在 Kubernetes 中要保证容器之间网络互通,网络至关重要。而 Kubernetes 本身并没有自己实现容器网络,而是通过插件化的方式自由接入进来。在容器网络接入进来需要满足如下基本原则:
- pod 无论运行在任何节点都可以互相直接通信,而不需要借助 NAT 地址转换实现。
- node 与 pod 可以互相通信,在不限制的前提下,pod 可以访问任意网络。
- pod 拥有独立的网络栈,pod 看到自己的地址和外部看见的地址应该是一样的,并且同个 pod 内所有的容器共享同个网络栈。
容器网络基础
一个 Linux 容器的网络栈是被隔离在它自己的 Network Namespace中,Network Namespace 包括了:网卡(Network Interface),回环设备(Lookback Device),路由表(Routing Table)和 iptables 规则,对于服务进程来讲这些就构建了它发起请求和相应的基本环境。
而要实现一个容器网络,离不开以下 Linux 网络功能:
- 网络命名空间:将独立的网络协议栈隔离到不同的命令空间中,彼此间无法通信。
- Veth Pair:Veth设备对的引入是为了实现在不同网络命名空间的通信,总是以两张虚拟网卡(veth peer)的形式成对出现的。并且,从其中一端发出的数据,总是能在另外一端收到。
- Iptables/Netfilter:Netfilter 负责在内核中执行各种挂接的规则(过滤、修改、丢弃等),运行在内核中;Iptables 模式是在用户模式下运行的进程,负责协助维护内核中 Netfilter 的各种规则表;通过二者的配合来实现整个 Linux 网络协议栈中灵活的数据包处理机制
- 网桥:网桥是一个二层网络虚拟设备,类似交换机,主要功能是通过学习而来的Mac地址将数据帧转发到网桥的不同端口上。
- 路由:Linux系统包含一个完整的路由功能,当IP层在处理数据发送或转发的时候,会使用路由表来决定发往哪里
基于以上的基础,同宿主机的容器时间如何通信呢?
我们可以简单把他们理解成两台主机,主机之间通过网线连接起来,如果要多台主机通信,我们通过交换机就可以实现彼此互通,在 Linux 中,我们可以通过网桥来转发数据。
在容器中,以上的实现是通过 docker0 网桥,凡是连接到 docker0 的容器,就可以通过它来进行通信。要想容器能够连接到 docker0 网桥,我们也需要类似网线的虚拟设备Veth Pair 来把容器连接到网桥上。
我们启动一个容器:
- docker run -d --name c1 hub.pri.ibanyu.com/devops/alpine:v3.8 /bin/sh
然后查看网卡设备:
- docker exec -it c1 /bin/sh
- / # ifconfig
- eth0 Link encap:Ethernet HWaddr 02:42:AC:11:00:02
- inet addr:172.17.0.2 Bcast:172.17.255.255 Mask:255.255.0.0
- UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
- RX packets:14 errors:0 dropped:0 overruns:0 frame:0
- TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
- collisions:0 txqueuelen:0
- RX bytes:1172 (1.1 KiB) TX bytes:0 (0.0 B)
- lo Link encap:Local Loopback
- inet addr:127.0.0.1 Mask:255.0.0.0
- UP LOOPBACK RUNNING MTU:65536 Metric:1
- RX packets:0 errors:0 dropped:0 overruns:0 frame:0
- TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
- collisions:0 txqueuelen:1000
- RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
- / # route -n
- Kernel IP routing table
- Destination Gateway Genmask Flags Metric Ref Use Iface
- 0.0.0.0 172.17.0.1 0.0.0.0 UG 0 0 0 eth0
- 172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth0
可以看到其中有一张 eth0 的网卡,它就是 veth peer 其中的一端的虚拟网卡。
然后通过 route -n 查看容器中的路由表,eth0 也正是默认路由出口。所有对172.17.0.0/16 网段的请求都会从 eth0 出去。
我们再来看 Veth peer 的另一端,我们查看宿主机的网络设备:
- ifconfig
- docker0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
- inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255
- inet6 fe80::42:6aff:fe46:93d2 prefixlen 64 scopeid 0x20<link>
- ether 02:42:6a:46:93:d2 txqueuelen 0 (Ethernet)
- RX packets 0 bytes 0 (0.0 B)
- RX errors 0 dropped 0 overruns 0 frame 0
- TX packets 8 bytes 656 (656.0 B)
- TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
- eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
- inet 10.100.0.2 netmask 255.255.255.0 broadcast 10.100.0.255
- inet6 fe80::5400:2ff:fea3:4b44 prefixlen 64 scopeid 0x20<link>
- ether 56:00:02:a3:4b:44 txqueuelen 1000 (Ethernet)
- RX packets 7788093 bytes 9899954680 (9.2 GiB)
- RX errors 0 dropped 0 overruns 0 frame 0
- TX packets 5512037 bytes 9512685850 (8.8 GiB)
- TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
- lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
- inet 127.0.0.1 netmask 255.0.0.0
- inet6 ::1 prefixlen 128 scopeid 0x10<host>
- loop txqueuelen 1000 (Local Loopback)
- RX packets 32 bytes 2592 (2.5 KiB)
- RX errors 0 dropped 0 overruns 0 frame 0
- TX packets 32 bytes 2592 (2.5 KiB)
- TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
- veth20b3dac: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
- inet6 fe80::30e2:9cff:fe45:329 prefixlen 64 scopeid 0x20<link>
- ether 32:e2:9c:45:03:29 txqueuelen 0 (Ethernet)
- RX packets 0 bytes 0 (0.0 B)
- RX errors 0 dropped 0 overruns 0 frame 0
- TX packets 8 bytes 656 (656.0 B)
- TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
我们可以看到,容器对应的 Veth peer 另一端是宿主机上的一块虚拟网卡叫veth20b3dac,并且可以通过 brctl 查看网桥信息看到这张网卡是在 docker0 上。
- # brctl show
- docker0 8000.02426a4693d2 no veth20b3dac
然后我们再启动一个容器,从第一个容器是否能 ping 通第二个容器。
- $ docker run -d --name c2 -it hub.pri.ibanyu.com/devops/alpine:v3.8 /bin/sh
- $ docker exec -it c1 /bin/sh
- / # ping 172.17.0.3
- PING 172.17.0.3 (172.17.0.3): 56 data bytes
- 64 bytes from 172.17.0.3: seq=0 ttl=64 time=0.291 ms
- 64 bytes from 172.17.0.3: seq=1 ttl=64 time=0.129 ms
- 64 bytes from 172.17.0.3: seq=2 ttl=64 time=0.142 ms
- 64 bytes from 172.17.0.3: seq=3 ttl=64 time=0.169 ms
- 64 bytes from 172.17.0.3: seq=4 ttl=64 time=0.194 ms
- ^C
- --- 172.17.0.3 ping statistics ---
- 5 packets transmitted, 5 packets received, 0% packet loss
- round-trip min/avg/max = 0.129/0.185/0.291 ms
可以看到,能够 ping 通,其原理就是我们 ping 目标 IP 172.17.0.3时,会匹配到我们的路由表第二条规则,网关为0.0.0.0,这就意味着是一条直连路由,通过二层转发到目的地。
要通过二层网络到达172.17.0.3,我们需要知道它的 Mac 地址,此时就需要第一个容器发送一个ARP广播,来通过IP地址查找Mac。
此时 Veth peer 另外一段是 docker0 网桥,它会广播到所有连接它的 veth peer 虚拟网卡去,然后正确的虚拟网卡收到后会响应这个ARP报文,然后网桥再回给第一个容器。
以上就是同宿主机不同容器通过 docker0 通信,如下图所示:
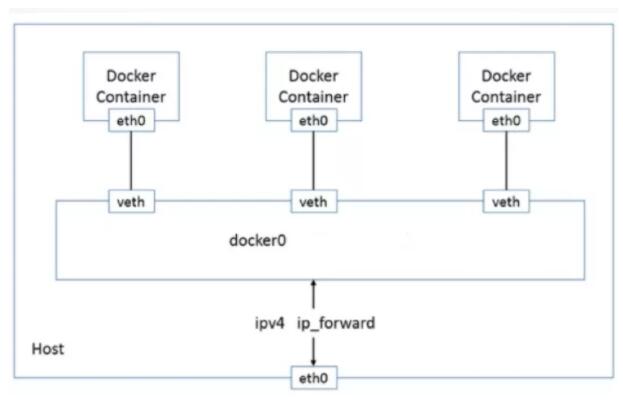
默认情况下,通过 network namespace 限制的容器进程,本质上是通过Veth peer设备和宿主机网桥的方式,实现了不同 network namespace 的数据交换。
与之类似地,当你在一台宿主机上,访问该宿主机上的容器的 IP 地址时,这个请求的数据包,也是先根据路由规则到达 docker0 网桥,然后被转发到对应的 Veth Pair 设备,最后出现在容器里。
跨主机网络通信
在 Docker 的默认配置下,不同宿主机上的容器通过 IP 地址进行互相访问是根本做不到的。为了解决这个问题,社区中出现了很多网络方案。同时 K8s 为了更好的控制网络的接入,推出了 CNI 即容器网络的 API 接口。
它是 K8s 中标准的一个调用网络实现的接口,kubelet通过这个API来调用不同的网络插件以实现不同的网络配置,实现了这个接口的就是CNI插件,它实现了一系列的CNI API接口。目前已经有的包括flannel、calico、weave、contiv等等。
实际上 CNI 的容器网络通信流程跟前面的基础网络一样,只是CNI维护了一个单独的网桥来代替 docker0。这个网桥的名字就叫作:CNI 网桥,它在宿主机上的设备名称默认是:cni0。
cni的设计思想,就是:Kubernetes 在启动 Infra 容器之后,就可以直接调用 CNI 网络插件,为这个 Infra 容器的 Network Namespace,配置符合预期的网络栈。
CNI 插件三种网络实现模式:
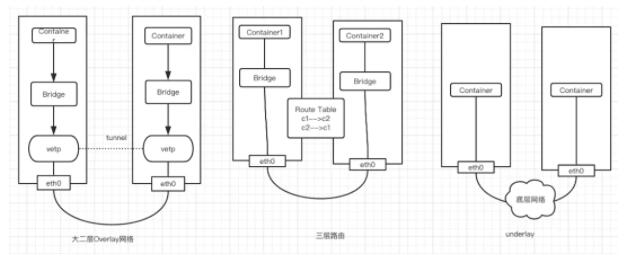
- overlay 模式是基于隧道技术实现的,整个容器网络和主机网络独立,容器之间跨主机通信时将整个容器网络封装到底层网络中,然后到达目标机器后再解封装传递到目标容器。不依赖与底层网络的实现。实现的插件有flannel(UDP、vxlan)、calico(IPIP)等等
- 三层路由模式中容器和主机也属于不通的网段,他们容器互通主要是基于路由表打通,无需在主机之间建立隧道封包。但是限制条件必须依赖大二层同个局域网内。实现的插件有flannel(host-gw)、calico(BGP)等等
- underlay网络是底层网络,负责互联互通。容器网络和主机网络依然分属不同的网段,但是彼此处于同一层网络,处于相同的地位。整个网络三层互通,没有大二层的限制,但是需要强依赖底层网络的实现支持.实现的插件有calico(BGP)等等
我们看下路由模式的一种实现 flannel Host-gw:
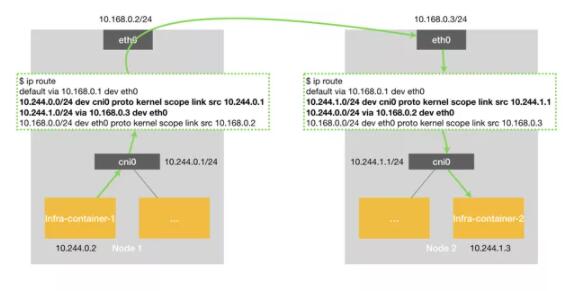
如图可以看到当 node1上container-1 要发数据给 node2 上的 container2 时,会匹配到如下的路由表规则:
- 10.244.1.0/24 via 10.168.0.3 dev eth0
表示前往目标网段 10.244.1.0/24 的 IP 包,需要经过本机 eth0 出去发往的下一跳ip地址为10.168.0.3(node2)。然后到达 10.168.0.3 以后再通过路由表转发 cni 网桥,进而进入到 container2。
以上可以看到 host-gw 工作原理,其实就是在每个 node 节点配置到每个 pod 网段的下一跳为pod网段所在的 node 节点 IP,pod 网段和 node 节点 ip 的映射关系,flannel 保存在etcd或者k8s中。flannel 只需要 watch 这些数据的变化来动态更新路由表即可。
这种网络模式最大的好处就是避免了额外的封包和解包带来的网络性能损耗。缺点我们也能看见主要就是容器ip包通过下一跳出去时,必须要二层通信封装成数据帧发送到下一跳。如果不在同个二层局域网,那么就要交给三层网关,而此时网关是不知道目标容器网络的(也可以静态在每个网关配置pod网段路由)。所以 flannel host-gw 必须要求集群宿主机是二层互通的。
而为了解决二层互通的限制性,calico提供的网络方案就可以更好的实现,calico 大三层网络模式与flannel 提供的类似,也会在每台宿主机添加如下格式的路由规则:
- <目标容器IP网段> via <网关的IP地址> dev eth0
其中网关的 IP 地址不通场景有不同的意思,如果宿主机是二层可达那么就是目的容器所在的宿主机的 IP 地址,如果是三层不同局域网那么就是本机宿主机的网关IP(交换机或者路由器地址)。
不同于 flannel 通过 k8s 或者 etcd 存储的数据来维护本机路由信息的做法,calico是通过BGP 动态路由协议来分发整个集群路由信息。
BGP 全称是 Border Gateway Protocol边界网关协议,linxu原生支持的、专门用于在大规模数据中心为不同的自治系统之间传递路由信息。只要记住BGP简单理解其实就是实现大规模网络中节点路由信息同步共享的一种协议。而BGP这种协议就能代替flannel 维护主机路由表功能。
calico 主要由三个部分组成:
- calico cni插件: 主要负责与kubernetes对接,供kubelet调用使用。
- felix: 负责维护宿主机上的路由规则、FIB转发信息库等。
- BIRD: 负责分发路由规则,类似路由器。
- confd: 配置管理组件。
除此之外,calico 还和 flannel host-gw 不同之处在于,它不会创建网桥设备,而是通过路由表来维护每个pod的通信,如下图所示:
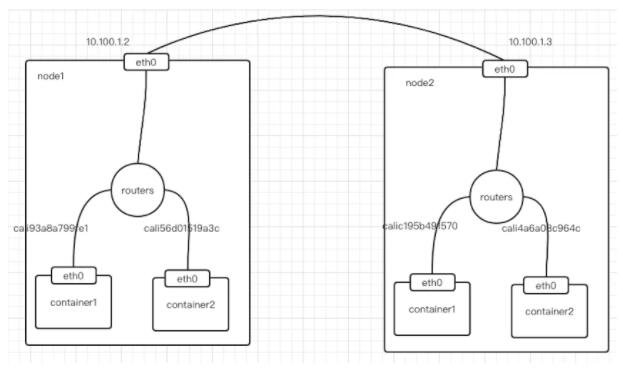
可以看到 calico 的 cni 插件会为每个容器设置一个 veth pair 设备,然后把另一端接入到宿主机网络空间,由于没有网桥,cni 插件还需要在宿主机上为每个容器的 veth pair设备配置一条路由规则,用于接收传入的IP包,路由规则如下:
- 10.92.77.163 dev cali93a8a799fe1 scope link
以上表示发送10.92.77.163的IP包应该发给cali93a8a799fe1设备,然后到达另外一段容器中。
有了这样的veth pair设备以后,容器发出的IP包就会通过veth pair设备到达宿主机,然后宿主机根据路有规则的下一条地址,发送给正确的网关(10.100.1.3),然后到达目标宿主机,在到达目标容器。
- 10.92.160.0/23 via 10.106.65.2 dev bond0 proto bird
这些路由规则都是felix维护配置的,而路由信息则是calico bird组件基于BGP分发而来。calico实际上是将集群里所有的节点都当做边界路由器来处理,他们一起组成了一个全互联的网络,彼此之间通过BGP交换路由,这些节点我们叫做BGP Peer。
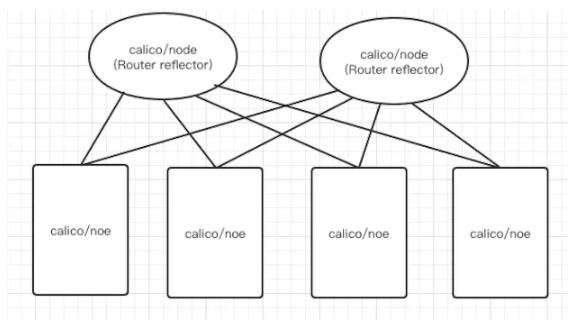
需要注意的是calico 维护网络的默认模式是 node-to-node mesh ,这种模式下,每台宿主机的BGP client都会跟集群所有的节点BGP client进行通信交换路由。这样一来,随着节点规模数量N的增加,连接会以N的2次方增长,会集群网络本身带来巨大压力。
所以一般这种模式推荐的集群规模在50节点左右,超过50节点推荐使用另外一种RR(Router Reflector)模式,这种模式下,calico 可以指定几个节点作为RR,他们负责跟所有节点 BGP client 建立通信来学习集群所有的路由,其他节点只需要跟RR节点交换路由即可。这样大大降低了连接数量,同时为了集群网络稳定性,建议RR>=2.
以上的工作原理依然是在二层通信,当我们有两台宿主机,一台是10.100.0.2/24,节点上容器网络是10.92.204.0/24;另外一台是10.100.1.2/24,节点上容器网络是10.92.203.0/24,此时两台机器因为不在同个二层所以需要三层路由通信,这时calico就会在节点上生成如下路由表:
- 10.92.203.0/23 via 10.100.1.2 dev eth0 proto bird
这时候问题就来了,因为10.100.1.2跟我们10.100.0.2不在同个子网,是不能二层通信的。这之后就需要使用Calico IPIP模式,当宿主机不在同个二层网络时就是用overlay网络封装以后再发出去。如下图所示:
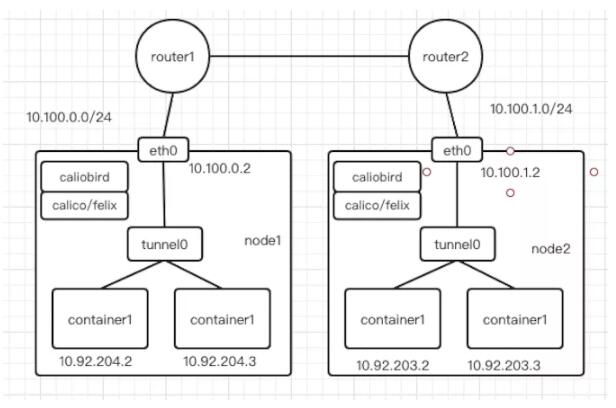
IPIP模式下在非二层通信时,calico 会在node节点添加如下路由规则:
- 10.92.203.0/24 via 10.100.1.2 dev tunnel0
可以看到尽管下一条任然是node的IP地址,但是出口设备却是tunnel0,其是一个IP隧道设备,主要有Linux内核的IPIP驱动实现。会将容器的ip包直接封装宿主机网络的IP包中,这样到达node2以后再经过IPIP驱动拆包拿到原始容器IP包,然后通过路由规则发送给veth pair设备到达目标容器。
以上尽管可以解决非二层网络通信,但是仍然会因为封包和解包导致性能下降。如果calico 能够让宿主机之间的router设备也学习到容器路由规则,这样就可以直接三层通信了。比如在路由器添加如下的路由表:
- 10.92.203.0/24 via 10.100.1.2 dev interface1
而node1添加如下的路由表:
- 10.92.203.0/24 via 10.100.1.1 dev tunnel0
那么node1上的容器发出的IP包,基于本地路由表发送给10.100.1.1网关路由器,然后路由器收到IP包查看目的IP,通过本地路由表找到下一跳地址发送到node2,最终到达目的容器。这种方案,我们是可以基于underlay 网络来实现,只要底层支持BGP网络,可以和我们RR节点建立EBGP关系来交换集群内的路由信息。
以上就是kubernetes 常用的几种网络方案了,在公有云场景下一般用云厂商提供的或者使用flannel host-gw这种更简单,而私有物理机房环境中,Calico项目更加适合。根据自己的实际场景,再选择合适的网络方案。