Hologres(中文名交互式分析)是阿里云自研的一站式实时数仓,这个云原生系统融合了实时服务和分析大数据的场景,全面兼容PostgreSQL协议并与大数据生态无缝打通,能用同一套数据架构同时支持实时写入实时查询以及实时离线联邦分析。它的出现简化了业务的架构,与此同时为业务提供实时决策的能力,让大数据发挥出更大的商业价值。从阿里集团诞生到云上商业化,随着业务的发展和技术的演进,Hologres也在持续不断优化核心技术竞争力,为了让大家更加了解Hologres,我们计划持续推出Hologres底层技术原理揭秘系列,从高性能存储引擎到高效率查询引擎,高吞吐写入到高QPS查询等,全方位解读Hologres,请大家持续关注!
本期我们将带来Hologres高性能原生加速查询MaxCompute的技术原理解析。
随着数据收集手段不断丰富,行业数据大量积累,数据规模已增长到了传统软件行业无法承载的海量数据(TB、PB、EB)级别,MaxCompute(原名ODPS)也因此应运而生,致力于批量结构化数据的存储和计算,提供海量数据仓库的解决方案及分析建模服务,是一种快速、完全托管的EB级数据仓库解决方案。
Hologres在离线大数据场景上与MaxCompute天然无缝融合,无需数据导入导出就能实现加速查询MaxCompute,全兼容访问各种MaxCompute文件格式,实现对PB级离线数据的毫秒级交互式分析。而这一切的背后,都离不开Hologres背后的执行器SQE(S Query Engine),通过SQE实现对MaxCompute的Native访问,然后再结合Hologres高性能分布式执行引擎HQE的处理,达到极致性能。
Hologres加速查询MaxCompute主要有以下几个优势:
高性能:可以直接对MaxCompute数据加速查询,具有亚秒级响应的查询性能,在OLAP场景可以直接即席查询,满足绝大多数报表等分析场景。
低成本:MaxCompute经过数年的发展,用户在MaxCompute上存储了大量数据,不需要冗余一份存储可直接进行访问;另一方面用户可以只需将部分高性能场景的数据迁移到SSD上,报表等分析场景的数据可以存储在MaxCompute进一步降低成本。
更高效:实现对MaxCompute的Native访问,无需迁移和导入数据,就可以高性能和全兼容的访问各种MaxCompute文件格式,以及Hash/Range Clustered Table等复杂表,降低用户的使用成本。
SQE 架构介绍
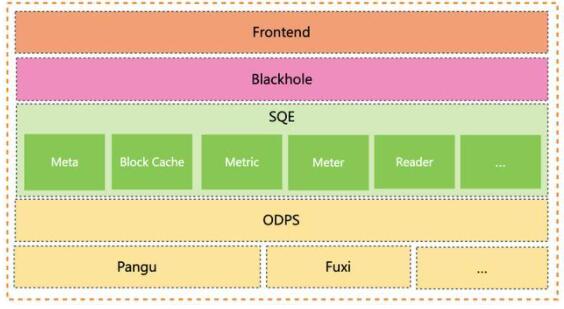
如上图所示是SQE的整体架构,可以看出整个架构也是非常简单。MaxCompute的数据统一存储在Pangu,当Hologres执行一条Query去加速查询MaxCompute的数据时,在Hologres端:
Hologres Frontend通过RPC向SQE Master请求获取Meta等相关信息。
Hologres Blackhole 通过 RPC 向 SQE Executor 请求获取具体的数据相关信息。
SQE由两种角色的进程组成:
SQE Master负责处理Meta相关的请求,主要负责获取表、分区元数据、鉴权以及文件分片等功能。
SQE Executor作为SQE的核心,负责具体读取数据请求,涉及Block Cache、预读取、UDF 处理、表达式下推处理、索引处理、Metric、Meter等等功能。
MaxCompute外表引擎核心技术创新
基于SQE的架构,能做到对MaxCompute的数据高性能加速查询,主要是基于以下技术创新优势:
1)抽象分布式外表
结合MaxCompute的分布式特性,Hologres抽象了一个分布式的外表,来支持访问MaxCompute分布式数据。目前可支持访问跨集群的MaxCompute分布式盘古文件,并按MaxCompute计算集群就近读取。
2)和 MaxCompute Meta无缝互通,支持带版本的元数据缓存
SQE和MaxCompute 的 Meta 无缝互通,可以做到 Meta 和 Data 实时获取,支持通过Import Foreign Schema命令,自动同步MaxCompute的元数据到Hologres的外表,实现外表的自动创建,结构自动更新。
3)支持UDF/表达式下推
SQE 通过支持 UDF/表达式下推,来实现用户自定义的UDF计算;将表达式下推可以减少无用的数据传输带来的开销,进一步提升性能。
4)异步ORC Reader,异步prefetch
目前MaxCompute大部分数据为ORC格式,在Hologres V0.10及以上版本,Hologres更新了执行引擎,使用异步 Reader 进行更高效的异步读取,还支持异步prefetch,进一步降低读取延迟;此外Hologres支持了 IO 合并、LazyRead、Lazy Decoding 等一些列的优化技术手段,来降低在 IO 在整个查询上的延迟,以带来极致性能。
5)支持Block Cache
为了避免每次读数据都用IO到文件中取,SQE同样使用BlockCache把常用和最近用的数据放在内存中,减少不必要的IO,加快读的性能。在同一个节点内,通过一致性Hash实现将相同访问的数据共享一个Block Cache。 比如在Scan 场景可带来2倍以上的性能提升,大大提升查询性能。
6)常驻进程,减少调度开销
传统的进程模型等架构需要动态实时的创建进程等调度操作,带来了较大的调度开销。SQE 采用常驻进程模式,避免不必要的调度开销,此外还可以大大提升Block Cache的命中率和有效使用率。
7)Network Shuffle,减少落盘开销
Network Shuffle需要提供一种快速且稳定的容错机制。由于Network Shuffle必须保证发送端和接收端进程同时alive才能完成数据shuffle。同样的,如果采用传统落盘的方式来进行Network Shuffle的Retry,虽然能够保证稳定性,但是可能会在Retry过程中由于磁盘IO引入比较大的性能overhead。为了解决这个问题,我们优化了分阶段调度来解决快速稳定的容错问题。
MaxCompute外表引擎升级到HQE
上面提到了我们通过SQE进行加速查询MaxCompute外表,通过SQE查询时性能可以做到很好,但是和Hologres交互时中间会有一层RPC 交互,在数据量较大时网络会存在一定瓶颈。
因此我们基于Hologres已有的能力,在Hologres V0.10及以上版本我们对执行引擎进行了优化,支持Hologres HQE查询引擎直读MaxCompute 表,在性能上得到进一步的提升,较SQE方式读取有 30%以上的性能提升。
这主要得益于以下几个方面:
1) 节省了 SQE 和 Hologres中间 RPC 的交互,相当于节省一次数据的序列化和反序列化,在性能上得到进一步的提升。
2) 可以复用Hologres的Block Cache,这样第二次查询时无需访问存储,避免存储IO,直接从内存访问数据,更好的加速查询。
3) 可以复用已有的Filter 下推能力,减少需要处理的数据量。
4) 在底层的IO层实现了预读和Cache,更进一步加速Scan时的性能。
以下是某客户某实际在线业务查询的性能数据:
执行817个SQL,总体性能提升70%,其中长 Query 提升80%以上。
说明:该优化目前已在Hologres V0.10上线,欢迎点击查看文档使用。
MaxCompute加速场景选择
在Hologres中加速查询MaxCompute有两种方式:
1)创建外表(数据还是存储在MaxCompute中),性能相比在MaxCompute中查询会有2-5倍的提升
2)导入内表,性能相比外表约有10-100倍的提升
创建外表的方式其原理就是PostgreSQL中的Foreign Data Wrappers,通过外部访问接口,来访问存储在外部的数据。建议您使用更方便的IMPORT FOREIGN SCHEMA 方式来创建外表,可以更好的简化元数据的同步,无需关注字段类型映射等。
直接建外表并的方式实际上是利用查询引擎的优化能力来提高效率的,但是没有利用到Hologres的索引能力。所以当把外表导到内表的时候,可以根据查询的方式指定内表的索引结构,通过这些索引能力带来更高的查询性能。这就是外表导入内表,内表的性能更好的原因,可以充分发挥数仓的索引优化能力。
目前这两种方式主要对比如下:
从上面对比可以看出:
如果您是数据量很大、对性能有很高的要求时(比如100ms内等),对查询延迟敏感,对查询有SLA要求时,建议您将数据导入Hologres内表,进行查询访问。
如果是临时性的探索性分析,或者对延迟不敏感的内部业务,可以使用MaxCompute外表方式,减少数据移动。
除上述场景外,您可以根据具体业务情况选择合适的使用场景。
MaxCompute与Hologres的组合关系
上面介绍了很多Hologres外表查询引擎如何加速查询MaxCompute的场景,但并不是说所有类型的查询都适合在Hologres的外表引擎上执行。
Hologres是针对交互式分析场景设计的同步的查询引擎,面向的是大数据进,小数据出的场景,典型用在Serving和Analytics的场景。而MaxCompute是针对海量数据加工处理处理场景设计的异步的数据加工引擎,面向的是大数据进,大数据出的场景,典型用在ETL的场景。在ETL的场景,作业异步提交,IO接口针对Scan优化,计算过程需要节点的冗余设计支撑高可用,需要计算状态落盘从而可以在失败时自动重试,而这些都是Hologres不具备的能力。因此MaxCompute+Hologres组合在一起,形成了数据加工+服务的一站式体验,减少了数据的隔离和冗余,可以为大数据数仓提供合理的解决方案架构,支撑实时离线一体化的开发体验。
总结
Hologres通过SQE与MaxCompute深度整合,充分利用Hologres和MaxCompute的优势,以极致性能为目标,直接就能加速查询MaxCompute数据,让用户更方便高效的进行交互式分析,同时也降低了极大的分析成本,实现离线数仓服务一体化。