KDD Cup 全称为国际知识发现和数据挖掘竞赛,自1997年开始,由 ACM 协会 SIGKDD 分会每年举办一次,目前是全球数据挖掘领域最有影响力的赛事,其所设比赛题目具有相当高的实际意义和商业价值。多年来,该赛事每年都吸引着众多世界顶级的 AI 研究机构与企业的参与,并且催生了大量的经典比赛和经典算法。
今年,KDD Cup 2021 首次与斯坦福大学图神经网络权威 Jure Leskovec 教授领导 Open Graph Benchmark(OGB)团队合作,联合举办第一届 OGB Large-Scale Challenge,共有500余个来自全球各地的队伍参赛。大赛于本周刚刚结束,由微软亚洲研究院的研究员和大连理工大学等高校的实习生组成的团队在图预测赛道摘得桂冠(官方竞赛结果网页链接:https://ogb.stanford.edu/kddcup2021/results/)。
图1:微软亚洲研究院的研究员和实习生组成的团队在 OGB-LSC 图预测赛道摘得桂冠,团队成员包括:应承轩(大连理工大学)、杨明奇(大连理工大学)、罗胜杰(北京大学)、蔡天乐(普林斯顿大学)、柯国霖(微软亚洲研究院)、贺笛(微软亚洲研究院)、郑书新(微软亚洲研究院)、吴承霖(厦门大学)、王宇新(大连理工大学)、申彦明(大连理工大学)
针对图预测任务,大赛给出的赛题为“根据给定的 2D 分子化学结构图预测分子性质”。由于近年来人工智能在生物医学、材料发现等领域的探索持续受到关注,因此该赛道竞争激烈异常,“高手”云集。只有主动求变,才能在众多高手中脱颖而出。为此,微软亚洲研究院的研究员们通过借鉴 Transformer 模型的思路,提出了可应用于图结构数据的 Graphormer 模型,展现了跨领域研究的创新成果,并希望借此为各个领域的技术变革带来一些启发。团队现已将论文和代码公开发表在 arXiv 和 GitHub 上。
论文链接:
https://arxiv.org/abs/2106.05234
代码链接:
https://github.com/microsoft/Graphormer
将Transformer应用于图数据,核心在于如何正确编码“图结构”
为了得到更精确的分子性质,计算化学家们常使用基于量子力学力场的密度泛函理论 DFT (Density Functional Theory)预测,然而该方法非常耗时。若直接使用图神经网络 GNN 模型,输入分子的 2D 结构,则可以快速而准确地预测分子性质,并且在几秒钟内就能够完成。因此,目前图预测领域的主流算法主要是图神经网络(GNN)模型及其变种,比如图卷积网络(Graph Convolutional Net)、图注意力网络(Graph Attention Net)、图同构网络(Graph isomorphic Net)等。
但是,这些图神经网络的结构相对简单,表达能力有限,且经常会出现过度平滑(Over-Smoothing)的问题,即无法通过堆深网络而增加 GNN 的表达能力。为此,微软亚洲研究院的研究员们转变思路,希望可以在图预测学习任务中从图表达能力着手,来提升图预测性能。
研究员们看到,Transformer 模型具有很强的模型表达能力,没有其他图神经网络所存在的上述弱点。微软亚洲研究院机器学习组对 Transformer 模型结构有着深刻的理解,近几年在顶级国际学术会议如 ICML、NeurIPS、ICLR 上发表了许多关于如何改进 Transformer 的论文,基于这些对模型本质的认识,研究员们相信 Transformer 的不少优势在图数据上也可以发挥巨大的作用。
经典的 Transformer 模型是处理序列类型数据的,如自然语言、语音等等,那么如何让这个模型处理图类型数据呢?研究员们认为最重要的是让 Transformer 学会编码图的结构信息。Transformer 的核心在于其自注意力机制,通过在计算中输入不同位置语义信息的相关性,可以捕捉到信息之间的关系,并且可基于这些关系得到对整个输入完整的表达(representation)。然而,自注意力机制无法捕捉到结构信息。对于自然语言序列而言,输入序列的结构信息可以简单认为是词与词的相对顺序,以及每个词在句子中的位置。对于图数据而言,这种结构信息更加复杂、多元,例如在图上的每个节点都有不同数量的邻居节点,两个节点之间可以有多种路径,每个边上都可能包含重要的信息。如何在图数据中成功应用 Transformer 的核心优势,最关键的难题是要确保模型可以正确利用这些图结构信息。
图结构数据上的Transformer变种Graphormer
为了把 Transformer 模型强大的表达能力引入图结构数据中,研究员们提出了 Graphormer 模型。Graphormer 模型引入了三种结构编码,以帮助 Transformer 模型捕捉图的结构信息。这些结构编码让 Graphormer 模型的自注意力层可以成功捕捉到更“重要”的节点或节点对,从而令后续的注意力权重分配更准确。
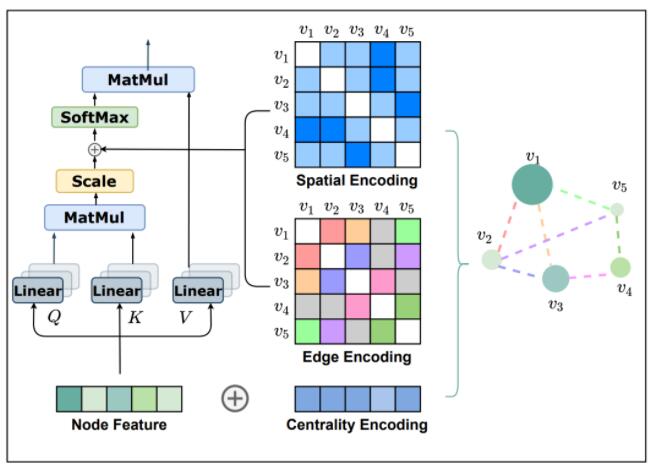
图2:Graphormer 模型的三种结构编码
第一种编码,Centrality Encoding(中心性编码)。Centrality(中心性)是描述图中节点重要性的一个关键衡量指标。图的中心性有多种衡量方法,例如一个节点的“度”(degree)越大,代表这个节点与其他节点相连接的边越多,那么往往这样的节点就会更重要,如在疾病传播路线中的超级传播者,或社交网络上的大V、明星等。Centrality 还可以使用其他方法进行度量,如 Closeness、Betweenness、Page Rank 等。在 Graphormer 中,研究员们采用了最简单的度信息作为中心性编码,为模型引入节点重要性的信息。
第二种编码,Spatial Encoding(空间编码)。实际上图结构信息不仅包含了每个节点上的重要性,也包含了节点之间的重要性。例如:邻居节点或距离相近的节点之间往往相关性比距离较远的节点相关性高。因此,研究员们为 Graphormer 设计了空间编码:给定一个合理的距离度量 ϕ(v_i, v_j), 根据两个节点(v_i, v_j)之间的距离,为其分配相应的编码向量。距离度量 ϕ(⋅) 的选择多种多样,对于一般性的图数据可以选择无权或带权的最短路径,而对于特别的图数据则可以有针对性的选择距离度量,例如物流节点之间的最大流量,化学分子 3D 结构中原子之间的欧氏距离等等。为了不失一般性,Graphormer 在实验中采取了无权的最短路径作为空间编码的距离度量。
第三种编码,Edge Encoding(边信息编码)。对于很多的图任务,连边上的信息有非常重要的作用,例如连边上的距离、流量等等。然而为处理序列数据而设计的 Transformer 模型并不具备捕捉连边上的信息的能力,因为序列数据中并不存在“连边”的概念。因此,研究员们设计了边信息编码,将连边上的信息作为权重偏置(Bias)引入注意力机制中。具体来说,在计算两个节点之间的相关性时,研究员们对这两个节点最短路径上的连边特征进行加权求和作为注意力偏置,其中权重是可学习的。
与此同时,研究员们还从理论角度证明了当前流行的 GNN 网络如 GCN、GIN、GraphSage 等,都是 Graphormer 的特例:在为 Graphormer 设定特殊的参数时,这些 GNN 中的操作可以被 Graphormer 所覆盖。例如,当两个节点为邻居节点时,将空间编码设为0,或将空间编码设为-∞,并且令 W_Q=W_K=0, W_V=I,则自注意力层即成为 GCN、GraphSage 等网络中的 MEAN Aggregation 操作。因此,Graphormer 能够取得比 GNN 模型更好的效果也是理所应当的。
此外,研究员们还在多个主流图预测任务排行榜上验证了 Graphormer 的效果。例如,OGB 数据集中的 ogbg-molhiv 任务(预测是否被 HIV 病毒感染),ogbg-molpcba 任务(预测分子的64种性质)以及 Benchmarking-GNN 数据集中的 ZINC 任务(对真实世界中存在的分子的受限溶解度 Constrained Solubility 进行预测)。Graphormer 均取得了优异的成绩,具体测试结果如下图:
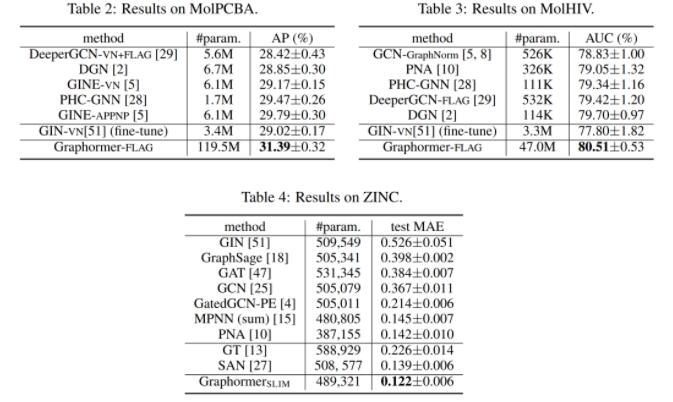
图3:Graphormer 模型在 ogbg-molhiv、 ogbg-molpcba 和 ZINC 数据集上的测试结果
不止于分子性质预测
近年来,微软亚洲研究院一直在探索如何利用 AI 的技术手段与不同基础科学领域进行跨界研究合作,如生物学、环境科学、物理学等等,并产生了大量的创新研究成果。
Graphormer 在设计之初并非只针对分子性质预测场景,其采用的三种编码具有通用性,可以应用于更广泛的图数据场景中,例如,社交网络的推荐和广告、知识图谱、自动驾驶的雷达点云数据、对交通物流运输等的时空预测和优化、程序理解和生成等等,还包括分子性质预测所涉及的行业,比如药物发掘、材料发现、分子动力学模拟、蛋白质结构预测等等。研究员们表示,下一步将在更多的任务中探索 Graphormer 模型的潜能。相信未来,各个科学领域与 AI 的密切结合将为领域的发展带来更为非常广阔的空间。
欢迎大家使用 Graphormer 模型,为模型的提升提出宝贵建议,与我们共同推进相关领域的技术进展。
论文链接:
https://arxiv.org/abs/2106.05234
代码链接:
https://github.com/microsoft/Graphormer