研究强化学习的你还在苦于重复造轮子吗?苦于寻找运行环境吗?
DeepMind给你带来了Acme框架!
Acme是一个基于 python 的强化学习研究框架,2020年由 Google 的 DeepMind 开源。这个框架简化了新型 RL 智能体(agent)的开发,加快了 RL 研究的步伐。
DeepMind 是强化学习和人工智能研究的先行者,根据他们自己的研究人员所说,Acme 已经成为 DeepMind 的日常使用的框架了。
目前Acme在Git已经获得了超过2.1k个星星。

Acme的学习曲线也是相当平缓的。但由于Acme有多个不同复杂程度的接口作为切入点,也就是说,这个框架不仅适用于高级研究人员,而且允许初学者实现甚至是简单的算法,类似于 TensorFlow 和 PyTorch 能够同时被初学者和专家所使用。
但这个框架唯一的缺点就是,由于框架仍然是相当新的,没有真正完整的文档可用,也没有任何优秀的教程。
针对这个问题,伦敦政治经济学院一个博士生写了一篇教学博客,帮助了解Acme框架,据作者所说,这篇教程文章并不打算成为或取代一个完整的文档,而是对 Acme 的一个简洁、实用的介绍。最重要的是,它应该让读者了解框架底层的设计选择,以及这对 RL 算法的实现意味着什么。
Acme的基本架构
以21点游戏(BlackJack)作为例子来介绍框架。
Acme 的智能体的运行环境没有设计与Gym运行环境交互,而是采用DeepMind 自己创建的 RL 环境 API。它们的区别主要在于时间步是如何表示的。
幸运的是, Acme 的开发人员已经为Gym环境提供了包装器函数。

21点有32 x 11 x 2个状态,尽管并不是所有这些状态都能在一场比赛中实际发生,并且有两个action可选,hit或是stick。
三个重要的角色分别是actor, learner, 智能体agent。
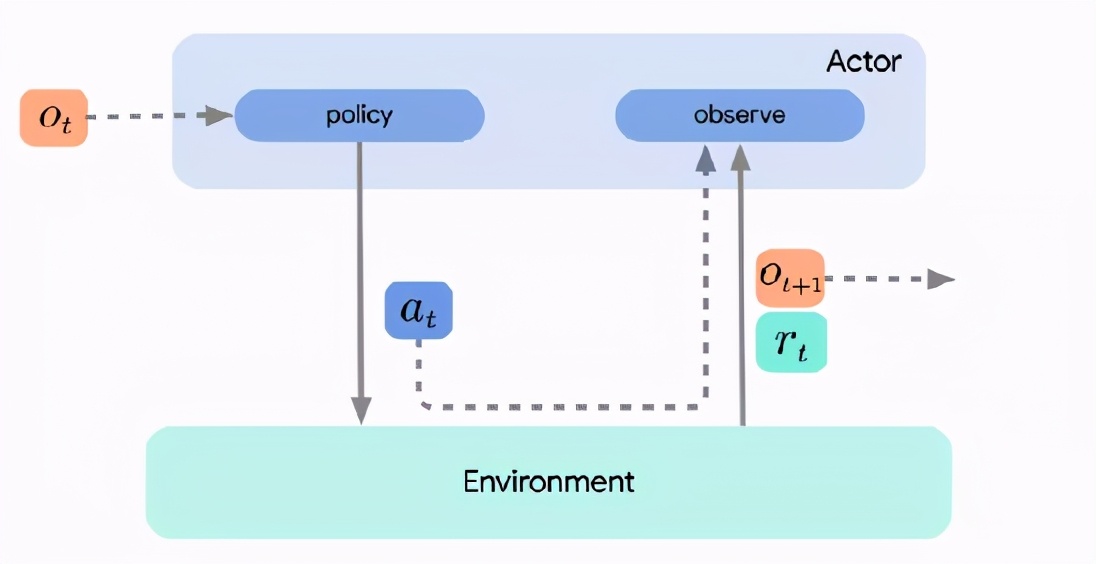
learner使用actor收集的数据来学习或改进策略,通常采用迭代的在线方式。例如,学习可能包括更新神经网络的参数。新的参数被传递给actor,然后actor根据更新的策略进行操作。
智能体只是简单地将行为和学习组件结合起来,但是通常不需要实现额外的强化学习逻辑。下面的图片包含了所有三个组件。
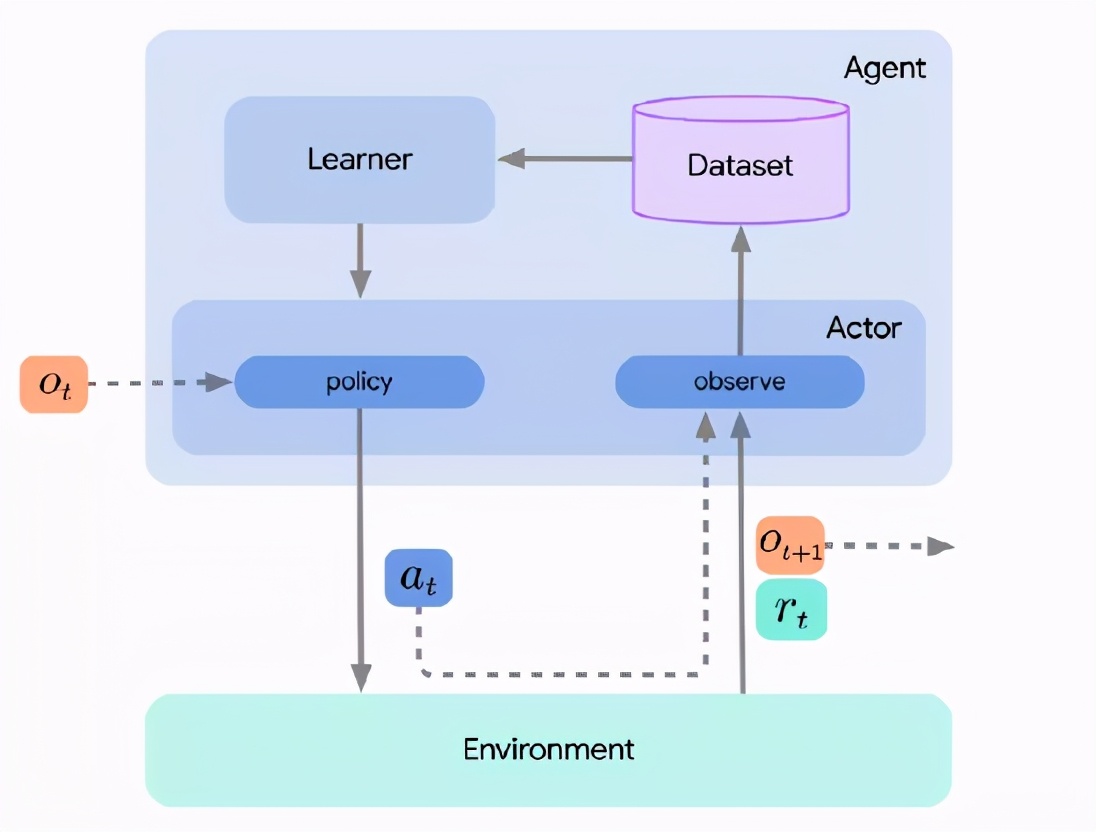
这种将actor、learner和agent分解的主要原因之一是为了促进分布式强化学习。如果我们不关心这些,或者算法足够简单,那么也可以只实现actor,并简单地将学习步骤集成到actor的更新方法中。
例如,下面的随机智能体继承自 acme的Actor类。开发人员必须实现的方法是 select_action、 observe_first、observe 和 update。正如刚才提到的,后者是没有额外的learner组成部分的学习。
注意,这个agent将以同样的方式工作,而不会子类化 acme.Actor。基类仅确定必须覆盖的方法。这还确保agent按照预期的方式与其他 Acme 组件集成,例如环境循环(environment loop)。

这个agent使用一个随机选择hit或stick的策略,但是通常框架允许您在如何实现策略方面有很大的灵活性。后面还会实现一个贪婪的政策。
在其他情况下,策略可能包含一个神经网络,可以使用 TensorFlow、 PyTorch 或 JAX 来实现它。在这个意义上,Acme 是框架是不可知的,可以将它与任何机器学习库结合起来。
在更新方法中,actor通常只从learner中提取最新的参数。
但是,如果不使用单独的学习者,那么 RL 逻辑将进入update方法。
一个 强化学习算法通常由一个循环组成,每个循环由四个步骤组成,重复这四个步骤,直到达到一个终止状态。
1、观察状态
2、根据行为策略选择下一步行动
3、观察奖励
4、更新策略

在大多数情况下,这个循环总是完全相同的。
方便的是,在 Acme 中有一个快捷方式: EnvironmentLoop,它执行的步骤几乎与上面看到的步骤一模一样。只需传递环境和代理实例,然后可以使用单行代码运行单个事件或任意多个事件。还有一些记录器可以跟踪重要的指标,比如每一个迭代采取的步骤数和收集到的奖励。

SARSA 智能体
SARSA 是一个基于策略的算法,其更新依赖于状态(state)、行动(action)、奖励(reward)、下一个状态(next state)和下一个行动(next action)而得名。
首先,在智能体的 __init__ 方法中,我们初始化 Q、状态动作值矩阵和行为策略,这是一个 epsilon 贪婪策略。还要注意,这个代理必须始终存储它的上一个 timestep、 action 和下一个 timestep,因为它们在更新步骤中是必需的。


在observe函数中,通常没有什么必须做的事。
在这种情况下,我们只是存储观察到的时间步和所采取的操作,然而,这并不总是必要的。例如,有时可能希望将时间步骤(和整个轨迹)存储在数据集或重播缓冲区中。
Acme 还为此提供了数据集和额外的组件。事实上,还有一个由 DeepMind 开发的Reverb库用来做这件事。
上面的 transform_state 方法只是一个辅助函数,用于将状态转换为正确的格式,以便正确地对 Q 矩阵进行索引。
最后,训练 SARSA 的环境为500,000步。

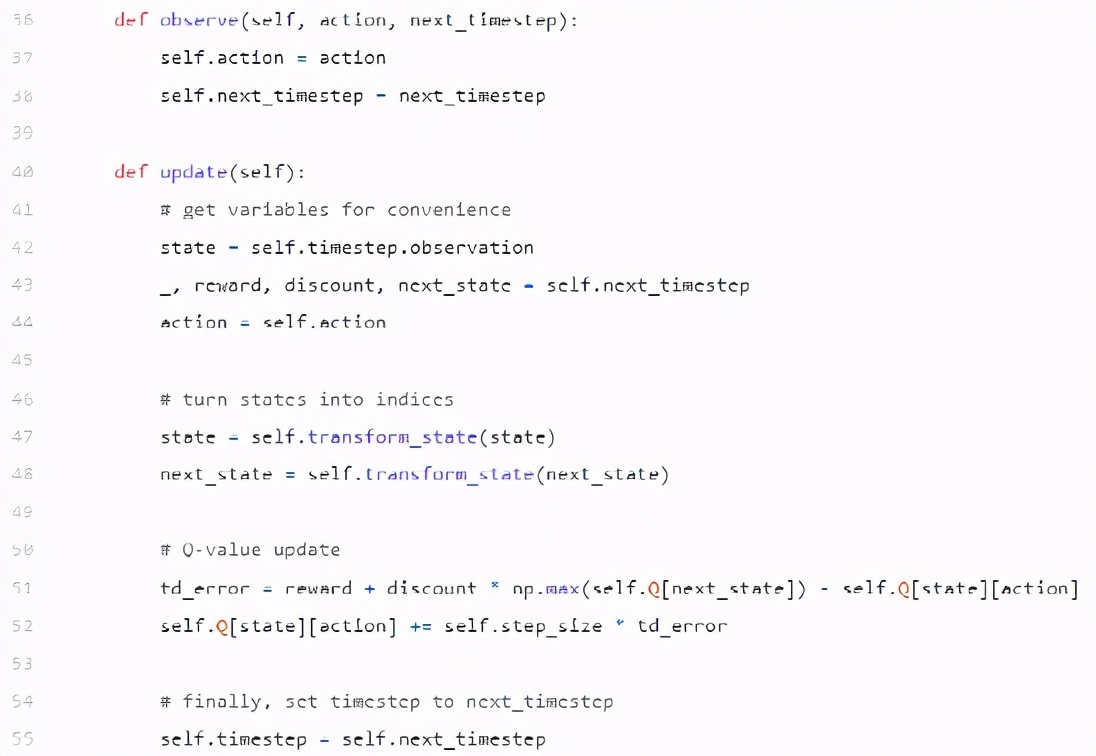
Q learning 智能体
下面的 Q learning 智能体与 SARSA 智能体非常相似。它们的不同之处仅在于如何更新 Q 矩阵。这是因为 Q 学习是一种非策略算法。

博客作者认为, Acme 是一个非常好的强化学习框架,因为你不需要从头开发你的算法。所以,与其自己琢磨如何编写可读和可重复的 RL 代码,你可以依靠 DeepMind 的聪明的研究人员和开发人员,他们已经为你做到了。
在他们的仓库中,Deep Q-Networks (DQN)、Deep Deterministic Policy Gradient(DDPG)、Monte Carlo Tree Search (MCTS)、Behavior Cloning(BC)、 IMPALA 等常用算法的实现。