












大家好,我是卡颂。
我的女朋友是个铁憨憨,又菜又爱玩。
铁憨憨:卡卡,最近好多同事都在聊React18,你给我讲讲呗?我要你用最通俗的语言把最底层的知识讲明白,老娘的时间很宝贵的。
我:好啊,难得你要学习,这是18所有新特性,你想先看哪个?
说着,我把屏幕转向她。
铁憨憨:“这个名字最长,一串英文一看就很厉害”
我一看,她指着Automatic batching(自动批处理)
什么是批处理
铁憨憨:“批处理,是不是和批发市场搞批发一个意思?”
虽然对这个比喻很无语,但不得不承认:还真挺像!
在React中,开发者通过调用this.setState(或useState的dispatch方法)触发状态更新。
状态更新可能最终反映为视图更新(取决于是否有DOM变化)。
开发者早已接受一个显而易见的设定:「状态」与「视图」是一一对应的。
但是,让我们站在React团队的角度思考一个问题:
- 从this.setState调用到最终视图更新,中间需要经过源码内部的一系列工作。这一系列工作应该是同步还是异步的呢?
如下例子中,a初始状态为0,当触发onClick,调用两次this.setState:
- // ...省略无关信息
- state = {
- a: 0
- }
- onClick() {
- this.setState({a: 1});
- console.log('a is:', this.state.a);
- this.setState({a: 2});
- }
- render() {
- const {a} = this.state;
- return <p onClick={this.onClick}>{a}</p>;
- }
如果流程是异步的(即console.log打印a is:0),会有两个潜在问题:
问题1:中间视图状态
当状态更新互相之间都是异步的,那么例子中页面上的数字会从0先变为1,再变为2。
显然更期望的行为是:数字直接从0变为2。
问题2:状态更新的竞争问题
{a: 1}与{a: 2}的状态变化谁先反映到视图更新?
毕竟在异步情况下,即使this.setState({a: 1})先触发,也可能this.setState({a: 2})的流程先完成。
开发者可不希望用户点击时,有时候数字从0变为2,有时候变为1。
铁憨憨:“好复杂啊,那就改为同步呗,能同时解决这两个问题,还简单!”
确实,如果状态更新都是同步的,那么:
- 同步流程发生在同一个task(宏任务),不会出现视图的中间状态
- 更新之间有明确的顺序,不会出现「竞争问题」
但是,同步流程也意味着当更新发生时,浏览器会一直被JS线程阻塞(执行更新流程)。
如果更新流程很复杂(应用很大),或同时触发很多更新,那么浏览器就会掉帧,表现为「浏览器卡顿」。
那该怎么办呢?React团队给出的解决办法就是:「批处理」(batchedUpdates)。
- 批处理:React会尝试将同一上下文中触发的更新合并为一个更新
在我们刚才的例子中:
- onClick() {
- this.setState({a: 1});
- console.log('a is:', this.state.a);
- this.setState({a: 2});
- }
两次this.setState改变的状态会按顺序保存下来,最终只会触发一次状态更新。
这样做的好处显而易见:
- 合并不必要的更新,减少更新流程调用次数
- 状态按顺序保存下来,更新时不会出现「竞争问题」
- 最终触发的更新是异步流程,减少浏览器掉帧可能性
就像到批发市场拉货。如果老板派几辆小货车去,可能由于路上耽搁,先去的车不一定先回(竞争问题)。
还不如提前统计好要拉的货,派一辆大货车去,一次拉完了再回(批处理)。
铁憨憨:“我明白了!不过为什么叫「自动批处理」?难不成像枪一样还有手动、半自动?”
是的,v18的「批处理」是自动的。
v18之前的React使用半自动「批处理」。
同时,React提供了一个API——unstable_batchedupdates,这就是手动「批处理」。
半自动批处理
要聊「自动批处理」,首先得聊「半自动批处理」。
在v18之前,只有事件回调、生命周期回调中的更新会批处理,比如上例中的onClick。
而在promise、setTimeout等异步回调中不会批处理。
究其原因,让我们看看批处理源码(你不需要理解其中变量的意义,这不重要):
- export function batchedUpdates<A, R>(fn: A => R, a: A): R {
- const prevExecutionContext = executionContext;
- executionContext |= BatchedContext;
- try {
- return fn(a);
- } finally {
- executionContext = prevExecutionContext;
- // If there were legacy sync updates, flush them at the end of the outer
- // most batchedUpdates-like method.
- if (executionContext === NoContext) {
- resetRenderTimer();
- flushSyncCallbacksOnlyInLegacyMode();
- }
- }
- }
可以看到,传入一个回调函数fn,此时会通过「位运算」为代表当前执行上下文状态的变量executionContext增加BatchedContext状态。
拥有这个状态位代表当前执行上下文需要批处理。
在fn执行过程中,其获取到的全局变量executionContext都会包含BatchedContext。
最终fn执行完后,进入try...finally逻辑,将executionContext恢复为之前的上下文。
曾经React源码内部,执行onClick时的逻辑类似如下:
- batchedUpdates(onClick, e);
在onClick内部的this.setState中,获取到的executionContext包含BatchedContext,不会立刻进入更新流程。
等退出该上下文后再统一执行一次更新流程,这就是「半自动批处理」。
铁憨憨:“既然batchedUpdates是React自动调用的,为啥是「半自动批处理」?”
原因在于batchedUpdates方法是同步调用的。
如果fn有异步流程,比如如下例子:
- onClick() {
- setTimeout(() => {
- this.setState({a: 3});
- this.setState({a: 4});
- })
- }
那么在真正执行this.setState时batchedUpdates早已执行完,executionContext中已经不包含BatchedContext。
此时触发的更新不会走批处理逻辑。
所以这种「只对同步流程中的this.setState进行批处理」,只能说是「半自动」。
手动批处理
为了弥补「半自动批处理」的不灵活,ReactDOM中导出了unstable_batchedUpdates方法供开发者手动调用。
比如如上例子,可以这样修改:
- onClick() {
- setTimeout(() => {
- ReactDOM.unstable_batchedUpdates(() => {
- this.setState({a: 3});
- this.setState({a: 4});
- })
- })
- }
那么两次this.setState调用时上下文中全局变量executionContext中会包含BatchedContext。
铁憨憨:“你这么说我就理解批处理的实现了。不过v18是怎么实现在各种上下文环境都能批处理呢?有点神奇啊!”
自动批处理
v18实现「自动批处理」的关键在于两点:
- 增加调度的流程
- 不以全局变量executionContext为批处理依据,而是以更新的「优先级」为依据
铁憨憨:“怎么冒出个「优先级」?这是什么鬼?”
我:“那我先给你介绍介绍「更新」以及「优先级」是什么意思吧。”
优先级的意思
调用this.setState后源码内部会依次执行:
- 根据当前环境选择一个「优先级」
- 创造一个代表本次更新的update对象,赋予他步骤1的优先级
- 将update挂载在当前组件对应fiber(虚拟DOM)上
- 进入调度流程
以如下例子来说:
- onClick() {
- this.setState({a: 3});
- this.setState({a: 4});
- }
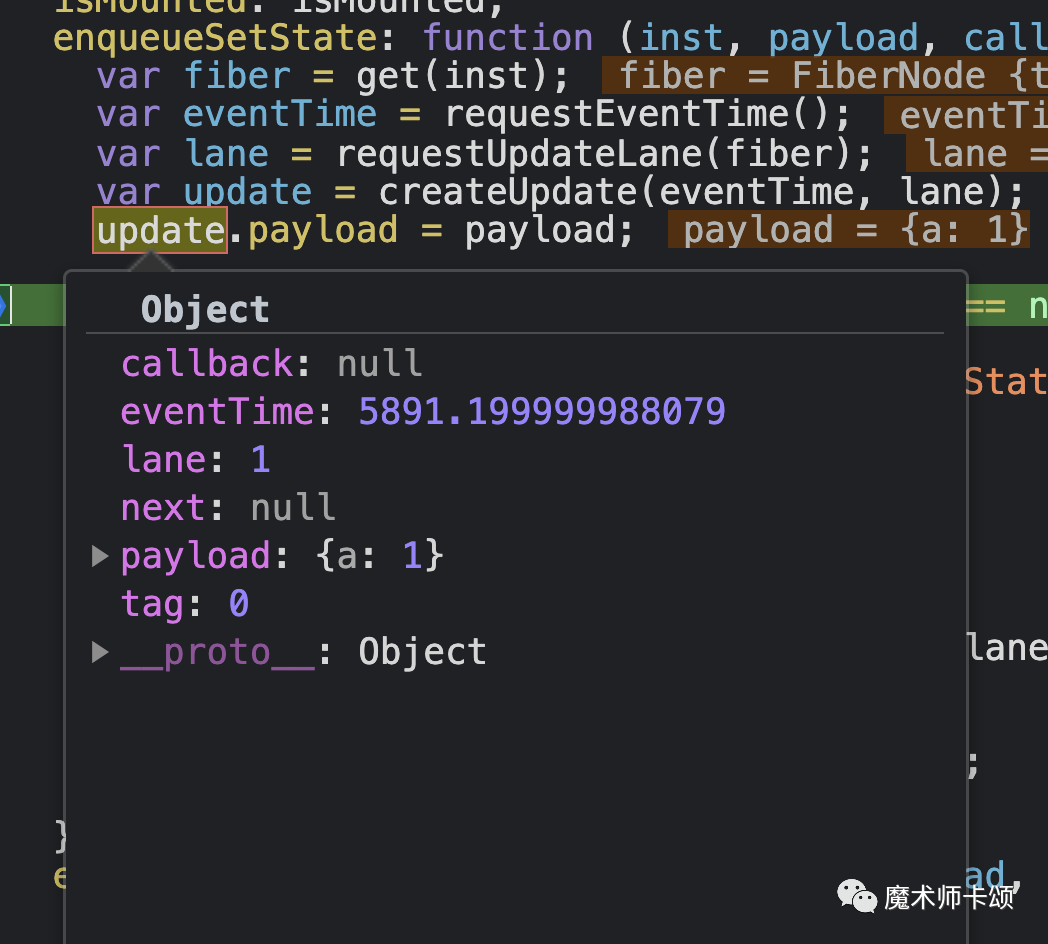
第一次执行this.setState创造的update数据结构如下:
第二次执行this.setState创造的update数据结构如下:
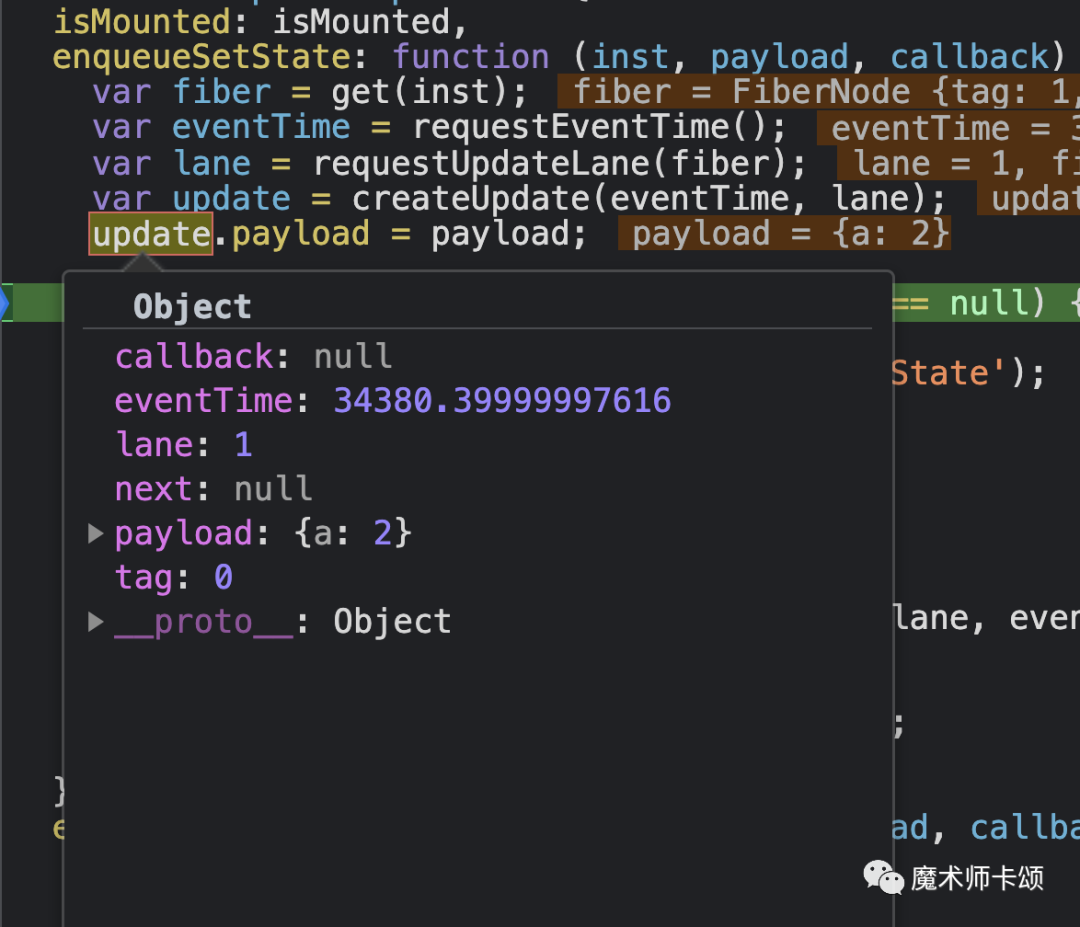
其中lane代表该update的优先级。
在v18,不同场景下触发的更新拥有不同「优先级」,比如:
- 如上例子中事件回调中的this.setState会产生同步优先级的更新,这是最高的优先级(lane为1)
为了对比,我们将如上代码放入setTimeout中:
- onClick() {
- setTimeout(() => {
- this.setState({a: 3});
- this.setState({a: 4});
- })
- }
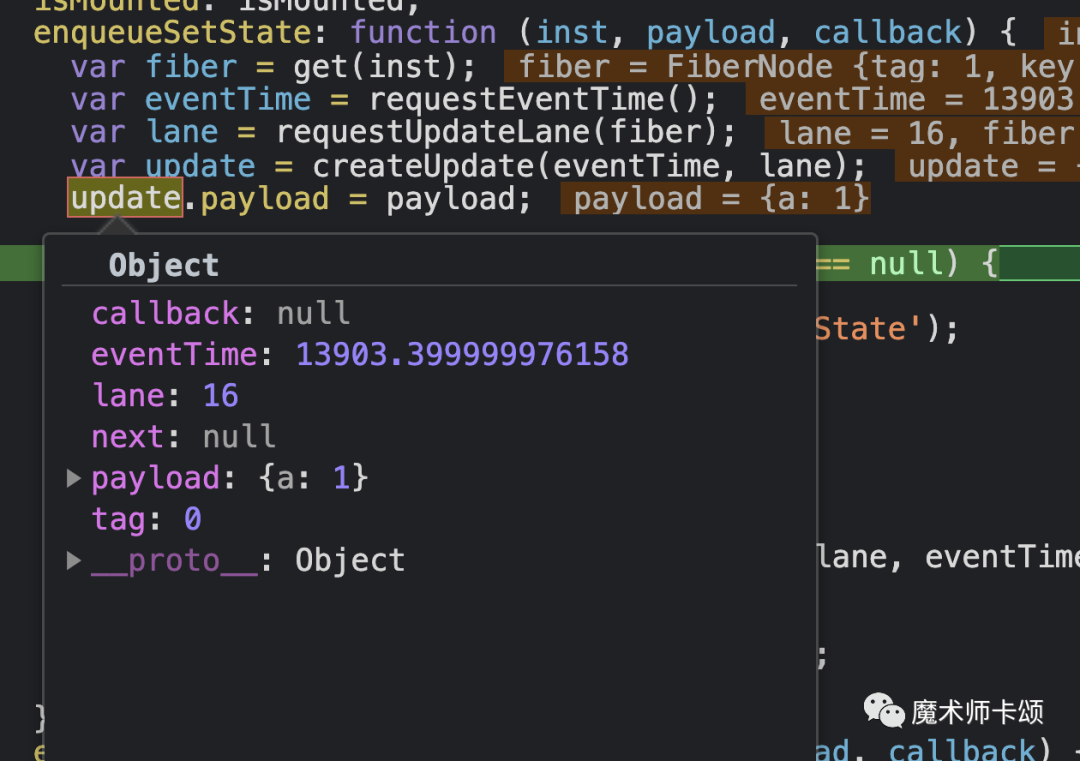
第一次执行this.setState创造的update数据结构如下:
第二次执行this.setState创造的update数据结构如下:
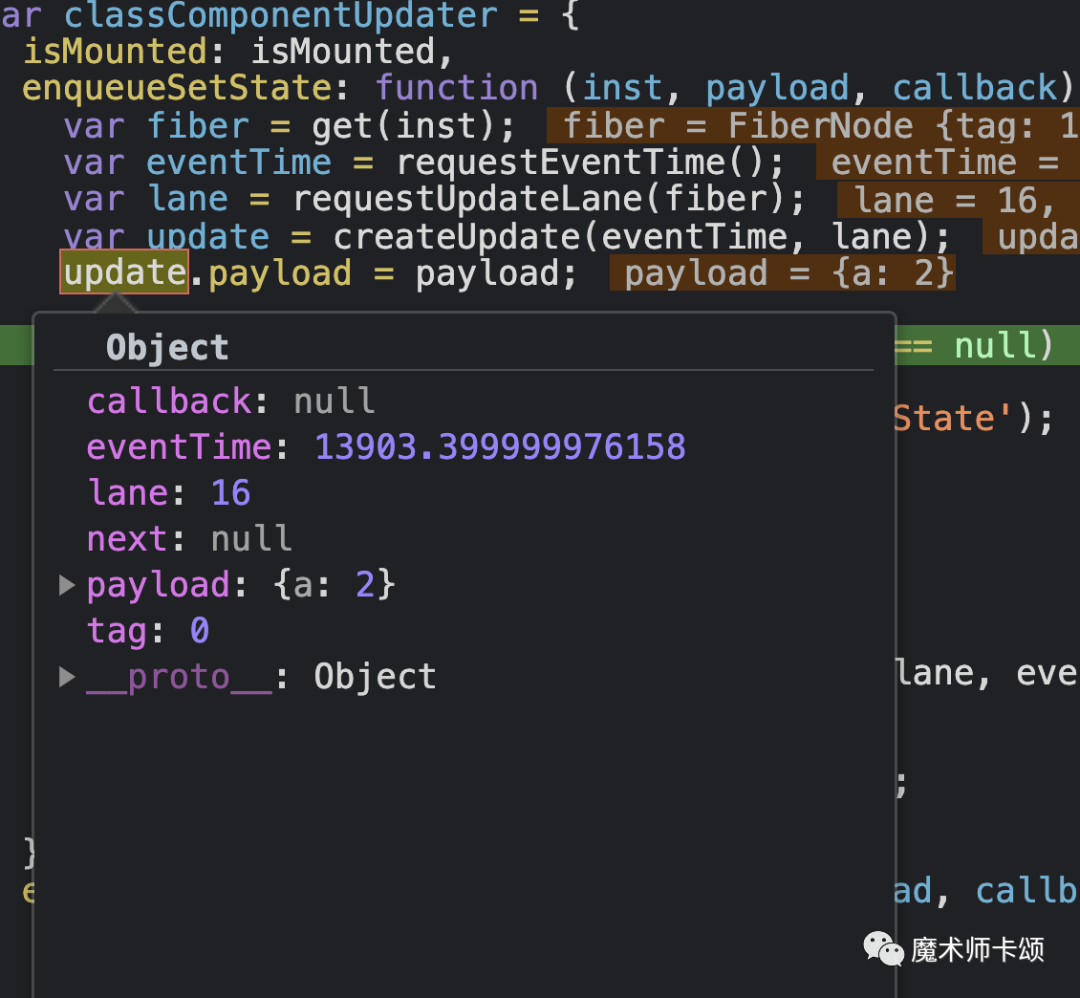
lane为16,代表Normal(即一般优先级)。
铁憨憨:“所以每次调用this.setState会产生update对象,根据调用的场景他会拥有不同的lane(优先级),是吧?”
我:“完全正确!”。
铁憨憨:“那这和「批处理」有什么关系呢?”
我:“别急,这就是接下来进入调度流程做的事了。”
调度流程
在组件对应fiber挂载update后,就会进入「调度流程」。
试想,一个大型应用,在某一时刻,应用的不同组件都触发了更新。
那么在不同组件对应的fiber中会存在不同优先级的update。
「调度流程」的作用就是:选出这些update中优先级最高的那个,以该优先级进入更新流程。
让我们节选部分「调度流程」的源码:
- function ensureRootIsScheduled(root, currentTime) {
- // 获取当前所有优先级中最高的优先级
- var nextLanes = getNextLanes(root, root === workInProgressRoot ? workInProgressRootRenderLanes : NoLanes);
- // 本次要调度的优先级
- var newCallbackPriority = getHighestPriorityLane(nextLanes);
- // 已经存在的调度的优先级
- var existingCallbackPriority = root.callbackPriority;
- if (existingCallbackPriority === newCallbackPriority) {
- return;
- }
- // 调度更新流程
- newCallbackNode = scheduleCallback(schedulerPriorityLevel, performConcurrentWorkOnRoot.bind(null, root));
- root.callbackPriority = newCallbackPriority;
- root.callbackNode = newCallbackNode;
- }
节选后的调度流程大体是:
- 获取当前所有优先级中最高的优先级
- 将步骤1的优先级作为本次调度的优先级
- 看是否已经存在一个调度
- 如果已经存在调度,且和当前要调度的优先级一致,则return
- 不一致的话就进入调度流程
可以看到,调度的最终目的是在一定时间后执行performConcurrentWorkOnRoot,正式进入更新流程。
还是以上面的例子来说:
- onClick() {
- this.setState({a: 3});
- this.setState({a: 4});
- }
第一次调用this.setState,进入「调度流程」后,不存在existingCallbackPriority。
所以会执行调度:
- newCallbackNode = scheduleCallback(schedulerPriorityLevel, performConcurrentWorkOnRoot.bind(null, root));
第二次调用this.setState,进入「调度流程」后,已经存在existingCallbackPriority,即第一次调用产生的。
此时比较两者优先级:
- if (existingCallbackPriority === newCallbackPriority) {
- return;
- }
由于两个更新都是在onClick中触发,拥有同样优先级,所以return。
按这个逻辑,即使多次调用this.setState,如:
- onClick() {
- this.setState({a: 3});
- this.setState({a: 4});
- this.setState({a: 5});
- this.setState({a: 6});
- }
只有第一次调用会执行调度,后面几次执行由于优先级和第一次一致会return。
当一定时间过后,第一次调度的回调函数performConcurrentWorkOnRoot会执行,进入更新流程。
由于每次执行this.setState都会创建update并挂载在fiber上。
所以即使只执行一次更新流程,还是能将状态更新到最新。
这就是以「优先级」为依据的「自动批处理」逻辑。
总结
通过本次讲解,女朋友不仅学习了「批处理」的意义。还了解了「手动/半自动/自动」三种形式的批处理。
最后我们还聊到了批处理的源码实现逻辑。


















