












自然语言处理(NLP)被誉为 AI 皇冠上的明珠,传统 NLP 模型制作复杂,耗时耗力,且用途单一,难以复用,犹如手工作坊。而近几年兴起的预训练语言模型,正在改变局面,有望让语言 AI 走向可规模化复制的工业时代。因此,「预训练 + 精调」已成为 NLP 任务的新范式。
阿里巴巴达摩院作为最早投入预训练语言模型研究的团队之一,历经三年研发出深度语言模型体系 AliceMind, 在通用语言模型 StructBERT 的基础上,拓展到多语言、生成式、多模态、结构化、知识驱动等方向,能力全面。其中的模型先后登顶 GLUE、CLUE、XTREME、VQA Challenge、DocVQA、MS MARCO 在内的自然语言处理领域六大权威榜单,领先业界,相关工作论文被 AI/NLP 顶会接收,并在 6 月入选 2021 世界人工智能大会最高奖 SAIL 奖 TOP30 榜单。
上周 AliceMind 再次登顶多模态权威榜单 VQA Challenge 2021 视觉问答挑战赛,战胜了微软、Facebook 等几十家国际顶尖团队,超越第二名 1 个点,将纪录从去年第一名的 76.36% 显著提升到 79.78%,接近人类水平(80.78%)。
就在近日,阿里巴巴达摩院宣布正式开源 AliceMind。达摩院相关负责人表示,希望通过开源来降低业界研究和创新应用的门槛,助推语言 AI 进入大工业时代。
据介绍,达摩院深度语言模型体系 AliceMind,包括通用语言模型 StructBERT、多语言 VECO、生成式 PALM、多模态 StructVBERT、结构化 StructuralLM、知识驱动 LatticeBERT、机器阅读理解 UED、超大模型 PLUG 等,此次大部分已开源。此外,AliceMind 之后将围绕「预训练 + 精调」语言模型持续进行生态性的技术开源。
AliceMind 开源地址:
https://github.com/alibaba/AliceMind
AliceMind 体验入口:
https://nlp.aliyun.com/portal#/alice
AliceMind 的创新之处
1、通用语言模型 StructBERT
Google 于 2018 年底推出的 BERT 模型是业界广泛使用的自然语言预训练模型,达摩院团队在 BERT 的基础上提出优化模型 StructBERT,让机器更好地掌握人类语法,理解自然语言,2020 年多次在自然语言处理领域顶级赛事 GLUE Benchmark 上夺冠。
StructBERT 通过在句子级别和词级别引入两个新的目标函数,好比给机器内置一个「语法识别器」,使机器在面对语序错乱或不符合语法习惯的词句时,仍能准确理解并给出正确的表达和回应,大大提高机器对词语、句子以及语言整体的理解力。相关论文被 ICLR2020 接收。
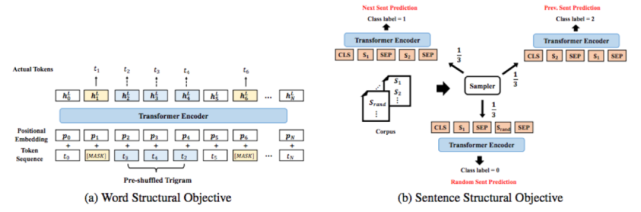
2、多语言语言模型 VECO
跨语言预训练初衷是为多种语言建立起一个统一联合的语义表示,AliceMind 体系内的跨语言预训练模型 VECO 一经提出,便在国际权威多语言榜单 XTREME 排名第一,远超 Facebook、Microsoft 等业界代表性模型。VECO 目前支持 100 种语言的理解和生成任务。
VECO 效果亮眼,主要是因为两项创新:一是其可以更加「显式」地进行跨语言信息的建模(图 1);二是 VECO 在预训练的过程充分学习用于语言理解(NLU)和生成(NLG)任务,并让二者互相学习提高彼此(图 2)。因此,VECO 模型成为了多语言领域内的第一个同时在多语言理解(NLU)和语言生成(NLG)任务上均取得业内最佳效果的模型,相关论文被顶会 ACL 2021 接收。
图 1
图 2
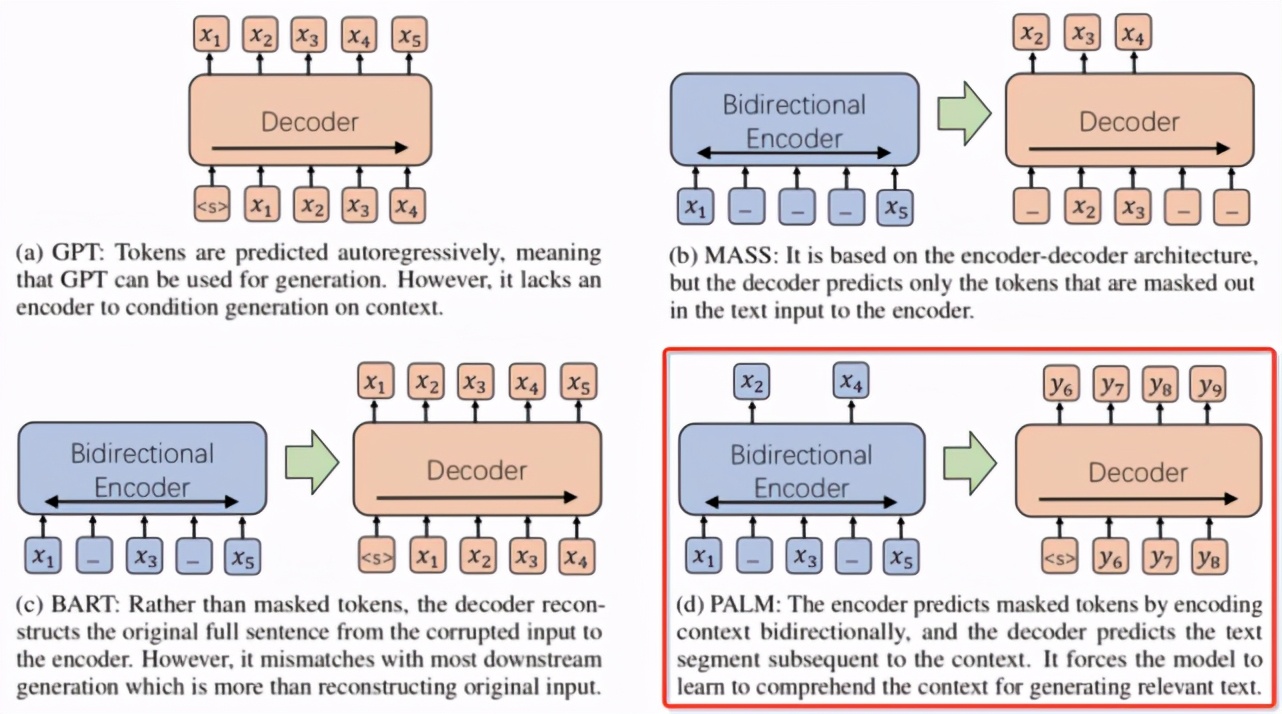
3、生成式语言模型 PALM
PALM 采用了与之前的生成模型不同的预训练方式,将预测后续文本作为其预训练目标,而非重构输入文本。PALM 在一个模型中使用自编码方式来编码输入文本,同时使用自回归方式来生成后续文本。这种预测后续文本的预训练促使该模型提高对输入文本的理解能力,从而在下游的各个语言生成(NLG)任务上取得更好的效果。
PALM 在 MARCO NLG 自然语言生成公开评测上取得了排行榜第一,同时在摘要生成标准数据集 CNN/DailyMail 和 Gigaword 上也超过了现有的各个预训练生成语言模型。PALM 可被用于问答生成、文本复述、回复生成、文本摘要、Data-to-Text 等生成应用上。相关文章已被顶会 ACL2020 录用。
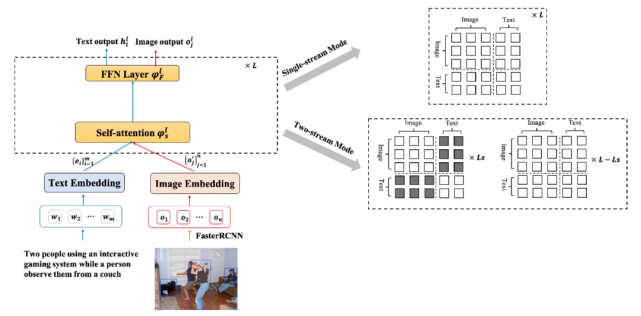
4、多模态语言模型 StructVBERT
StructVBERT 是在通用的 StructBERT 模型基础上,同时引入文本和图像模态,在统一的多模态语义空间进行联合建模,在单流架构的基础上同时引入图像 - 文本描述数据和图像问答数据进行多任务预训练,并在多尺度的图像特征上进行分阶段预训练。此外,模型利用 attention mask 矩阵控制实现双流架构,从而提升跨模态双流建模能力,结合单流、双流结构的优点进一步提升模型对文本和图像两个模态的理解能力。相关文章已被顶会 ACL2021 录用。
5、结构化语言模型 StructuralLM
StructuralLM 在语言模型 StructBERT 的基础上扩展到结构化语言模型,充分利用图片文档数据的 2D 位置信息,并引入 box 位置预测的预训练任务,帮助模型感知图片不同位置之间词语的关系,这对于理解真实场景中的图片文档十分重要。Structural LM 模型在 DocVQA 榜单上排名第一,同时在表单理解 FUNSD 数据集和文档图片分类 RVL-CDIP 数据集上也超过现有的所有预训练模型。相关文章已被顶会 ACL2021 录用。
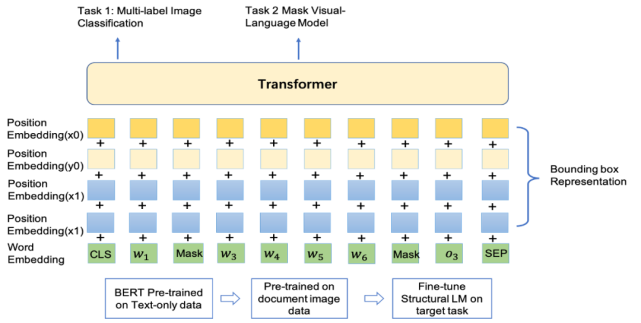
6、机器阅读理解模型 UED
自最开始声名大噪的 SQuAD 榜单起,阿里围绕着机器阅读理解发展路线:单段落抽取 -> 多文档抽取 / 检索 -> 多文档生成 -> 开放式阅读理解,拿下了一系列的榜单冠军:
- 2018 年在单段落机器阅读理解领域顶级赛事 SQuAD 上首次超出人类回答精准率;
- 2018 年在多文档机器阅读理解权威比赛 TriviaQA 和 DuReader 上双双刷新纪录,取得第一名;
- 2019 年在信息检索国际顶级评测 TREC 2019 Deep Learning Track 上的段落检索和文档检索任务上均取得第一名;
- 2019 年在机器阅读理解顶级赛事 MS MARCO 的段落排序、多文档答案抽取以及多文档答案生成 3 个任务均取得第一名,并在多文档答案抽取任务上首次超越人类水平。
相关论文已被 AAAI2021 接收。
7、超大规模中文理解和生成统一模型 PLUG
PLUG 是目前中文社区已开放 API 的最大规模的纯文本预训练语言模型,集语言理解与生成能力于一身。PLUG 可为目标任务做针对性优化,通过利用下游训练数据精调模型使其在该特定任务上生成质量达到最优,弥补之前其它大规模生成模型 few-shot 推理的生成效果不足,适于应用在实际生成任务。同时,PLUG 采用 encoder-decoder 的双向建模方式,因此,在传统的 zero-shot 生成的表现上,无论是生成的多样性,领域的广泛程度,还是生成长文本的表现,较此前的模型均有明显的优势。
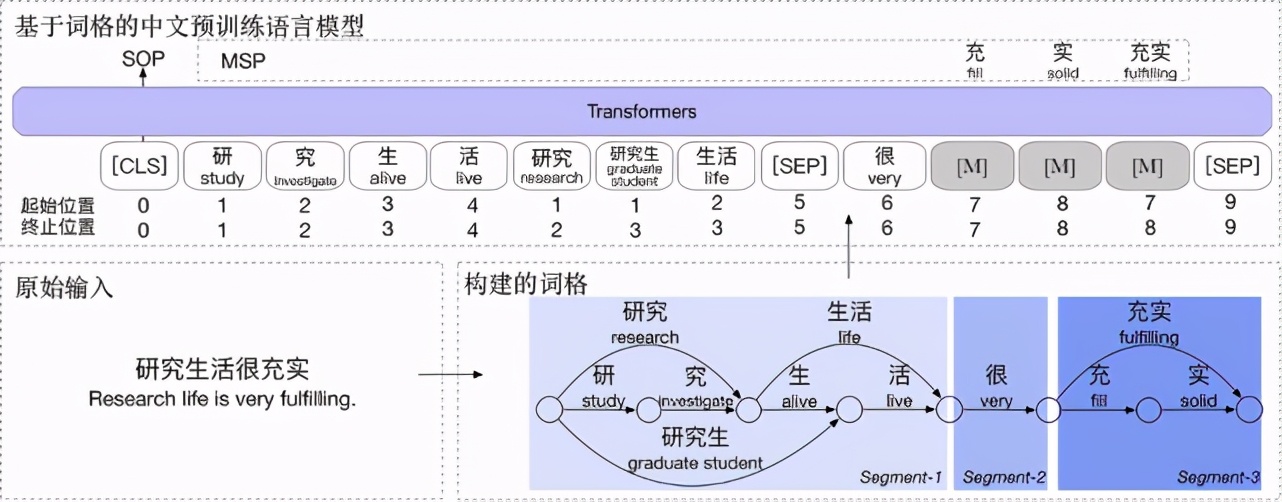
8. 知识驱动的语言模型 LatticeBERT
LatticeBERT 在预训练模型中训练中有效地融合了词典等知识,从而能够同时建模字和词的结构,来线性化地表示这种混合粒度的输入。第一步是将涵盖多粒度字词信息的中文文本用词格(Lattice)表示起来,再把这个词格线性化作为 BERT 的输入。LatticeBERT 在 2020 年 9 月达到中文语义理解评估基准 CLUE 榜单的 base 模型中的第一名。
霸榜背后,是 AliceMind 持续创新和进化。达摩院团队在 BERT 基础上提出优化模型 StructBERT,2020 年多次在 NLP 顶级赛事 GLUE Benchmark 上夺冠。该模型通过在句子和词级别引入两个新的目标函数,好比给 AI 装上「语法识别器」,在面对语法错乱时,AI 依然能准确理解并给出正确回应,大大提高机器对语言的整体理解力,相关文章被 NAACL2021 录用。
而此次在 VQA Challenge 2021 登顶的多模态模型 StrucVBERT,融合了通用模型 StructBERT 和结构化模型 StructuralLM,同时引入文本和图像模态,利用更高效的视觉特征和创新的注意力机制在统一的多模态语义空间进行联合建模。
AliceMind 的应用情况
AliceMind 具有阅读、写作、翻译、问答、搜索、摘要生成、对话等多种能力,目前已成为阿里的语言技术底座,日均调用量超过 50 亿次,活跃场景超过 200 个,已在跨境电商、客服、广告等数十个核心业务应用落地。AliceMind 已上线到内部平台,开箱即用,目前支持训练、精调、蒸馏、测试、部署五大功能,只需简单操作即可完成语言模型从训练到部署的完整链路。
在阿里之外,AliceMind 广泛运用于医疗、能源、金融等多个行业。其中,浙江电网公司以 AliceMind 为底座为员工构建智能化运维平台,应用于变压器检修、供电抢修等业务,已经开始在国家电网公司统一推广。
阿里达摩院深度语言模型团队负责人黄松芳表示:「预训练语言模型已成为 NLP 领域的基石和原材料,AliceMind 开源将降低 NLP 领域研究和应用创新的门槛,助推行业从手工业时代走向大工业时代。」






















