【51CTO.com快译】发现应用程序内存不足是开发者遇到的糟糕问题之一。内存问题一般很难加以诊断和修复,而在Python中尤为困难。Python的自动垃圾收集让您易于上手该语言,但出现问题时,开发者不知道如何识别和修复问题。
本文介绍如何诊断和修复开源AutoML库EvalML中的内存问题。解决内存问题没什么诀窍,但我希望开发者、尤其是Python开发者可以了解将来遇到这类问题时可利用的工具和优秀实践。
什么是内存泄漏?
任何编程语言最重要的功能之一是能够将信息存储在计算机内存中。每当您的程序创建一个新变量,它都会分配一些内存用于存储该变量的内容。
内核为程序访问计算机的CPU、内存和磁盘存储等资源定义了接口。每种编程语言提供了要求内核分配和释放内存块供运行中的程序使用的方法。
程序要求内核留出内存块供使用,但随后由于错误或崩溃,程序完成使用该内存后从未告诉内核,就会发生内存泄漏。在这种情况下,内核将继续认为被遗忘的内存块仍被运行中的程序使用,其他程序无法访问这些内存块。
如果运行程序时同样的泄漏一再发生,被遗忘的内存总量会变得很庞大,因而消耗计算机的大部分内存!在这种情况下,如果程序随后尝试请求更多内存,内核会抛出“内存不足”错误,程序将停止运行,换句话说“崩溃”。
因此,找到并修复所编写的程序中的内存泄漏很重要,否则程序最终可能会耗尽内存并崩溃,或者可能导致其他程序崩溃。
第1步:确定是内存问题
应用程序崩溃的原因有很多:也许运行代码的服务器崩溃了,也许代码本身存在逻辑错误,所以确定眼前的问题是内存问题很重要。
EvalML性能测试悄然崩溃。突然,服务器停止记录进度,作业悄然停止。服务器日志会显示编程错误引起的任何堆栈追踪,所以我有预感:崩溃是作业耗用所有的可用内存引起的。
我又重新进行了性能测试,但这次启用了Python的内存分析器,以获取内存使用情况图。测试再次崩溃,当我查看内存图时,发现了该图:
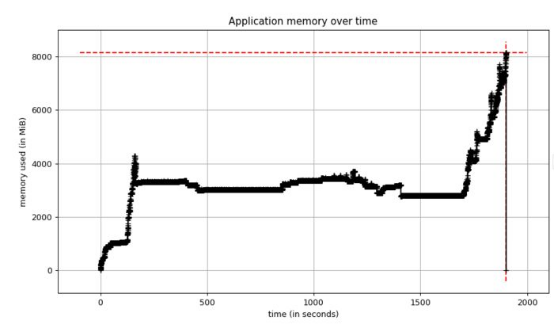
图1.性能测试的内存使用情况
内存使用情况逐渐保持稳定,但随后达到8 GB!我知道应用服务器有8GB 的内存,所以该图证实我们耗尽了内存。此外,内存稳定时,我们使用约4 GB的内存,但之前版本的EvalML使用约2 GB的内存。由于某种原因,当前版本使用的内存是平常的大约两倍。
现在需要找出原因。
第2步:用极简示例在本地重现内存问题
查明内存问题的原因需要大量实验和迭代,因为答案通常并不明显。如果是这样,您可能不会将其写入代码!出于这个原因,我认为用尽可能少的代码行重现问题很重要。这个极简示例使您可以在修改代码时在分析器下快速运行它,查看是否取得进展。
我凭经验知道,大概在我看到大峰值时,应用程序运行含有150万行的出租车数据集。我将应用程序精简至仅运行该数据集的部分。我看到了类似上述的峰值,但这次内存使用量达到了10 GB!
见此情形,我知道有一个足够好的极简示例可深入研究。
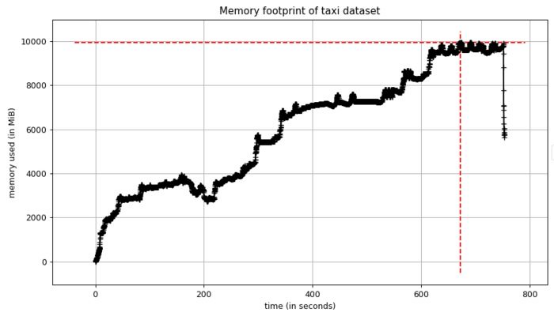
图2. 出租车数据集本地重现的内存使用情况
第3步:找到分配最多内存的代码行
一旦将问题隔离到尽可能小的代码块,我们可以看到程序在何处分配最多的内存。这便于您重构代码和修复问题。
filprofiler是个出色的Python工具。它显示应用程序中每一行代码在内存使用高峰时的内存分配情况。这是本地示例的输出结果:
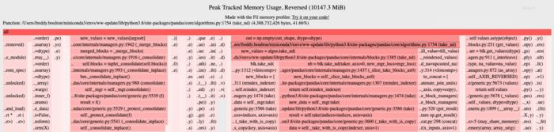
图3. fil-profile的输出
filprofiler根据内存分配情况对应用程序中的代码行(以及依赖项的代码)进行排名。线越长越红,分配的内存越多。
分配最多内存的代码行用来创建pandas数据帧(pandas/core/algorithms.py和pandas/core/internal/managers.py),数据量达4GB!我在这里截断了filprofiler的输出,但它能够将pandas代码追溯到用EvalML来创建Pandas数据帧的代码。
是的,EvalML创建Pandas数据帧,但这些数据帧在整个AutoML算法中都是短暂的,一旦不再使用就应该被释放。由于实际情况并非如此,加上这些数据帧在内存中的时间足够长,我认为最新版本带来了内存泄漏。
第4步:识别泄漏对象
在Python中,泄漏对象是使用完成后没有被Python的垃圾收集器释放的对象。由于 Python使用引用计数作为主要的垃圾收集算法之一,这些泄漏对象通常是由对象占有引用时间过长引起的。
这类对象很难找到,但可以用一些Python工具简化搜寻。第一个工具是垃圾收集器的gc.DEBUG_SAVEALL标志。若设置该标志,垃圾收集器将无法访问的对象存储在gc.garbage列表中。这让您可以进一步研究这些对象。
第二个工具是objgraph库。一旦对象在gc.garbage列表中,我们可以根据pandas数据帧过滤该列表,并使用objgraph查看哪些其他对象引用这些数据帧、将它们保存在内存中。
这是我在可视化其中一个数据帧后看到的对象图的一个子集:
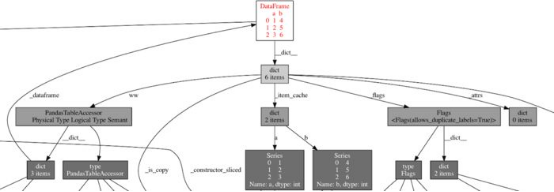
图4. Pandas数据帧使用内存图,显示导致内存泄漏的循环引用
这就是我要找的确凿证据!数据帧通过创建循环引用的PandasTableAccessor对自身进行引用,因此这会将对象保留在内存中,直到Python的垃圾收集器运行并释放它。(可以通过dict、PandasTableAccessor、dict和_dataframe 追踪循环。)这对EvalML来说有问题,因为垃圾收集器将这些数据帧保存在内存中的时间太长,以至于我们耗尽内存!
我能够将PandasTableAccessor追溯到Woodwork库,并将该问题提交给维护者。他们在新版本中修复后,向pandas存储库提交了相关的问题单,这个例子表明了开源生态系统中的合作。
Woodwork更新发布后,我可视化同一个数据帧的对象图,循环消失了!
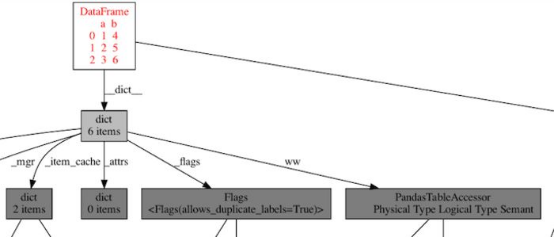
图5.woodwork升级后pandas数据帧的对象图。不再有循环!
第5步:验证修复是否有效
我在EvalML中升级Woodwork 版本后,测量了应用程序的内存使用情况。结果发现,内存使用量现在不到过去的一半!
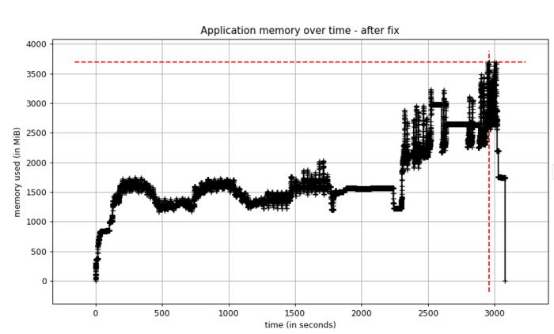
图6. 修复后性能测试的内存使用情况
原文标题:How to troubleshoot memory problems in Python,作者:Freddy Boulton
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】