












腾讯面试官:说说Redis的哈希表是如何扩容的?
面试者:what?额......,(我懵了!)这个我还没了解过,尬...。但我了解java里面的HashMap的扩容,我觉得应该有相通的一些原理在里面吧,然后我就把HashMap的扩容机制balabla的说了一遍......
Redis中使用哈希表作为底层实现的是叫做字典的数据结构,字典又称为符号表、关联数组或映射(map)。是一种保存键值对的抽象数据结构。
如果你对Java HashMap有所了解的话,那么Redis哈希表就是类似Java中HashMap。
由于Redis是用C语言写的,所以要搞懂C的相关实现原理去看源码的话就要对C语言有一定的了解。
目录
1、哈希表结构
哈希表例子
2、字典数据结构
字典例子
3、解决哈希冲突
4、扩容/缩容——rehash
4.1、对字典的哈希表rehash步骤
4.2、看一次哈希表rehash扩容过程
5、渐进式rehash
5.1、渐进式rehash步骤
5.2、看下一次完整的渐进式rehash扩容的过程
6、总结
01哈希表结构

哈希表是由dictht结构体定义,table是一个数组,数组中每个元素是一个指向dictEntry结构的指针。

dictEntry是哈希表的节点,每个节点保存着一个键值对key、value,value可以是一个指针、或者是一个unit64_t或int64_t整数。
next属性则是一个指向另一个哈希表节点的指针,形成一个链表,主要也是为了解决哈希冲突问题。
哈希表例子
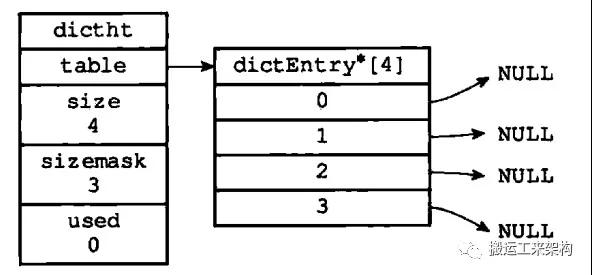
一个空的哈希表
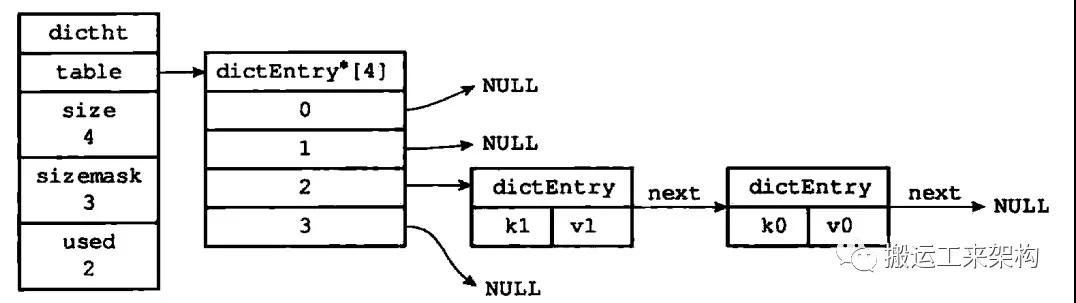
索引值相同的两个节点使用链表连接起来
02字典数据结构
其实说到哈希表的话顺便要了解下字典这种数据结构,毕竟它的底层就是哈希表来实现,可以了解下扩容缩容相关的。


type:指向dictType指针,保存了操作特定类型键值对的函数,Redis为不同用途的字典设置不同的类型特定函数。
privdata:保存了需要传递给不同特定函数的可选参数。
ht[2]:两个哈希表,字典使用的哈希表是ht[0],ht[1]则是当对ht[0]哈希表进行rehash时使用。
trehashidx:记录当前rehash进度,没有进行rehash则为-1。
字典例子
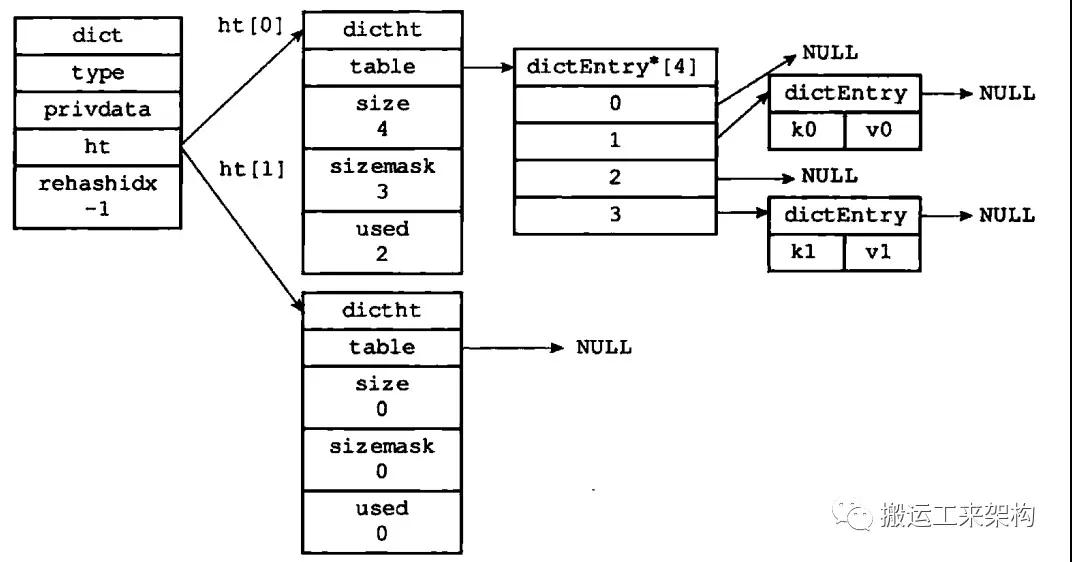
普通状态下的字典
03解决哈希冲突
将一个键值对添加到字典时,需要计算其哈希值和索引值,接着根据索引值将新节点放到哈希表数组的指定索引上。
计算哈希值:
- hash = dict->type->hashFunction(key)
计算索引值:
- hash & dict->ht[x].sizemask
键冲突:当两个或以上数量的键进行哈希之后索引值一样,也就是说两个节点要放在同一个同桶里,这时可能就会存在覆盖(冲突),那么就得解决这种冲突了。
Redis解决键冲突的方法:链地址法(separate chaining)——拉链法,假设你已了解Java HashMap原理,这里链地址法原理就不细说了。
插入一个题外话(也是笔者遇过的一道面试题):解决哈希冲突有什么方法?答案:①再哈希法;②链地址法;③开放地址法;④建立公共溢出区。(每种方法可以自行简单了解下即可)
04扩容/缩容——rehash
首先,我们要清楚为什么要进行扩容或缩容?
扩容原因:当hashtable存储的元素过多,可能由于碰撞也过多,导致其中某天链表很长,最后致使查找和插入时间复杂度很大。因此当元素超多一定的时候就需要扩容。
缩容原因:当元素数量比较少的时候就需要缩容以节约不必要的内存。
为了让哈希表的负载因子(load factor)维持在一个合理的范围内,会使用rehash(重新散列)操作对哈希表进行相应的扩展或收缩。
负载因子的计算公式:哈希表已保存节点数量 / 哈希表大小 load_factor = ht[0].used / ht[0].size
扩容的条件:(满足任一即可)
1)Redis服务器目前没有在执行BGSAVE或BGREWRITEAOF命令,并且哈希表的负载因子大于等于1。
2)Redis服务器目前在执行BGSAVE或BGREWRITEAOF命令,并且哈希表的负载因子大于等于5。
(此处为什么负载因子不同呢?)
缩容的条件:哈希表的负载因子小于0.1。
4.1、对字典的哈希表rehash步骤
1)为ht[1]分配空间
扩展操作,那么ht[1] 的大小为第一个大于等于ht[0] .used*2的2的n次幂
收缩操作,那么ht[1] 的大小为第一个大于等于ht[0].used 的2的n次幂
2)将ht[0]中的数据转移到ht[1]中,在转移的过程中,重新计算键的哈希值和索引值,然后将键值对放置到ht[1]的指定位置。
3)当ht[0]的所有键值对都迁移到了ht[1]之后(ht[0]变为空表),将ht[0]释放,然后将ht[1]设置成ht[0],最后为ht[1]分配一个空白哈希表:
4.2、看一次哈希表rehash扩容过程
1)开始rehash之前

2)为ht[1]分配空间,ht[0].used当前值为4,8恰好是第一个大于等于4的2的N次幂,那么当前就会将ht[1]哈希表大小设置为8。

3)将ht[0]的键值对都rehash到ht[1]
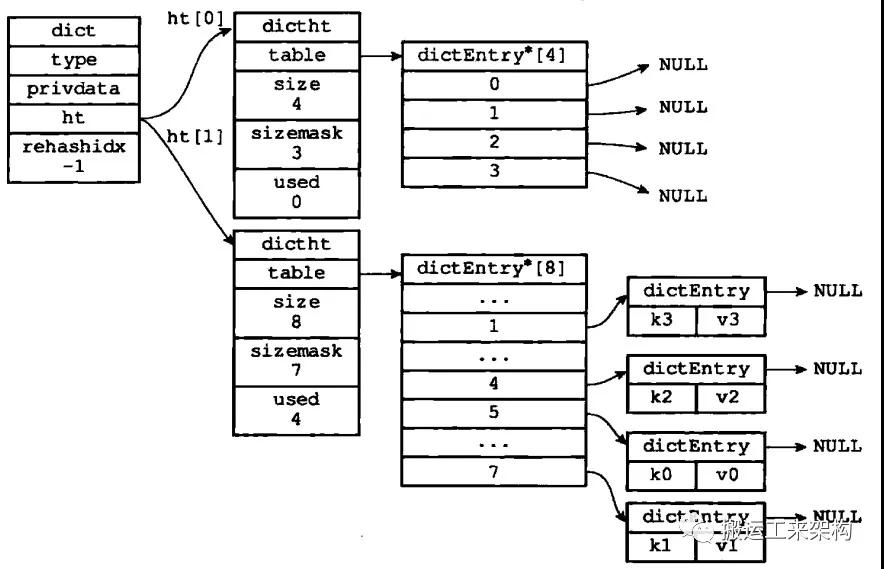
ht[0]键值对都已迁移到ht[1]
4)释放ht[0],将ht[1]设置为ht[0],ht[1]再设置为空的哈希表
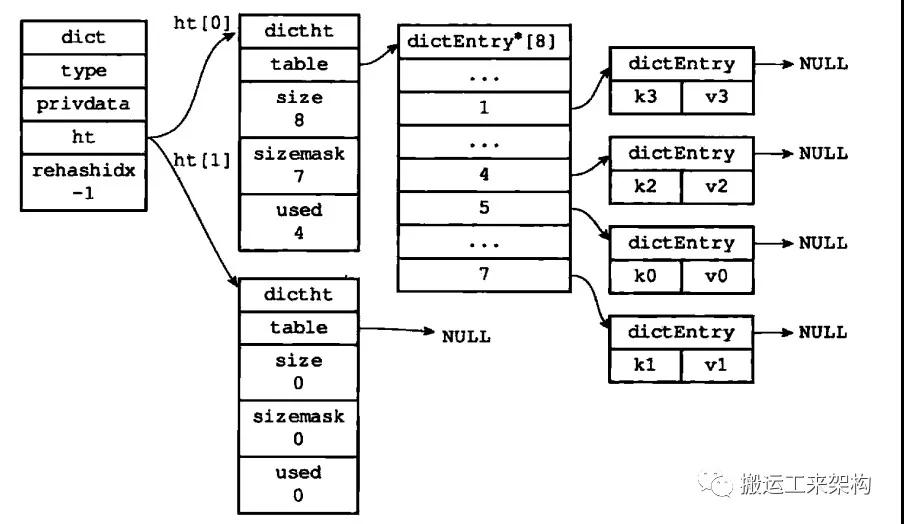
rehash扩容完成
为什么BGSAVE或BGREWRITEAOF命令是否在执行,Redis服务器哈希表执行扩容所需的负载因子不相同(1或5)?
因为当执行BGSAVE或BGREWRITEAOF命令过程中,Redis需要创建服务器进程的子进程,操作系统采用的是COW,即写时复制copy-on-write的技术来优化子进程的使用效率。所以在子进程存在时,服务器会提高执行扩容所需的负载因子,从而尽可能避免在子进程存在期间进行扩容,可以避免不必要的内存写入操作,最大限度节约内存。
05渐进式rehash
为什么需要渐进式rehash呢?
在元素数量较少时,rehash会非常快的进行,但是当元素数量达到几百、甚至几个亿时进行rehash将会是一个非常耗时的操作。如果一次性将成万上亿的元素的键值对rehash到ht[1],庞大的计算量可能会导致服务器在一段时间内停止服务,这是非常危险的!所以,rehash这个动作不能一次性、集中式的完成,而是分多次、渐进式地完成。
5.1、渐进式rehash步骤:
1)为ht[1]分配空间,让字典同时持有ht[0]和ht[1]两个哈希表。
2)在字典中维持一个索引计数器变量rehashidx,并将它的值设置为0,表示rehash工作正式开始。
3)在rehash进行期间,每次对字典执行CRUD:添加、删除、查找或者更新操作时,程序除了执行指定的操作以外,还会顺带将ht[0]哈希表在rehashidx索引上的所有键值对rehash到ht[1],当rehash工作完成之后,程序将rehashidx+1(表示下次将rehash下一个桶)。
4)随着字典操作的不断执行,最终在某个时间点上,ht[0]的所有键值对都会被rehash至ht[1],这时程序将rehashidx属性的值设为-1,表示rehash完成。
渐进式rehash的好处在于它采取分而治之的方式,将rehash键值对所需的计算工作均摊到对字典的每个添加、删除、查找和更新操作上,从而避免了集中式rehash 而带来的庞大计算量。
5.2、看下一次完整的渐进式rehash扩容的过程
1)准备进行渐进式rehash

准备rehash
2)此时rehashidx=0,也就是会将索引为0的键值对进行迁移
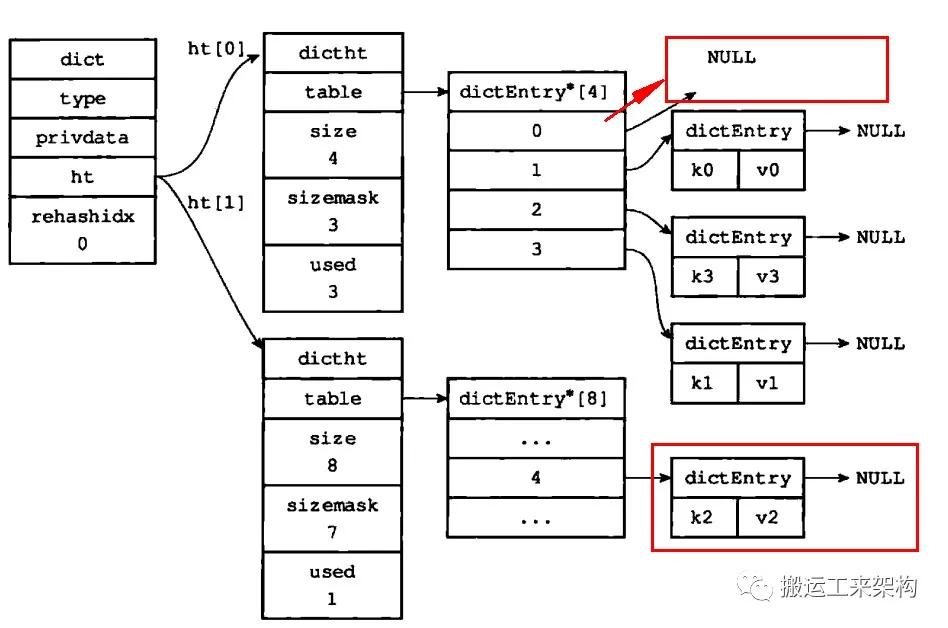
rehash索引0上的键值对
3)接着,rehashidx继续递增,假如到最后将索引3的进行迁移,如下:
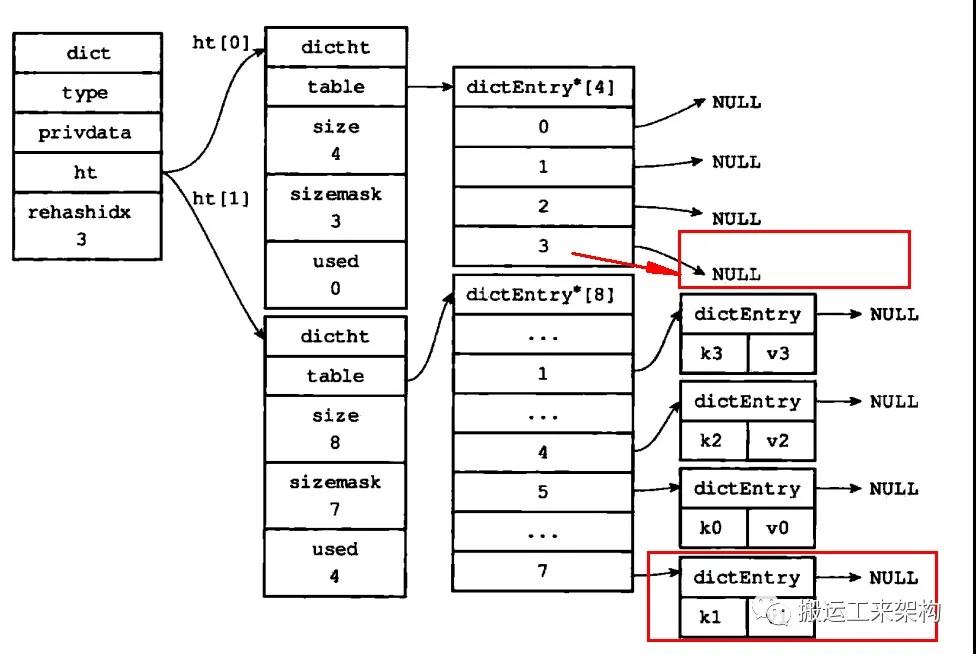
最后一次rehash,索引为3上的键值对进行迁移
4)渐进式rehash结束
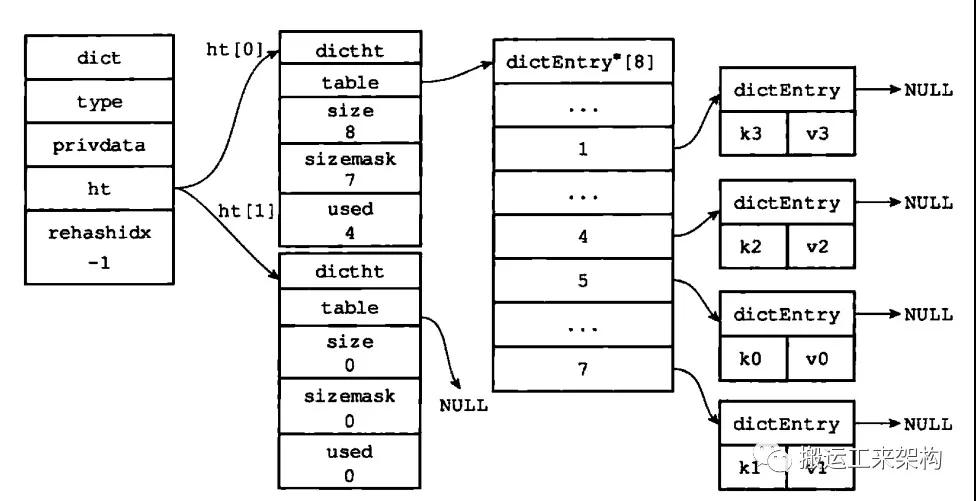
rehash结束
了解了渐进式rehash的原理和过程,那么可能会有下面这些疑问:
在迁移的过程中,会不会造成读少数据?
不会,因为在迁移时,首先会从ht[0]读取数据,如果ht[0]读不到,则会去ht[1]读。
在迁移过程中,新增加的数据会存放在哪个ht?
迁移过程中,新增的数据只会存在ht[1]中,而不会存放到ht[0],ht[0]只会减少不会新增。
06总结
1)字典被Redis广泛应用于各种功能,比如数据库和哈希键。
2)Redis字典底层是有哈希表实现,每个字典包含两个哈希表ht[0]、ht[1],ht[1]在rehash时才有作用。
3)哈希表使用链地址法解决哈希冲突,被分配到同一个索引的键值对会连接成一个单向链表。
4)哈希表进行rehash不是一次性完成,而是分多次、渐进式完成的。
5)哈希表rehash的条件:
扩容:(满足任一即可)
a)Redis服务器目前没有在执行BGSAVE或BGREWRITEAOF命令,并且哈希表的负载因子大于等于1。
b)Redis服务器目前在执行BGSAVE或BGREWRITEAOF命令,并且哈希表的负载因子大于等于5。
缩容:哈希表的负载因子小于0.1。
6)BGSAVE或BGREWRITEAOF命令是否在执行,Redis服务器哈希表执行扩容所需的负载因子不相同。因为此时子进程使用写时复制copy on write,需要占用一定的内存,所以需要提高扩容所需的负载因子,从而尽可能避免在子进程存在期间进行扩容,可以避免不必要的内存写入操作,最大限度节约内存。
了解了Redis字典哈希表扩容,那么你知道与Java ConcurrentHashMap(1.8)的扩容有什么不同吗?
也就是引出这个问题:
Redis的字典渐进式扩容与ConcurrentHashMap的扩容策略比较?那么他们在扩容、CRUD时有什么区别呢?
1)扩容所花费的时间对比
一个单线程渐进扩容,一个多线程协同扩容。在平均的情况下,是ConcurrentHashMap快。这也意味着,扩容时所需要
花费的空间能够更快的进行释放。
2)读操作,两者的性能相差不多。
3)写操作,Redis的字典返回更快些,因为它不像ConcurrentHashMap那样去帮着扩容(当要写的桶位已经搬到了newTable时),等扩容完才能进行操作,而redis则是直接将新加的元素添加到ht[1]。
4)删除操作,与写一样。
最后,我们应该选择单线程渐进式扩容还是选择多线程协同式扩容?具体问题具体分析:
1)如果内存资源吃紧,希望能够进行快速的扩容方便释放扩容时需要的辅助空间,且那么选择后者。
2)如果对于写和删除操作要求迅速,那么可以选择前者。
参考资料:
#1《redis设计与实现》
#2 https://blog.csdn.net/jiji1995/article/details/64127460
#3 https://blog.csdn.net/u010710458/article/details/80604740
#4 源码分析:https://www.jianshu.com/p/a57a6e389a03























