












数据的存放
- 在 ext2 和 ext3 中,其中前 12 项直接保存了块的位置,也就是说,我们可以通过 i_block[0-11],直接得到保存文件内容的块。
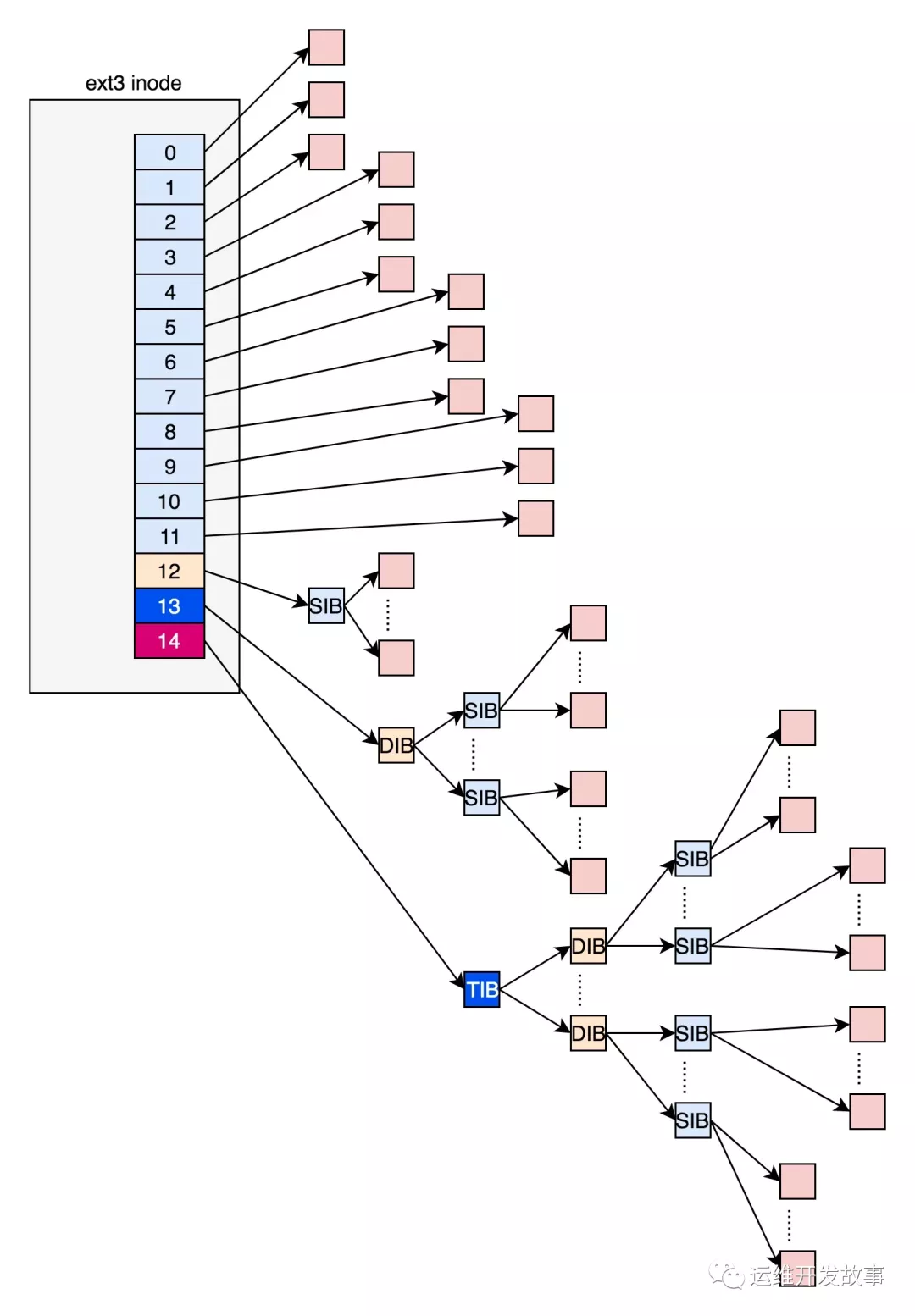
但是,如果一个文件比较大,inode的块号不足以标识所有的数据块,就会使用间接块。文件系统会在硬盘上分配一个数据块,不存储文件数据,专门用来存储块号。该块被称为间接块。inode的长度是固定的。间接块占用的空间对于大文件来说是必要的。但是对于小文件不会带来额外的开销。当我们用到 i_block[12]的时候,就不能直接放数据块的位置了,要不然 i_block 很快就会用完了。这该怎么办呢?我们需要想个办法。我们可以让 i_block[12]指向间接块。也就是说,我们在 i_block[12]里面放间接块的位置,通过 i_block[12]找到间接块后,间接块里面放数据块的位置,通过间接块可以找到数据块。如果文件再大一些,i_block[13]会指向一个块,我们可以用二次间接块。二次间接块里面存放了间接块的位置,间接块里面存放了数据块的位置,数据块里面存放的是真正的数据。如果文件再大一些,i_block[14]会指向三次间接块。
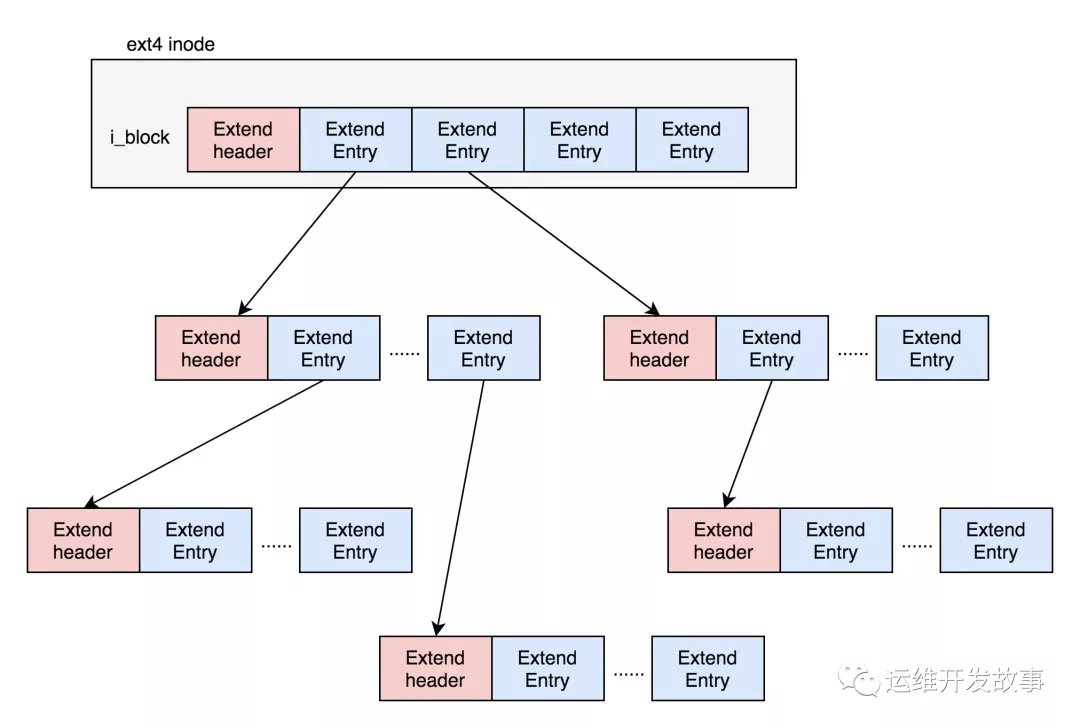
- ext4文件系统的Extents一棵树:
解释一下 Extents。比方说,一个文件大小为 128M,如果使用 4k 大小的块进行存储,需要 32k 个块。Extents 可以用于存放连续的块,也就是说,我们可以把 128M 放在一个 Extents 里面。这样的话,对大文件的读写性能提高了,文件碎片也减少了。如下图所示:
索引节点区,用来存储索引节点。Inode存储了文件系统对象的一些元信息,如所有者、访问权限(读、写、执行)、类型(是文件还是目录)、内容修改时间、inode修改时间、上次访问时间、对应的文件系统存储块的地址,等等。知道了1个文件的inode号码,就可以在inode元数据中查出文件内容数据的存储地址。对于EXT4的默认情况,一个inode的大小是256字节,inode是EXT4最重要的元数据信息。注意Inode没有文件名称,将在下文中讲述。
- struct ext4_inode {
- __le16 i_mode; /* File mode */
- __le16 i_uid; /* Low 16 bits of Owner Uid */
- __le32 i_size_lo; /* Size in bytes */
- __le32 i_atime; /* Access time */
- __le32 i_ctime; /* Inode Change time */
- __le32 i_mtime; /* Modification time */
- __le32 i_dtime; /* Deletion Time */
- __le16 i_gid; /* Low 16 bits of Group Id */
- __le16 i_links_count; /* Links count */
- __le32 i_blocks_lo; /* Blocks count */
- __le32 i_flags; /* File flags */
- union {
- struct {
- __le32 l_i_version;
- } linux1;
- struct {
- __u32 h_i_translator;
- } hurd1;
- struct {
- __u32 m_i_reserved1;
- } masix1;
- } osd1; /* OS dependent 1 */
- __le32 i_block[EXT4_N_BLOCKS];/* Pointers to blocks */
- __le32 i_generation; /* File version (for NFS) */
- __le32 i_file_acl_lo; /* File ACL */
- __le32 i_size_high;
- __le32 i_obso_faddr; /* Obsoleted fragment address */
- union {
- struct {
- __le16 l_i_blocks_high; /* were l_i_reserved1 */
- __le16 l_i_file_acl_high;
- __le16 l_i_uid_high; /* these 2 fields */
- __le16 l_i_gid_high; /* were reserved2[0] */
- __le16 l_i_checksum_lo;/* crc32c(uuid+inum+inode) LE */
- __le16 l_i_reserved;
- } linux2;
- struct {
- __le16 h_i_reserved1; /* Obsoleted fragment number/size which are removed in ext4 */
- __u16 h_i_mode_high;
- __u16 h_i_uid_high;
- __u16 h_i_gid_high;
- __u32 h_i_author;
- } hurd2;
- struct {
- __le16 h_i_reserved1; /* Obsoleted fragment number/size which are removed in ext4 */
- __le16 m_i_file_acl_high;
- __u32 m_i_reserved2[2];
- } masix2;
- } osd2; /* OS dependent 2 */
- __le16 i_extra_isize;
- __le16 i_checksum_hi; /* crc32c(uuid+inum+inode) BE */
- __le32 i_ctime_extra; /* extra Change time (nsec << 2 | epoch) */
- __le32 i_mtime_extra; /* extra Modification time(nsec << 2 | epoch) */
- __le32 i_atime_extra; /* extra Access time (nsec << 2 | epoch) */
- __le32 i_crtime; /* File Creation time */
- __le32 i_crtime_extra; /* extra FileCreationtime (nsec << 2 | epoch) */
- __le32 i_version_hi; /* high 32 bits for 64-bit version */
- __le32 i_projid; /* Project ID */
- };
普通文件的存储格式
数据块区,则用来存储文件数据。i_block,我们来看看EXT4_N_BLOCKS的具体定义:
- #define EXT4_NDIR_BLOCKS 12
- #define EXT4_IND_BLOCK EXT4_NDIR_BLOCKS
- #define EXT4_DIND_BLOCK (EXT4_IND_BLOCK + 1)
- #define EXT4_TIND_BLOCK (EXT4_DIND_BLOCK + 1)
- #define EXT4_N_BLOCKS (EXT4_TIND_BLOCK + 1)
inode 里面的 i_block 中,可以放得下一个 ext4_extent_header 和 4 项 ext4_extent。
- struct ext4_extent_header {
- __le16 eh_magic; /* probably will support different formats */
- __le16 eh_entries; /* number of valid entries */
- __le16 eh_max; /* capacity of store in entries */
- __le16 eh_depth; /* has tree real underlying blocks? */
- __le32 eh_generation; /* generation of the tree */
- };
- /*
- * This is the extent on-disk structure.
- * It's used at the bottom of the tree.
- */
- struct ext4_extent {
- __le32 ee_block; /* first logical block extent covers */
- __le16 ee_len; /* number of blocks covered by extent */
- __le16 ee_start_hi; /* high 16 bits of physical block */
- __le32 ee_start_lo; /* low 32 bits of physical block */
- };
- /*
- * This is index on-disk structure.
- * It's used at all the levels except the bottom.
- */
- struct ext4_extent_idx {
- __le32 ei_block; /* index covers logical blocks from 'block' */
- __le32 ei_leaf_lo; /* pointer to the physical block of the next *
- * level. leaf or next index could be there */
- __le16 ei_leaf_hi; /* high 16 bits of physical block */
- __u16 ei_unused;
- };
如果文件不大,inode 里面的 i_block 中,可以放得下一个 ext4_extent_header 和 4 项 ext4_extent。所以这个时候,eh_depth 为 0,也即 inode 里面的就是叶子节点,树高度为 0。如果文件比较大,4 个 extent 放不下,就要分裂成为一棵树,eh_depth>0 的节点就是索引节点,其中根节点深度最大,在 inode 中。最底层 eh_depth=0 的是叶子节点。
目录与文件名的存储格式
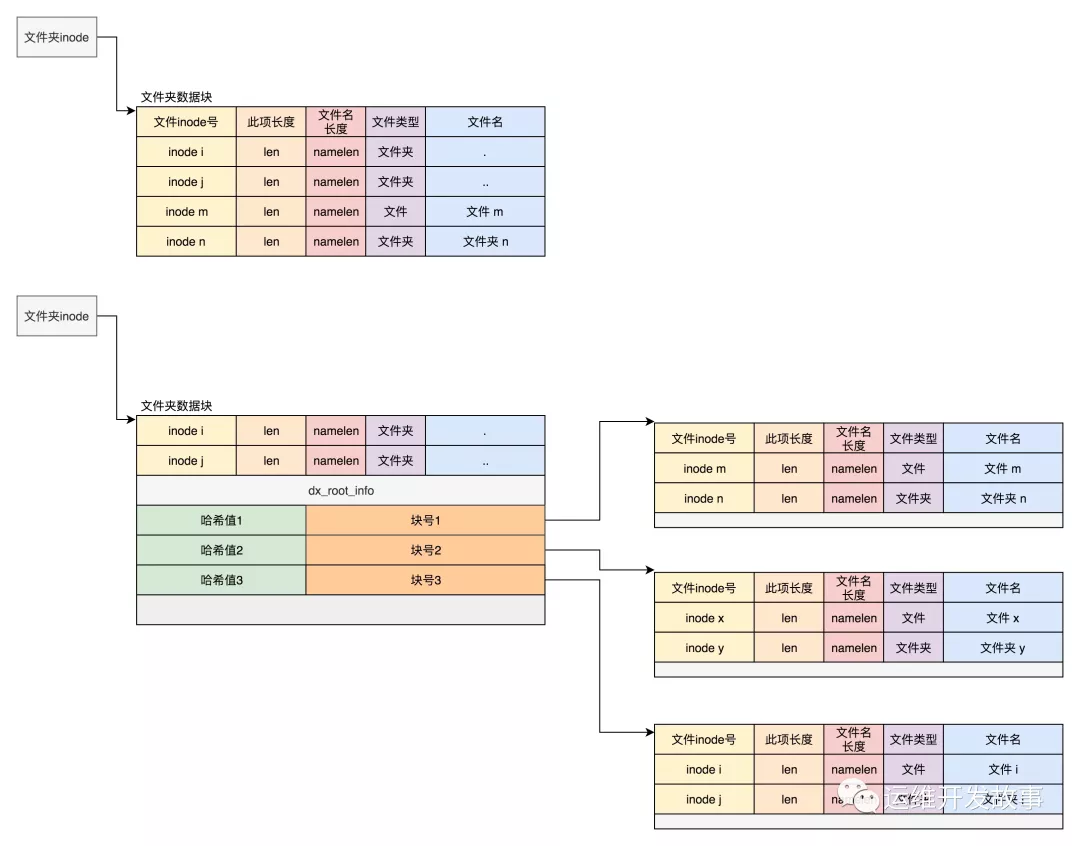
目录下文件比较少的情况下:目录本身也是个文件,也有 inode。inode 里面也是指向一些块。和普通文件不同的是,普通文件的块里面保存的是文件数据,而目录文件的块里面保存的是目录里面一项一项的文件信息。这些信息我们称为 ext4_dir_entry。从代码来看,有两个版本,在成员来讲几乎没有差别,只不过第二个版本 ext4_dir_entry_2 是将一个 16 位的 name_len,变成了一个 8 位的 name_len 和 8 位的 file_type。即该目录项的数据所在inode编号、文件名长度与类型、文件名字三部分组成。
- struct ext4_dir_entry {
- __le32 inode; /* Inode number */
- __le16 rec_len; /* Directory entry length */
- __le16 name_len; /* Name length */
- char name[EXT4_NAME_LEN]; /* File name */
- };
- struct ext4_dir_entry_2 {
- __le32 inode; /* Inode number */
- __le16 rec_len; /* Directory entry length */
- __u8 name_len; /* Name length */
- __u8 file_type; /* File type */
- char name[EXT4_NAME_LEN]; /* File name */
- };
file_type指定了目录项的类型。改变量的可能值,由以下枚举类型定义:
- enum{
- EXT4_FT_UNKNOWN,
- EXT4_FT_REG_FILE,
- EXT4_FT_DIR,
- EXT4_FT_CHRDEV,
- EXT4_FT_BLKDEV,
- EXT4_FT_FIFO,
- EXT4_FT_SOCK,
- EXT4_FT_SYMLINK,
- EXT4_FT_MAX
- }
ls列出的目录内容如下:
- [root@localhost ~]# ls -la
- 总用量 37536
- dr-xr-x---. 7 root root 4096 5月 26 16:54 .
- dr-xr-xr-x. 19 root root 288 6月 10 14:51 ..
- -rw-------. 1 root root 1260 1月 11 2014 anaconda-ks.cfg
每一项都会保存这个目录的下一级的文件的文件名和对应的 inode,通过这个 inode,就能找到真正的文件。第一项是“.”,表示当前目录,第二项是“..”,表示上一级目录,接下来就是一项一项的文件名和 inode。**目录下文件比较多的情况下:如果一个目录下有几万几十万个条目,这个方法就比较慢了。原因在于线性扫描,而且,1个block(4096字节),基本只能放下几十~200个条目,一旦需要几十几百个block,那么为了获取子文件的inode,这个DISK IO的消耗是不能忍受的。因此开发了dir_index的功能。dir_index使用dx_entry来对目录文件的block进行管理,一个dx_entry对象对应一个block。dx_entry.hash记录的是其对应block内所有目录项的最小hash值,dx_entry.block记录的是目录文件的逻辑块号。从/etc/mke2fs.conf中也可以看出,这个是格式化文件系统的默认选项:
- [defaults]
- base_features = sparse_super,filetype,resize_inode,dir_index,ext_attr
- default_mntopts = acl,user_xattr
- enable_periodic_fsck = 0
- blocksize = 4096
- inode_size = 256
- inode_ratio = 16384
- [fs_types]
- ext3 = {
- features = has_journal
- }
- ext4 = {
- features = has_journal,extent,huge_file,flex_bg,uninit_bg,dir_nlink,extra_isize
- auto_64-bit_support = 1
- inode_size = 256
- }
如果在 inode 中设置 dir_index 标志,则目录文件的块的组织形式将发生变化,变成了下面定义的这个样子:
- struct dx_root
- {
- struct fake_dirent dot;
- char dot_name[4];
- struct fake_dirent dotdot;
- char dotdot_name[4];
- struct dx_root_info
- {
- __le32 reserved_zero;
- u8 hash_version;
- u8 info_length; /* 8 */
- u8 indirect_levels;
- u8 unused_flags;
- }
- info;
- struct dx_entry entries[0];
- };
当然,首先出现的还是差不多的,第一项是“.”,表示当前目录;第二项是“..”,表示上一级目录,这两个不变。接下来就开始发生改变了。是一个 dx_root_info 的结构,其中最重要的成员变量是 indirect_levels,表示间接索引的层数。接下来我们来看索引项 dx_entry。这个也很简单,其实就是文件名的哈希值和数据块的一个映射关系。
- struct dx_entry
- {
- __le32 hash;
- __le32 block;
- };
那么,找到一个子文件需要如下步骤。1)根据待查找子文件名计算出hash值 2)在当前的全部dx_entry中采用二分查找的方式找到对应的dx_entry 3)根据dx_entry.block记录值读取目录文件对应的逻辑块内容 4)在读取到的block内容中遍历查找匹配的子文件目录项 不难发现,之前的需要读取N + 1个block的困境被简化为只需要读取一个block的内容即可,问题迎刃而解
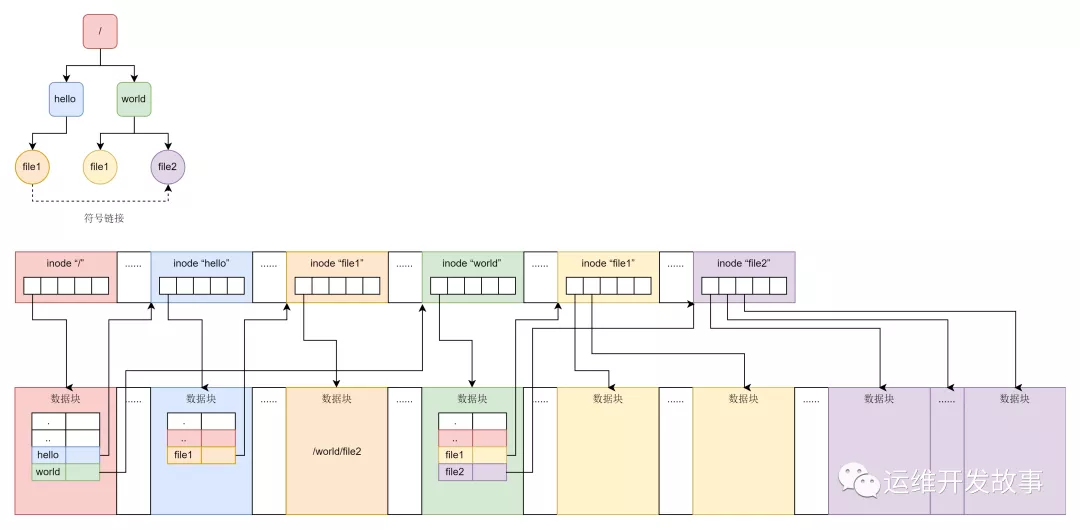
为了表示图中上半部分的那个简单的树形结构,在文件系统上的布局就像图的下半部分一样。无论是文件夹还是文件,都有一个 inode。inode 里面会指向数据块,对于文件夹的数据块,里面是一个表,是下一层的文件名和 inode 的对应关系,文件的数据块里面存放的才是真正的数据。
ext类文件系统的缺点
最大的缺点是它在创建文件系统的时候就划分好一切需要划分的东西,以后用到的时候可以直接进行分配,也就是说它不支持动态划分和动态分配。对于较小的分区来说速度还好,但是对于一个超大的磁盘,速度是极慢极慢的。例如将一个几十T的磁盘阵列格式化为ext4文件系统,可能你会因此而失去一切耐心。除了格式化速度超慢以外,ext4文件系统还是非常可取的。当然,不同公司开发的文件系统都各有特色,最主要的还是根据需求选择合适的文件系统类型。
本文转载自微信公众号「运维开发故事」,可以通过以下二维码关注。转载本文请联系运维开发故事公众号。















