现在前端开发中,我们常常会用到babel来编译例如react、vue框架的代码,以支持更多的(更古老的)浏览器,babel编译代码的过程就是编译原理的应用之一。

Babel is a JavaScript compiler!这是Babel官方对于babel的定义。身为前端工程师,因此有必要了解编译原理,幸运的是,“The Super Tiny Compiler”开源项目利用JavaScript写了一个简单的编译器。
麻雀虽小,五脏俱全,通过对该项目的学习,一起加深对编译过程的理解,以提升我们写出更高质量的程序!
一、收益
通过掌握(了解)编译原理,将有如下收益:
加深对编程语言的认识,无论何种编程语言,万变不离其宗
殊途同归,有利于理解babel等转译器、eslint、prettier、less等工具的工作原理,可开发相关插件
可以造更多轮子了🐶
二、编译过程概述
编译过程的具体实现主要分为三步骤:
- 代码解析(parse)
- 代码转换(Transformation)
- 代码生成(Code Generation)
通过上述三步骤,可以将我们的原代码,转换(编译)到目标代码,例如把javascript代码转换到python一样。
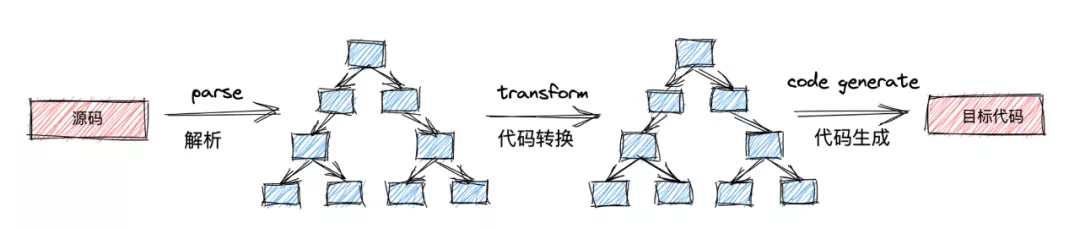
编译过程
“The Super Tiny Compiler”项目中是将LISP语言编译为C语言,如下案例:
- * LISP(source) C(target)
- *
- * 2 + 2 (add 2 2) add(2, 2)
- * 4 - 2 (subtract 4 2) subtract(4, 2)
- * 2 + (4 - 2) (add 2 (subtract 4 2)) add(2, subtract(4, 2))
二、转换过程
基于“The Super Tiny Compiler”项目,实现一个将LISP函数转换到C语言函数编写形式!
- (源代码)LISP CODE: (add 2 (subtract 4 2))
- (目标代码)C CODE: add(2, subtract(4, 2))
2.1 解析(Parse)
具象到具象的转换是很难的,但抽象到具象的转换往往是容易的。
解析的过程中包含了两个关键步骤词法分析(Lexical Analysis)和语法分析(Syntactic Analysis),解析就是一个具象到抽象的过程。
2.1.1 词法分析
词法分析的过程,主要是将原代码(字符串),通过分词的方式生成一个具有描述程序语义的token列表。
分词的原理:逐个读取源代码中的字符,与预设的关键词、字符串、数字、操作符等LISP语言定义的语法相关规则,转换成 {type: 'xx', value: 'xx'} 的具有描述意义的形式
例如LISP:(add 2 (subtract 4 2)),经过词法分析会得到如下结果:
- [
- { type: 'paren', value: '(' },
- { type: 'name', value: 'add' },
- { type: 'number', value: '2' },
- { type: 'paren', value: '(' },
- { type: 'name', value: 'subtract' },
- { type: 'number', value: '4' },
- { type: 'number', value: '2' },
- { type: 'paren', value: ')' },
- { type: 'paren', value: ')' },
- ]
这样一个列表(暂称作:tokens列表)按照顺序下来很好的描述了源代码中的字符串和编程语义。
2.1.2 语法分析
词法分析后得到的tokens列表已经可以描述LISP的语法,但是还并不抽象,因为直观看来,我们无法解读这个程序的意思,这就需要将其转换为AST(Abstract Syntax Tree,抽象语法树)。
为什么要将其转换到AST,AST能更好的描述源代码的语义、描述结构更加通用,tokens列表只是描述了“符号”的意义,可以将词法分析过程看作是分类过程,而语法分析的过程,则是将符号组合,使其具有了执行顺序以及执行规则的语法,抽象语法树,因为更抽象,因而能更高效率转换到其他形式。
操作LISP得到的AST能更好转换到C语言的AST,因为他们的AST结构都是类似的,操作AST比tokens更容易。
语法分析的过程,将tokens列表转化成为一个树结构:
- {
- type: 'Program',
- body: [
- {
- type: 'CallExpression',
- name: 'add',
- params: [
- {
- type: 'NumberLiteral',
- value: '2',
- },
- {
- type: 'CallExpression',
- name: 'subtract',
- params: [
- {
- type: 'NumberLiteral',
- value: '4',
- },
- {
- type: 'NumberLiteral',
- value: '2',
- }
- ]
- }
- ]
- }
- ]
- }
2.2 代码转换(Transform)
代码转换的过程是将传入的AST结构,通过在AST上例如增、删、改属性,将传入AST转换为C语言需要的标准AST结构。
为了实现转换,我们增加了一个 traverser(ast, visitor) 函数,这个函数接收parse过程得到的AST和visitor规则转换对象。
visitor对象实际可理解为转换规则,traverser函数在遍历AST结构时,会根据visitor中定义的规则执行转换,用于生成新的符合C语言描述标准的AST结构。
最后通过 transform(ast)(预处理,定义visitor对象) -> traverser(ast, visitor) 过程,得到一个新的AST结构:
- {
- type: 'Program',
- body: [
- {
- type: 'ExpressionStatement',
- expression: {
- type: 'CallExpression',
- callee: {
- type: 'Identifier',
- name: 'add'
- },
- arguments: [
- {
- type: 'NumberLiteral',
- value: '2'
- },
- {
- type: 'CallExpression',
- callee: {
- type: 'Identifier',
- name: 'subtract'
- },
- arguments: [
- {
- type: 'NumberLiteral',
- value: '4'
- },
- {
- type: 'NumberLiteral',
- value: '2'
- }
- ]
- }
- }
- }
- ]
- }
2.3 生成目标代码(Code Generate)
最后通过解析符合C语言标准的AST,根据C语言的语法规则,转换成为C语言格式
codeGenerator(newAst) 函数如下,接收新生成的AST结构:
- function codeGenerator(newAst) {
- switch (newAst.type) {
- case "Program":
- return newAst.body.map(codeGenerator).join("\n");
- case "ExpressionStatement":
- return codeGenerator(newAst.expression) + ";";
- case "CallExpression":
- return (
- codeGenerator(newAst.callee) +
- "(" +
- newAst.arguments.map(codeGenerator).join(", ") +
- ")"
- );
- case "Identifier":
- return newAst.name;
- case "NumberLiteral":
- return newAst.value;
- case "StringLiteral":
- return '"' + newAst.value + '"';
- default:
- throw new TypeError(newAst.type);
- }
- }
同时还做了代码的部分格式化,比如空格、换行符添加等。
此时自然会思考下,VScode编辑器中的Prettier代码格式化插件是不是也是这么做的?
四、总结
推荐大家完整阅读一下“The Super Tiny Compiler”开源项目,作者写的代码注释也非常详细。编译(转译)的过程原理基本类似,还有很多优秀的项目,比如codeMirror、babel、esprima、acorn、recast都是值得阅读的源码,喜欢的小伙伴一定要去瞅瞅。
Reference
- 《Babel Docs》- https://babeljs.io/docs/en/
- 《the super tiny complier》- https://github.com/jamiebuilds/the-super-tiny-compiler/