












挂载到linux的VFS中
vfs对象
VFS采用了面向对象的设计思路,将一系列概念抽象出来作为对象而存在,它们包含数据的同时也包含了操作这些数据的方法。当然,这些对象都只能用数据结构来表示,而不可能超出C语言的范畴,不过即使在C++里面数据结构和类的区别也仅仅在于类的成员默认私有,数据结构的成员默认公有。VFS主要有如下4个对象类型。
(1)超级块(struct super_block)。超级块对象代表一个己安装的文件系统,存储该文件系统的有关信息,比如文件系统的类型、大小、状态等。对基于磁盘的文件系统,这类对象通常存放在磁盘上的特定扇区。对于并非基于磁盘的文件系统(比如基于内存的文件系统sysfs),它们会现场创建超级块对象并将其保存在内存中。
(2)索引节点(struct inode)。索引节点对象代表存储设备上的一个实际的物理文件,存储该文件的有关信息。Linux将文件的相关信息,比如访问权限、大小、创建时间等信息,与文件本身区分开来。文件的相关信息又被称为文件的元数据。
(3)目录项(struct dentry)。目录项对象描述了文件系统的层次结构,一个路径的各个组成部分,不管是目录(VFS将目录当作文件来处理)还是普通的文件,都是一个目录项对象。比如,打开文件/home/test/test.c时,内核将为目录/、home、test和文件test.c都创建一个目录项对象。
(4)文件(struct file)。文件对象代表已经被进程打开的文件,主要用于建立进程和文件之间的对应关系。它由open()系统调用创建,由close()系统调用销毁,且仅当进程访问文件期间存在于内存之中。同一个物理文件可能存在多个对应的文件对象,但其对应的索引节点对象却是惟一的。
除了上述4个主要对象外,VFS还包含了其他很多对象,比如用于描述各种文件系统类型的struct file_system_type,用于描述文件系统安装点的struct vfsmount等。
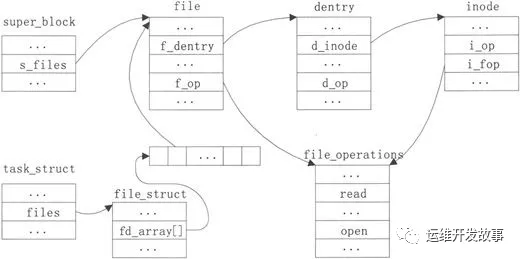
VFS各个对象间的关系不是孤立的,进程描述符的files字段记录了进程打开的所有文件,这些文件的文件对象指针保存在struct file_struct的fd_array数组里。通过文件的file对象可以获得它对应的目录项对象,再由目录项对象的d_inode字段可以获得它的inode对象,这样就建立了文件对象与物理文件之间的关联。一个文件被打开的时候,它的file对象是使用dentry、inode、vfsmount对象中的信息填充的,比如它对应的文件操作f_op由inode对象的i_fop字段得到。
文件系统的挂载
内核是不是支持某种类型的文件系统,需要我们进行注册才能知道。例如,咱们的 ext4 文件系统,就需要通过 register_filesystem 进行注册,传入的参数是 ext4_fs_type,表示注册的是 ext4 类型的文件系统。这里面最重要的一个成员变量就是 ext4_mount。记住它,这个我们后面还会用。
- 如果一种文件系统的类型曾经在内核注册过,这就说明允许你挂载并且使用这个文件系统。
- register_filesystem(&ext4_fs_type);
- static struct file_system_type ext4_fs_type = {
- .owner = THIS_MODULE,
- .name = "ext4",
- .mount = ext4_mount,
- .kill_sb = kill_block_super,
- .fs_flags = FS_REQUIRES_DEV,
- };
ext4文件系统的挂载是通过ext4_mount完成的,后者调用mount_bdev(block device)实现,mount_bdev判断两次挂载是否为同一个文件系统的依据是:是否为同一个块设备(test_bdev_super),也就是同一个块设备只有一个super_block与之对应,即使挂载多次。
- static struct dentry *ext4_mount(struct file_system_type *fs_type, int flags,
- const char *dev_name, void *data)
- {
- return mount_bdev(fs_type, flags, dev_name, data, ext4_fill_super);
- }
- struct dentry *mount_bdev(struct file_system_type *fs_type,
- int flags, const char *dev_name, void *data,
- int (*fill_super)(struct super_block *, void *, int))
- {
- struct block_device *bdev;
- struct super_block *s;
- fmode_t mode = FMODE_READ | FMODE_EXCL;
- int error = 0;
- if (!(flags & MS_RDONLY))
- mode |= FMODE_WRITE;
- 获取设备
- bdev = blkdev_get_by_path(dev_name, mode, fs_type);
- if (IS_ERR(bdev))
- return ERR_CAST(bdev);
- /*
- * once the super is inserted into the list by sget, s_umount
- * will protect the lockfs code from trying to start a snapshot
- * while we are mounting
- */
- mutex_lock(&bdev->bd_fsfreeze_mutex);
- if (bdev->bd_fsfreeze_count > 0) {
- mutex_unlock(&bdev->bd_fsfreeze_mutex);
- error = -EBUSY;
- goto error_bdev;
- }
- s = sget(fs_type, test_bdev_super, set_bdev_super, flags | MS_NOSEC,
- bdev);
- mutex_unlock(&bdev->bd_fsfreeze_mutex);
- if (IS_ERR(s))
- goto error_s;
- if (s->s_root) {
- if ((flags ^ s->s_flags) & MS_RDONLY) {
- deactivate_locked_super(s);
- error = -EBUSY;
- goto error_bdev;
- }
- /*
- * s_umount nests inside bd_mutex during
- * __invalidate_device(). blkdev_put() acquires
- * bd_mutex and can't be called under s_umount. Drop
- * s_umount temporarily. This is safe as we're
- * holding an active reference.
- */
- up_write(&s->s_umount);
- blkdev_put(bdev, mode);
- down_write(&s->s_umount);
- } else {
- s->s_mode = mode;
- snprintf(s->s_id, sizeof(s->s_id), "%pg", bdev);
- sb_set_blocksize(s, block_size(bdev));
- error = fill_super(s, data, flags & MS_SILENT ? 1 : 0);
- if (error) {
- deactivate_locked_super(s);
- goto error;
- }
- s->s_flags |= MS_ACTIVE;
- bdev->bd_super = s;
- }
- return dget(s->s_root);
- error_s:
- error = PTR_ERR(s);
- error_bdev:
- blkdev_put(bdev, mode);
- error:
- return ERR_PTR(error);
- }
挂载ext4文件系统最终由ext4_fill_super完成,它会读取磁盘中的ext4_super_block,创建并初始化ext4_sb_info对象,建立它们和super_block的关系。ext4_sb_info的结构如下:
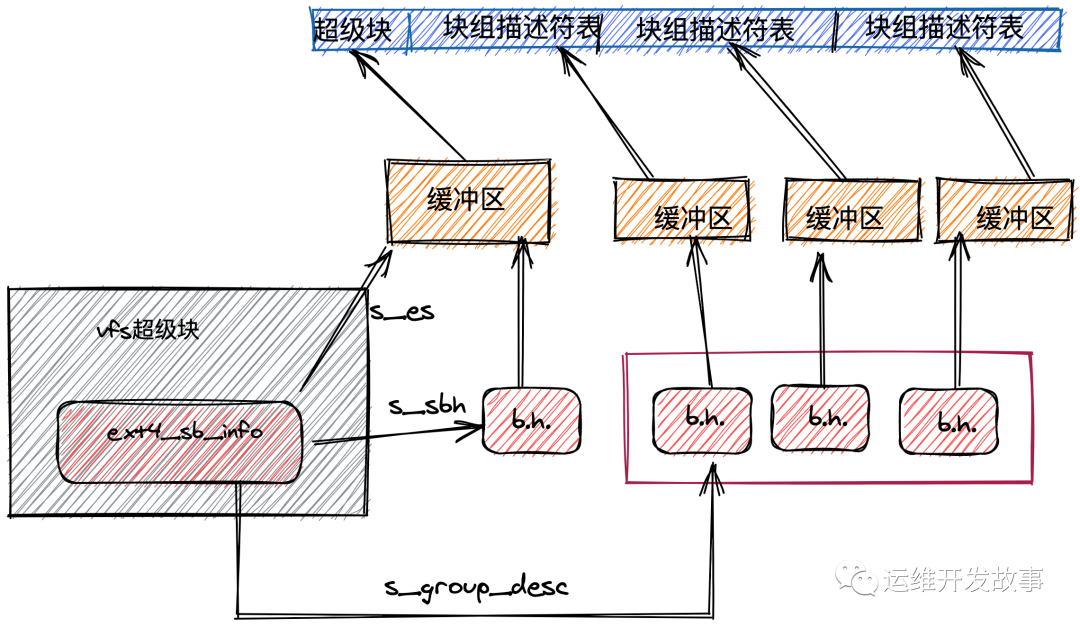
它的实现比较复杂,主要逻辑如下:
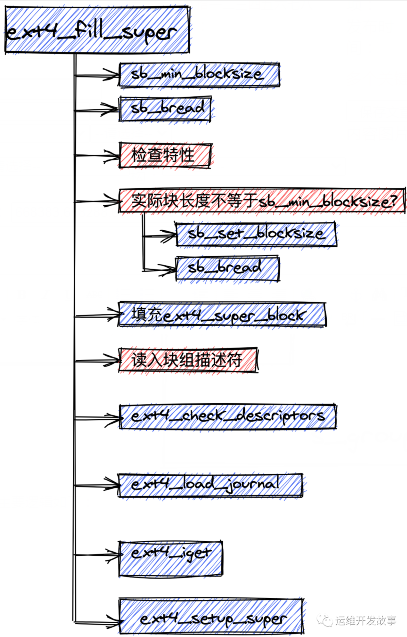
ext4_sb_info的建立是在ext4_fill_super函数中完成的,代码如下:
- struct ext4_sb_info {
- struct buffer_head * s_sbh; /* Buffer containing the super block */
- struct ext4_super_block *s_es; /* Pointer to the super block in the buffer */
- struct buffer_head **s_group_desc;
- };
- static int ext4_fill_super(struct super_block *sb, void *data, int silent)
- {
- struct ext4_sb_info *sbi;
- struct buffer_head *bh;
- struct ext4_super_block *es = NULL;
- //1
- bh = sb_bread_unmovable(sb, logical_sb_block)
- //2
- es = (struct ext4_super_block *) (bh->b_data + offset);
- sbi->s_sbh = bh;
- sbi->s_es = es;
- sb->s_fs_info = sbi;
- sbi->s_sb = sb;
- //3
- blocks_count = (ext4_blocks_count(es) -
- le32_to_cpu(es->s_first_data_block) +
- EXT4_BLOCKS_PER_GROUP(sb) - 1);
- do_div(blocks_count, EXT4_BLOCKS_PER_GROUP(sb));
- sbi->s_groups_count = blocks_count;
- sbi->s_blockfile_groups = min_t(ext4_group_t, sbi->s_groups_count,
- (EXT4_MAX_BLOCK_FILE_PHYS / EXT4_BLOCKS_PER_GROUP(sb)));
- db_count = (sbi->s_groups_count + EXT4_DESC_PER_BLOCK(sb) - 1) /
- EXT4_DESC_PER_BLOCK(sb);
- sbi->s_group_desc = ext4_kvmalloc(db_count *
- sizeof(struct buffer_head *),
- GFP_KERNEL);
- for (i = 0; i < db_count; i++) {
- block = descriptor_loc(sb, logical_sb_block, i);
- sbi->s_group_desc[i] = sb_bread_unmovable(sb, block);
- }
- //4
- if (!ext4_check_descriptors(sb, logical_sb_block, &first_not_zeroed)) {
- ret = -EFSCORRUPTED;
- goto error;
- }
- //5
- root = ext4_iget(sb, EXT4_ROOT_INO);
- //6
- if (ext4_setup_super(sb, es, sb->s_flags & MS_RDONLY))
- sb->s_flags |= MS_RDONLY;
- if (sbi->s_inode_size > EXT4_GOOD_OLD_INODE_SIZE) {
- sbi->s_want_extra_isize = sizeof(struct ext4_inode) -
- EXT4_GOOD_OLD_INODE_SIZE;
- if (ext4_has_feature_extra_isize(sb)) {
- if (sbi->s_want_extra_isize <
- le16_to_cpu(es->s_want_extra_isize))
- sbi->s_want_extra_isize =
- le16_to_cpu(es->s_want_extra_isize);
- if (sbi->s_want_extra_isize <
- le16_to_cpu(es->s_min_extra_isize))
- sbi->s_want_extra_isize =
- le16_to_cpu(es->s_min_extra_isize);
- }
- ext4_set_resv_clusters(sb);
- err = ext4_setup_system_zone(sb);
- ext4_ext_init(sb);
- err = ext4_mb_init(sb);
- block = ext4_count_free_clusters(sb);
- ext4_free_blocks_count_set(sbi->s_es,
- EXT4_C2B(sbi, block));
- err = percpu_counter_init(&sbi->s_freeclusters_counter, block,
- GFP_KERNEL);
- if (!err) {
- unsigned long freei = ext4_count_free_inodes(sb);
- sbi->s_es->s_free_inodes_count = cpu_to_le32(freei);
- err = percpu_counter_init(&sbi->s_freeinodes_counter, freei,
- GFP_KERNEL);
- }
- err = percpu_counter_init(&sbi->s_dirs_counter,
- ext4_count_dirs(sb), GFP_KERNEL);
- err = percpu_counter_init(&sbi->s_dirtyclusters_counter, 0,
- GFP_KERNEL);
- err = percpu_init_rwsem(&sbi->s_journal_flag_rwsem);
- return 0;
- }
ext4_fill_super主要分六步,均用标号标出。
第1步,读取ext4_super_block对象,此时并不知道文件系统的block大小,也不知道它起始于第几个block,只知道它起始于磁盘的第1024字节(前1024字节存放x86启动信息等)。所以在第1步中先给定一个假设值,一般假设block大小为1024字节,ext4_super_block始于block 1(sb_block)。由sb_min_blocksize计算得到的block大小如果小于1024,就以它作为新的block大小得到block号logical_sb_block和block内的偏移量offset。读取logical_sb_block的内容,加上计算得到的偏移量,得到的就是ext4_super_block对象(es),但因为block大小可能小于1024,所以有可能读到的只是ext4_super_block的一部分,所以为了保险起见,接下来只能访问它的一部分字段,主要是一些简单的验证工作。所幸s_log_block_size字段的偏移量0x18并不大,步骤1完成后,可以得到实际的block大小(2^(10+s_log_block_size))。
第2步,block大小最小为1024,最大为65536,我的磁盘中为4096,所以步骤2中会重新计算logical_sb_block和offset分别为0和1024。然后读取block 0,得到的数据加上1024就是完整的ext4_super_block对象。
第3步,根据得到es为ext4_sb_info字段赋值,代码段中保留了s_group_desc字段的赋值过程,其余字段省略。
第4步,检查所有的group descriptors数据的合法性,初始化flex_bg相关的信息。
第5步,调用ext4_iget获取ext4的root文件,并调用d_make_root创建对应的dentry,为sb->s_root赋值。
第6步,调用ext4_setup_super,将控制权转移到ext4_setup_super,它将进行几项最后的检查并输出适当的警告信息。最后将超级快的变更内容写回到磁盘上,更新挂载计数器和上一次挂载的日期。
这样就将磁盘挂载到linux的VFS文件文件系统中了。其中,file_system_type用于描述具体文件系统的类型,struct vfsmount用于描述一个文件系统的安装实例。Linux所支持的文件系统,都会有且仅有一个file_system_type结构(比如,Ext2对应ext2_fs_type,Ext3对应ext3_fs_type,Ext4对应ext4_fs_type),而不管它有零个或多个实例被安装到系统中。每当一个文件系统被安装时,就会有一个vfsmount结构被创建,它代表了该文件系统的一个安装实例,也代表了该文件系统的一个安装点。下图是超级块、安装点和具体的文件系统之间的关系。不同类型的文件系统通过next字段形成一个链表,同一种文件系统类型的超级块通过s_instances字段链接在一起,并挂入fs_supers链表中。

关于ext4还有很多内容,源码链接:https://elixir.bootlin.com/linux/v4.8/source/fs/ext4/,有兴趣的大家可以去看看。
恢复删除的文件并不神秘
存储介质上的数据可以分为两部分:表征文件的数据(可以称为元数据,metadata)和文件的内容。不仅仅ext4文件系统如此,多数基于磁盘的文件系统都离不开这两部分。为了恢复删除的文件,需要先了解删除的数据属于哪个类型,多数文件系统删除的是文件的信息,也就是表示文件和它所属目录的关系、文件本身信息的数据,至于文件的内容,一般是不会覆盖的。这么做最大的优点是效率高,比如我们在ext4文件系统中,删除一个几个G字节大小的文件并不会比删除几个字节的文件所用的时间长很多。缺点也是明显的,就是所谓的删除并没有对文件的内容造成影响,只要没有被后续的文件覆盖,就有被恢复的可能,有安全的风险。














