与人类自然的从「想到」到「说出」模式相比,当前最先进的语音转换系统也很慢。
当前顶尖的NLP系统还在努力跟上人类的思维速度。
比如,与谷歌助手或Alexa虚拟助手互动时,通常停顿时间会比你预期的长,不能实现与真实的人交谈的流畅度。
AI需要时间处理你的语音,它要确定每个单词对它来说意味着什么,是否在它的能力范围之内,然后找出哪些软件包或程序可以访问和部署,最后再输出理解结果。
从宏观的角度来看,这些基于云计算的系统运行速度已经很快了,但仍然不足以给不会说话的人创造一个无缝接口,让他们以思维的速度「发出声音」。
从鸟鸣研究开始
「鸣鸟」(一种鸟)是研究复杂「发声行为」的一个很有吸引力的模型。
鸟鸣与人类语言有许多独特的相似之处,对它的研究使人们对学习、执行和维持发声运动技能背后的多种机制和电路有了普遍的认识。
此外,产生鸟鸣的生物力学与人类和一些非人类灵长类动物有相似之处。
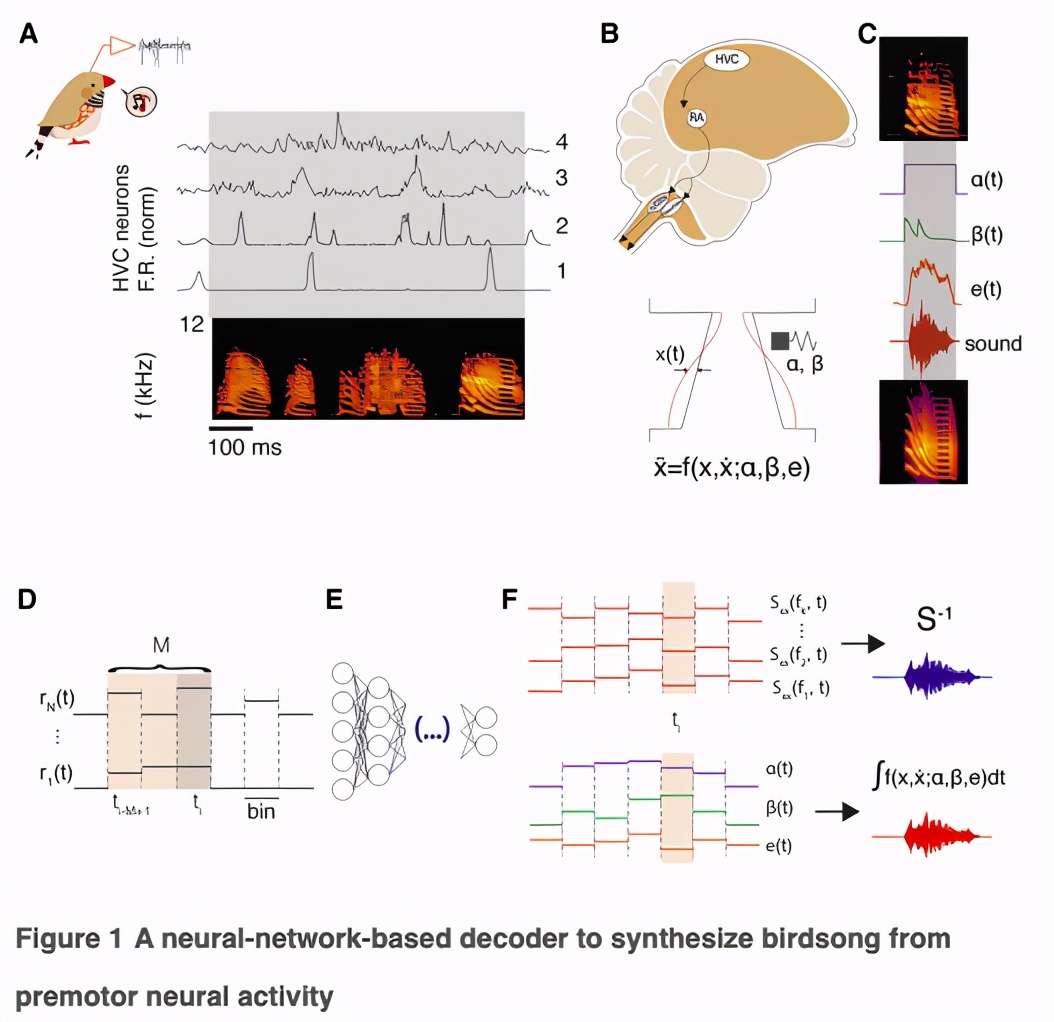
在这项新的研究中,研究小组在12只斑胸草雀的大脑中植入电极 ,然后开始记录它们唱歌。
但是仅仅训练人工智能识别鸟鸣时的神经活动是不够的,即使是鸟类的大脑也太过复杂,无法完整地描绘出神经元之间的交流方式。
因此,研究人员训练了另一个系统,将实时歌曲减少到AI可以识别的模式。
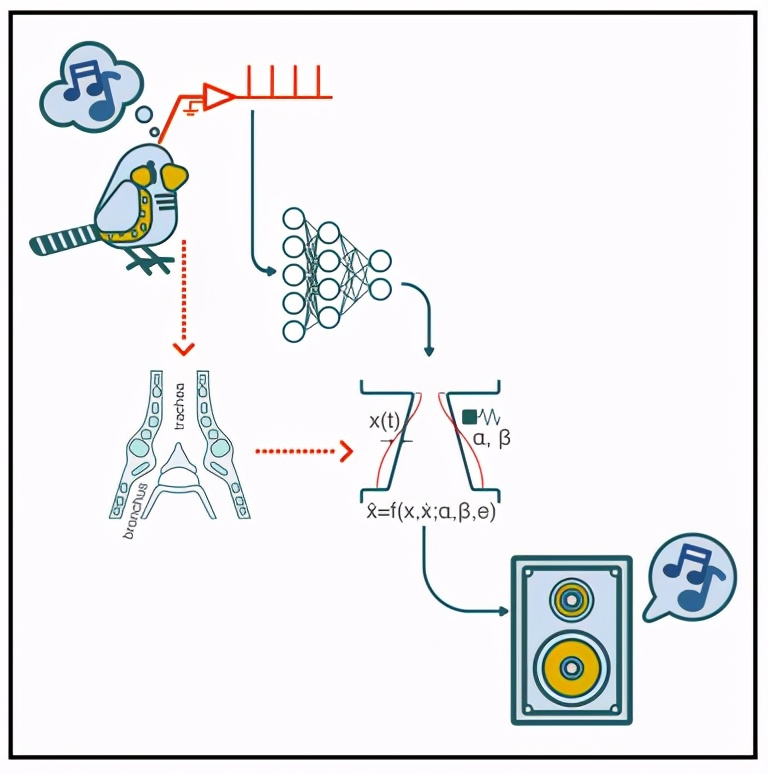
在这项研究中,研究人员展示了一个用于鸟鸣的声乐合成器,通过将植入运动前核HVC的电极阵列记录的神经群体活动映射到鸟鸣的低维压缩表征上,使用可实时实施的简单计算方法来实现。
使用鸟类发声器官(即syrinx,鸣管)的生成性生物力学模型作为这些映射的低维目标,可以合成符合鸟类自身歌声的声音。
这些结果提供了一个概念证明:高维的、复杂的自然行为可以「直接」从正在进行的神经活动中合成。这可能会启发其他物种通过利用外围系统的知识和其输出的时间结构来实现类似的假体方法。
实验描述
该研究描述了两种从斑胸草雀(Taeniopygia guttata)运动前核记录的神经活动中合成真实发声信号的方法。每种方法都利用了发声运动过程的一个不同特征。
首先,研究人员利用了对鸟鸣产生的生物力学的理解,采用了一个发声器官的生物力学模型,该模型在低维参数空间中捕捉到了大部分鸟鸣的光谱-时间复杂性(spectro-temporal complexity)。
与歌曲的完整时频表示相比,这种降维能够训练一个浅层前馈神经网络(FFN),将神经活动映射到模型参数上。
作为第二种合成方法,研究人员利用了神经活动和歌曲之间的时间协方差中的预测成分,这可以由一个直接在声乐输出的频域表示(频谱图)上训练的递归、长短期记忆神经网络(LSTM)学习。
每个合成的神经元输入来自感觉-运动核HVC,那里的神经元产生高层次的指令,驱动学习歌曲的产生。
成年斑胸草雀单独演唱由3-10个音节序列组成的固定主题歌曲。
唱歌时,多种HVC神经元亚型的活动受到调节:针对X区和RA区的投射神经元(HVCx/RA)在某个主题歌曲期间表现出短、精确、稀疏的活动爆发,而抑制性中间神经元(HVCI)在唱歌时显示出更多的tonic活动。
为了获得合奏的HVC活动和声音输出,我们在雄性成年斑胸草雀(>120天大)身上植入了16-channel或32-channel的Si探头,并在每只鸟唱歌时同时记录细胞外电压(n=4只鸟,每次70-120个发声主题)。
使用Kilosort对神经记录进行自动分类,并进行人工整理以排除噪音。
根据违反折返期(refractory period violations)的数量,非噪声集群被分为单个单位活动SUA(single-unit activity)或多单位活动(single- or multi-unit activity,MUA),并根据唱歌时活动的稀疏程度,推测为投射或中间神经元。
录音以MUA群(n = 88)和HVC中间神经元(HVCI;n = 29)为主,相对较少的推测投影神经元(HVCx/RA;n = 15)。Figure 1A显示了与歌曲对齐的神经活动直方图的例子。Figure S1显示了每只鸟的集群数量的光栅示例。
具有生物力学意义的压迫增强神经驱动的合成
通过神经活动合成复杂的运动序列需要两个高维表征之间的映射。为了降低问题的维数,我们利用了一个鸟类发声器官的「生物力学模型」,该模型将神经活动转化为发声输出。
该模型考虑了鸣管和声道的功能,鸣管包含唇褶(labial folds),当受到亚鸣管气囊的压力时,唇褶会振荡,并调节气流发出声音(Figure 1B)。
唇的动态可以按照非线性振荡器的运动方程进行建模,其中产生的声音的特征由两个时间变化的参数决定,代表生理上的运动指令。
为了通过生物力学模型从神经活动中合成歌曲,首先要拟合模型的参数,生成每种发声的合成版本。
每次训练中,我们随机选择60%的模体进行训练,将每个模体分成5毫秒的单元,然后训练一个单隐层的FFNN,在50毫秒内独立于神经活动预测每个单元相应的生物力学模型参数。神经活动用每个簇的平均放电速率表示,分成1-ms 的单元。
为了避免引入时间相关性,研究人员将每对神经活动窗口和目标模型参数呈现给网络的顺序随机化。通过训练,预测神经活动测试集对应的生物力学模型参数值,并将模型的微分方程积分得到神经驱动合成歌曲的每一个单元。
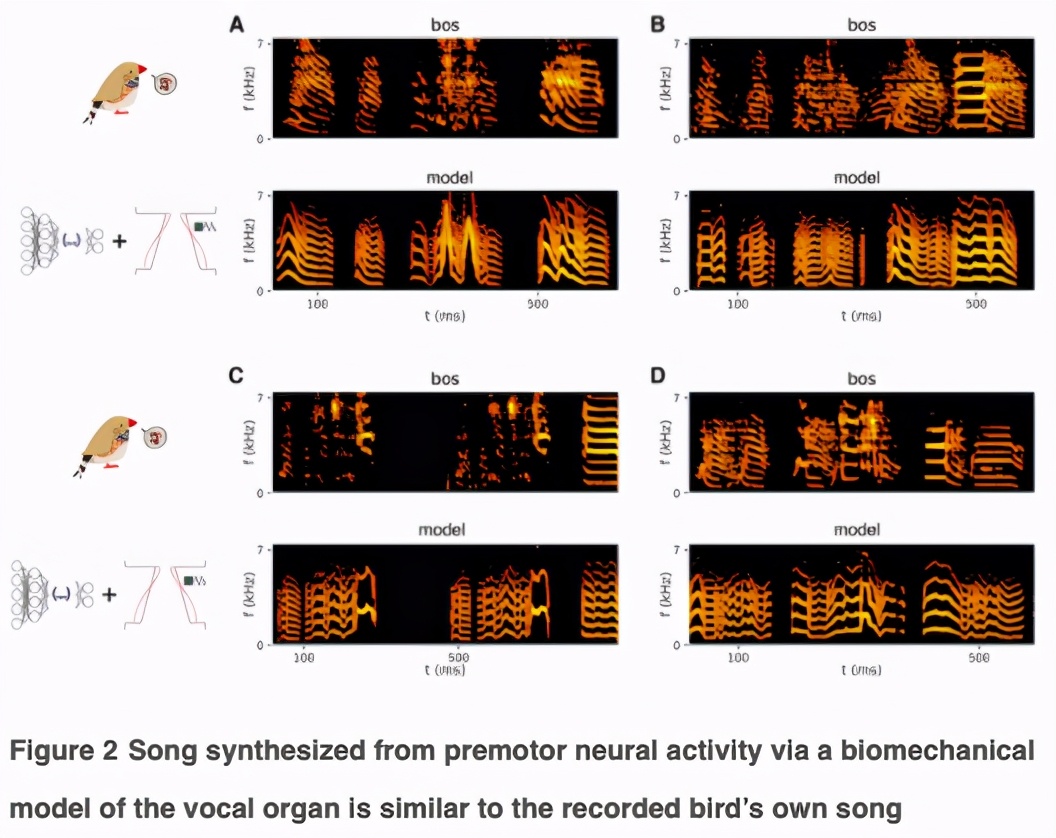
这就产生了合成的发声效果,听起来和鸟类自己的声音很相似。
相反,用FFNN直接预测歌曲的频谱-时间特征会导致低质量的合成。研究人员训练了一个与之前类似的网络,但以歌曲的频谱成分为目标,即以64个频段的功率为代表。
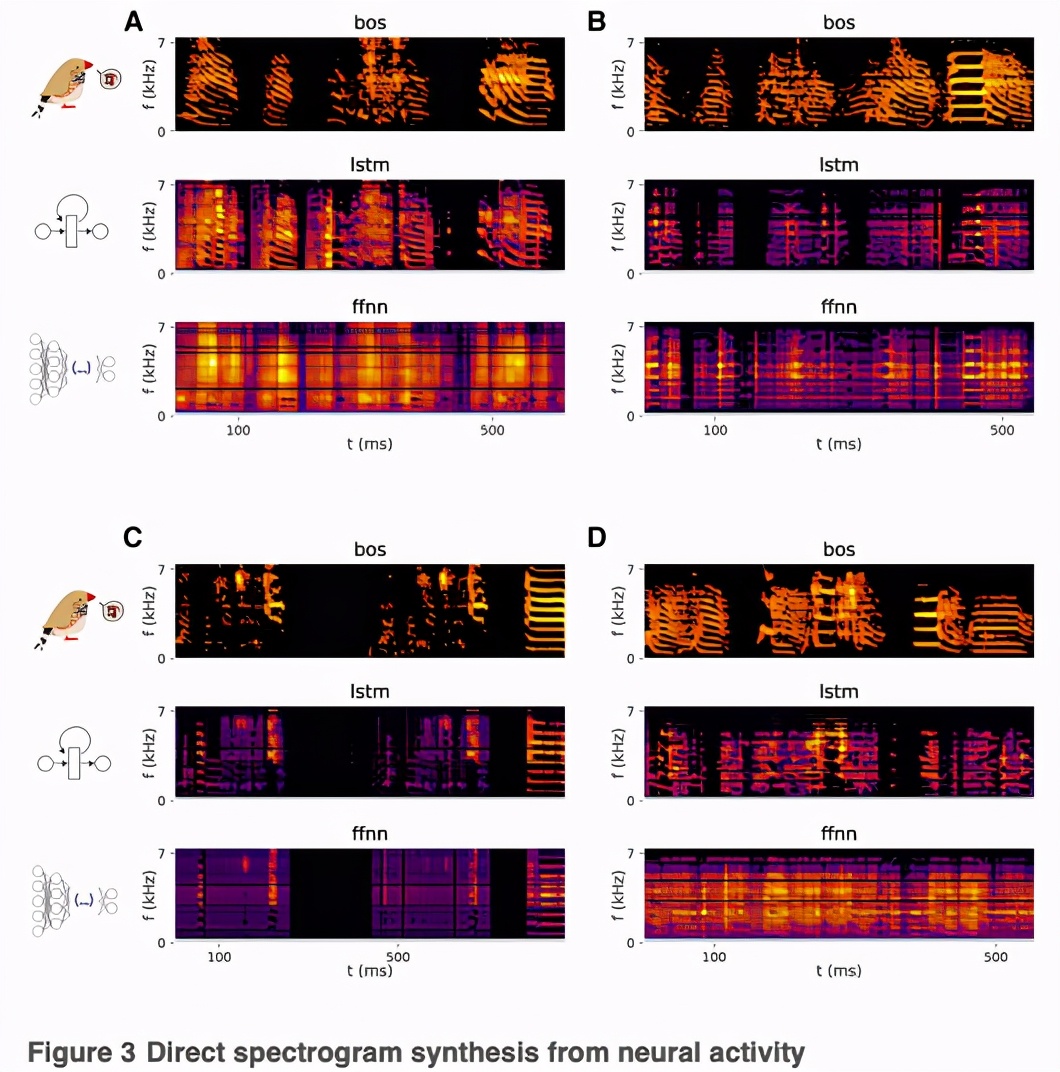
以这种方式为每只鸟合成的歌曲的例子(Figure 3; Audio S1, S2, S3, and S4)显示了FFNN如何未能产生斑胸草雀歌曲中典型的定义明确的谐波堆,以及如何忠实地再现声带的起伏。
与光谱-时间系数相比,FFNN 预测模型参数的能力不同((Figures 2, 3, and 4),表明降低行为的维度可以增强预测能力。为了证实这一点,研究人员训练了FFNN来重现行为的不同 「压缩」,即谱图的前3个主成分(PC)。
从神经活动中预测3个PC值的表现与预测生物力学模型参数的表现相似(Figure S4A)。后者的优势在于其生成能力,可以产生与BOS更相似的歌曲。
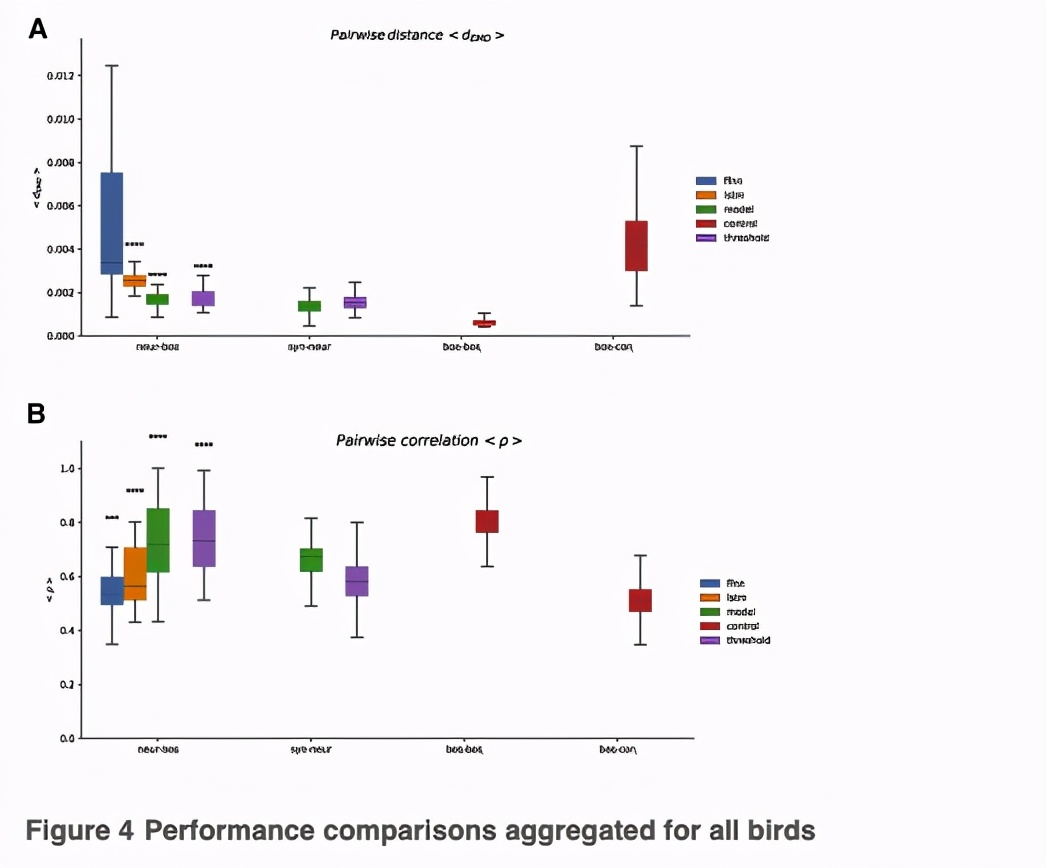
未能准确预测鸟类主题的光谱系数可能反映了这个模型无法捕捉更复杂的跨响应群的时间动态,在特定的发声之前。
为了捕捉这些动态,研究人员训练了一个LSTM,直接从前面50毫秒的神经活动中预测歌曲的频谱成分(64个频带) ,使用与前面部分描述的相同的输入和输出数据。与 FFNN 不同,LSTM 产生一个神经驱动的歌曲合成,听起来类似于预期的鸟自己的歌曲(Figure 3; Audio S1, S2, S3, 及S4)
由于雄性斑胸草雀的种类有限,这可能意味着可以通过相对简单的方法实现直接合成。然而,由于 FFNN 的损失函数接近于正则化的非线性回归,因此与所有其他方法相比,它预测出的歌曲质量较差。原因尚不完全清楚,但它可能反映了数据集的神经元亚型组成。
该研究演示了一个复杂通信信号的BMI,使用计算块,可以在一个建立的动物模型中实时实现,用于产生和学习复杂的声音行为。该方法的优势在于能够找到行为的低维参量化,这种方式可以通过记录相对较小的样本(几十个)神经元的活动来驱动。这样做与记录从表面位于细胞 HVC 可以通过侵入性较小的微电极阵列,不仅能够分辨 LFP,这已被证明适合BMI, 还有 SUA 和 MUA.
这提供了一个新颖的工具来探索「神经回路基础」的产生,获取和保持声音通信信号,并解锁进入新的模型和实验,旨在了解神经元的活动是如何转化为自然行为,以及如何外围效应塑造行为的神经基础。
该方法也为「声带修复」策略提供了一个试验场。虽然鸟鸣声与人类语言有很多明显的区别,但两种语言系统有很多相似之处,包括「连续组织」的特点和「习得」策略,神经元组织和功能的类比,遗传基础,以及发声的物理机制,实验的可达性、对神经系统和外周系统的相对先进的理解,以及作为发声和学习的发达模型的地位,这都使鸣鸟成为一个有吸引力的动物模型,以促进语音BMI(speech BMI),很像运动BMI的非人灵长类动物模型。
该论文原始数据、代码资源均已开放。

论文作者之一Shukai Chen,目前是加利福尼亚大学圣迭戈分校生物工程学院在读博士,研究方向为计算神经科学。
语音BMI铺垫DL再次复兴
该实验确实为一个突出的问题提供了解决方案。实时处理鸟鸣令人印象深刻,用人类语言复制这些结果将会令人惊奇。
但是,这项研究仍处于早期阶段,不一定适用于其他语音系统。为了让它运行得足够快,研究人员利用语音分析这一捷径,当把它扩展到鸟鸣以外时,这个捷径可能就不起作用了。
但随着进一步的发展,这可能是自2014年「深度学习复兴」以来「脑机接口」的第一次巨大的技术飞跃。