大。
面试官:好了,今天先到这吧,能最后再总结一下吗?
Hydra:DelayQueue整体理解起来也没有什么困难的点,难的地方在前面聊优先级队列的时候基本已经扫清了,新加的东西也就是一个对于leader线程的操作,使用了leader线程来减少不必要的线程等待时间。
面试官:今天的面试有点短啊,总是有点意犹未尽的感觉,看来下次得给你加点料了。
Hydra:…











