













Greenplum属于一种看起来“较重”的数据库MPP架构,不像基于MySQL基于中间件的架构那么轻量,但是要说一些具体的场景,比如Greenplum支持存储过程,支持列式存储,加上分区表和内置的数据分片等多种模式,都是典型的OLAP场景,术业有专攻还是有一定道理的。
最近因为业务需求和改造需要部署几套GP集群,总体来说也是需要解决以前的一些顽疾并加以改进,运行几个上百节点的集群还是有一定的压力的,不过前几年在飞祥同学的劳动成果之上,整个集群还是比较稳定的,在运行中也发现了一些额外的问题和痛点。
1)之前的GP segment数量设计过度,因为资源限制,过多考虑了功能和性能,对于集群的稳定性和资源平衡性考虑有所欠缺,在每个物理机节点上部署了10个Primary,10个Mirror,导致一旦出现Segment节点不可用,对于整个集群的稳定性会是一个大的隐患,最尴尬的莫过于一个Segment节点不可用,另外一个Segment节点负载过高,最后集群不可用,所幸这种情况暂未出现
2)GP集群的存储资源和性能的平衡不够。GP存储对标基本都是百TB,相对来说和我们所说的大数据体系的PB还是有很大差异的,GP里面计算的数据总体都是比较重要,而且总体的存储容量不会特别大,磁盘现在有8T的规格,如果放12块盘,则RAID-5会有近70多T的存储空间,而RAID-10则有48T左右的空间,如果RAID-5同时坏了2块盘就尴尬了,但是对于RAID-10来说还是有转机的,这个情况之前碰到过一次,在替换一块坏盘的时候,工程师发现另外一块盘也快坏了,RAID-5要一块一块的换,当时还因为这个熬了个通宵,想了很多预案,说了这么多是想表达,GP存储的容量不用那么大,如果在损失一定存储容量的基础上能够最大程度降低隐患是很划算的,所以在存储容量和性能的综合之上,我们是选择了RAID-10
3)集群的验收和保障工作补充。如果一个GP集群用过很长一段时间就会发现启停都是一个大工程,之前启停要耗时半个小时,让小心脏压力很大。 这个过程中也发现了以前遗漏了一些环节,比如性能压测,导致不太确定整个集群的支撑能力到底如何。
在此基础上,还需要额外考虑如下的一些因素:
1)集群的跨机房迁移如何做到平滑,或者影响最低,之前一次机房搬迁,导致IP变化后的集群无法启动,当时真是吓坏了,因为在这种问题面前,就是0和1的博弈,如果是0就意味着数据都丢弃了,所以在这方面还是需要做一些扎实的铺垫。
2)服务器后续过保要做硬件替换,如何能够实现滚动替换,这是在已有的基础之上需要前瞻考虑的重要点,几年后的服务器过保如何应对,如果有了可靠的方案,以后也会从容一些。
3)GP的版本和基础环境需要同步升级,比如我们目前的主流操作系统为CentOS7,如果继续使用CentOS 6就不应该了,同时对于GP的版本也需要重新评估,在较新版本和稳定版本之间进行平衡。
整个GP集群的部署架构如下:
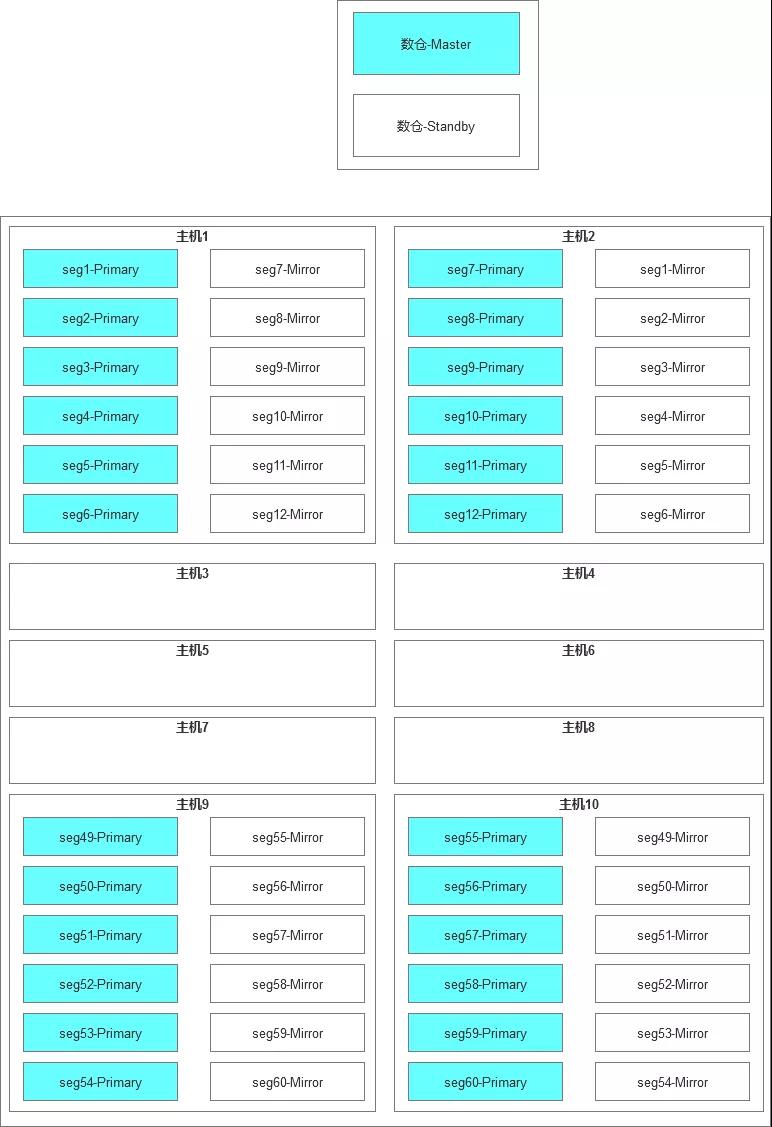
Greenplum是我知道的数据库中的角色最完整的。Master,Standby,Primary,Mirror,各种数据库中的不同角色在这里有一套完整的体系命名。
新的这一套环境注定在我手中构建,所以我希望完善以下的一些细节。
1)Greenplum的版本选择,目前有两个主要的版本类别,一个是开源版(Open Source distribution)和Pivotal官方版,它们的其中一个差异就是官方版需要注册,签署协议,在此基础上还有GPCC等工具可以用,而开源版本可以实现源码编译或者rpm安装,无法配置GPCC。综合来看,我们选择了开源版本的6.16.2,这其中也询问了一些行业朋友,特意选择了几个涉及稳定性bug修复的版本。
2)GP的容量规划,这一次经过讨论是选择了折中的配置,即(6+6)*10+2,具体解释就是一共12台服务器,其中有10台服务器是Segment节点,每台上面部署了6个Primary,6个Mirror,另外2台部署了Master和Standby
3)内核参数的配置和调整
除了基础的kernel.shmmax和kernel.shmall配置之外,还有如下的一些配置需要调整:
vm.swappiness=10
vm.zone_reclaim_mode = 0
vm.dirty_expire_centisecs = 500
vm.dirty_writeback_centisecs = 100
vm.dirty_background_ratio = 0 # See System Memory
vm.dirty_ratio = 0
vm.dirty_background_bytes = 1610612736
vm.dirty_bytes = 4294967296
vm.min_free_kbytes = 3943084
vm.overcommit_memory=2
kernel.sem = 500 2048000 200 4096
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
集群部署的大体流程:
1)首先是配置/etc/hosts,需要把所有节点的IP和主机名都整理出来。
2)配置用户,很常规的步骤
groupadd gpadmin
useradd gpadmin -g gpadmin
passwd gpadmin
- 1.
- 2.
- 3.
3)配置sysctl.conf和资源配置
4)使用rpm模式安装
yum install -y apr apr-util bzip2 krb5-devel zip
# rpm -ivh open-source-greenplum-db-6.16.2-rhel7-x86_64.rpm
Preparing... ################################# [100%]
Updating / installing...
1:open-source-greenplum-db-6-6.16.2################################# [100%]
- 1.
- 2.
- 3.
- 4.
- 5.
5)配置两个host文件,也是为了后面进行统一部署方便,在此建议先开启gpadmin的sudo权限,可以通过gpssh处理一些较为复杂的批量操作
6)通过gpssh-exkeys来打通ssh信任关系,这里需要吐槽这个ssh互信,端口还得是22,否则处理起来很麻烦
gpssh-exkeys -f hostlist
- 1.
7)较为复杂的一步是打包master的Greenplum-db-6.16.2软件,然后分发到各个segment机器中,整个过程涉及文件打包,批量传输和配置,可以借助gpscp和gpssh,比如gpscp传输文件,如下的命令会传输到/tmp目录下
gpscp -f /usr/local/greenplum-db/conf/hostlist /tmp/greenplum-db-6.16.2.tar.gz =:/tmp
- 1.
8)Master节点需要单独配置相关的目录,而Segment节点的目录可以提前规划好,比如我们把Primary和Mirror放在不同的分区。
mkdir -p /data1/gpdata/gpdatap1
mkdir -p /data1/gpdata/gpdatap2
mkdir -p /data2/gpdata/gpdatam1
mkdir -p /data2/gpdata/gpdatam2
- 1.
- 2.
- 3.
- 4.
9)整个过程里最关键的就是gpinitsystem_config配置了,因为Segment节点的ID配置和命名,端口区间都是根据一定的规则来动态生成的,所以对于目录的配置需要额外注意。
10)部署GP集群最关键的命令是
gpinitsystem -c gpinitsystem_config -s 【standby_hostname】
整个过程大约5分钟~10分钟以内会完成。
在此也走了不少弯路,比如一些配置不完整,防火墙权限不够,导致部署的时候界面卡在那里,
比如其中一个问题,/etc/hosts 配置不全 导致Primary可以启动,但是Mirror无法启动,问题看起来很奇怪,而且从GP的日志里面的信息也很简略,如果难以定位,还可以直接到相应的Segment节点上查看相应的日志,查看日志是个技术活,如果出现卡顿,不要干等着,得看看后端到底在哪个环节卡住了,需要同步查看日志的刷新来进行问题的定位和修正,在这方面GP的一些安装体验还是比较粗糙的。
安装部署这件事,就像一个无形的门槛,只要自己做过一次,相信这些步骤都很简单,反之就像一座绕不开的大山,始终绕不过去,对于安装部署,最全面的文档还是官方文档。























