IO的分类
文件读写方式的各种差异,导致 I/O 的分类多种多样。最常见的有,
- 缓冲与非缓冲 I/O。根据是否使用了标准库的缓存接口,自己编写的缓存等:
1.缓冲 I/O,是指利用标准库缓存来加速文件的访问,而标准库内部再通过系统调度访问文件。
2.非缓冲 I/O,是指直接通过系统调用来访问文件,不再经过标准库缓存。
- 直接与非直接 I/O。根据是否使用了内核的缓存。使用内核缓存的是非直接io。open系统调用O_DIRECT参数:
1.直接 I/O,是指跳过操作系统的页缓存,直接跟文件系统交互来访问文件。
2.非直接 I/O 正好相反,文件读写时,先要经过系统的页缓存,然后再由内核或额外的系统调用,真正写入磁盘。
- 同步的阻塞与非阻塞 I/O。根据应用程序是否阻塞自身运行,可以把文件 I/O 分为阻塞 I/O 和非阻塞 I/O:
1.阻塞 I/O,是指应用程序执行 I/O 操作后,如果没有获得响应,就会阻塞当前线程,自然就不能执行其他任务。
2.非阻塞 I/O,是指应用程序执行 I/O 操作后,不会阻塞当前的线程,而会立刻返回。设置 O_NONBLOCK 标志,就表示用非阻塞方式访问,可以继续执行其他的任务,随后再通过轮询或者事件通知的形式,获取调用的结果。严格讲是把阻塞点的位置换了(select,poll,epoll等)。主要是使用在标准输出和网络上。
- 同步与异步 I/O 。根据是否等待响应结果,可以把文件 I/O 分为同步和异步 I/O:
1.同步 I/O,是指应用程序执行 I/O 操作后,要一直等到整个 I/O 完成后,才能获得 I/O 响应。
2.异步 I/O,是指应用程序执行 I/O 操作后,不用等待完成和完成后的响应,而是继续执行就可以。等到这次 I/O 完成后,响应会用事件通知的方式,告诉应用程序。
Linux上的文件系统 I/O
进程要想往文件系统里面读写数据,需要很多层的组件一起合作。具体是怎么合作的呢?我们一起来看一看。
在应用层,进程在进行文件读写操作时,可通过系统调用如 sys_open、sys_read、sys_write 等。在内核,每个进程都需要为打开的文件,维护一定的数据结构。在内核,整个系统打开的文件,也需要维护一定的数据结构。
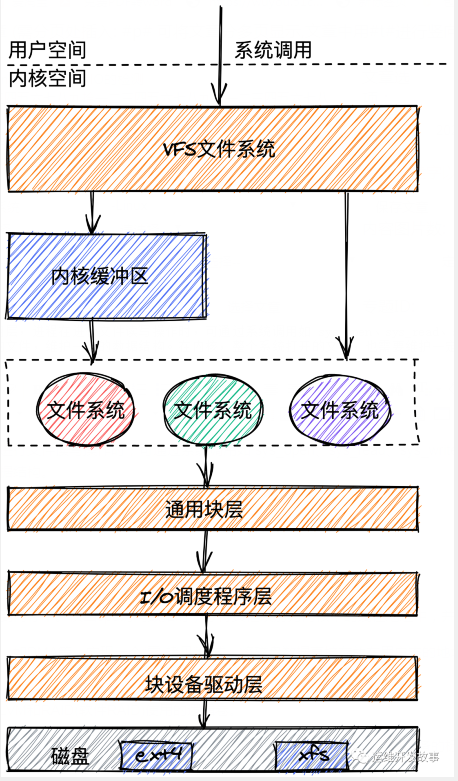
通用块层
通用块层是一个内核组件,它处理来自系统中的所有块设备的请求。
- 将数据从磁盘映射到内存中。仅当cpu访问数据时,才将页框映射为内核中的线性地址中,并在数据访问结束时取消映射。
- 通过一些附件手段,如DMA等,实现一个“零-拷贝”模式,将磁盘数据直接存放在用户态的地址空间中而不是首先复制到内核地址空间。因为,内核为I/O数据传送使用的缓冲区所在的叶框就映射在进程的用户态线性地址中。
- 管理逻辑卷,例如LVM和RAID(软件RAID)使用的逻辑卷。
通用块层是 Linux 磁盘 I/O 的核心。向上,它为文件系统和应用程序,提供访问了块设备的标准接口;向下,把各种异构的磁盘设备,抽象为统一的块设备,并会对文件系统和应用程序发来的 I/O 请求进行重新排序、请求合并等,提高了磁盘访问的效率。
I/O调度程序层
事实上,Linux 内核支持四种 I/O 调度算法,分别是 NOOP、CFQ 、DeadLine与Anticipatory。这里我也分别介绍一下。
第一种 NOOP ,也被称为电梯算法。是最简单的一种 I/O 调度算法。它实际上是一个先入先出的队列,只做一些最基本的请求合并,常用于 SSD 磁盘。
第二种 CFQ(Completely Fair Scheduler),也被称为完全公平调度器,是现在很多发行版的默认 I/O 调度器,它为每个进程维护了一个 I/O 调度队列,并按照时间片来均匀分布每个进程的 I/O 请求。
类似于进程 CPU 调度,CFQ 还支持进程 I/O 的优先级调度,所以它适用于运行大量进程的系统,像是桌面环境、多媒体应用等。
第三种 DeadLine 最后期限调度算法。使用了四个队列。其中两个排序队列分别包含读和写请求,其中的请求是根据起始扇区排序的。另外两个最后期限队列包含了相同的读和写请求,但是这是根据它们的最后期限排队的。可以提高机械磁盘的吞吐量,并确保达到最终期限(deadline)的请求被优先处理。此算法在全局吞吐量和延迟方面做了权衡,牺牲了一定的全局吞吐量来避免饥饿请求的可能。当系统存在大量顺序I/O请求的时候,此算法可能导致I/O请求无法被很好的排序,引发频繁寻道。
第四种 Anticipatory 预期算法。借用了“最后期限调度算法”的基本机制:两个最后期限队列和两个排序队列,I/O调度程序在读和写请求之间交互扫描排序队列,不过更倾向于读请求。扫描基本是连续的,除非有某个请求超时。为每个读IO都设置了大约7ms的等待时间窗口。如果在这7ms内OS收到了相邻位置的读IO请求,就可以立即满足。为了满足随机IO和顺序IO混合的场景,此算法适合写入较多的环境,不适合MySQL等随机读取较多的数据库环境。
磁盘IO检测
在磁盘测试中最关心的几个指标分别为:
- iops(每秒执行的IO次数)、bw(带宽,每秒的吞吐量)、lat(每次IO操作的延迟)
- 当每次IO操作的block较小时,如512bytes/4k/8k等,测试的主要是iops
- 当每次IO操作的block较大时,如256k/512k/1M等,测试的主要是bw
使用fio工具来进行磁盘io检测
1. FIO 简介
FIO 是一款 用于对磁盘进行性能测试的工具。可以测试IOPS,吞吐量,IO延迟等主要性能指标。而且支持多种IO引擎。
2. FIO 下载
下载地址:http://brick.kernel.dk/snaps/
打开以上网址,选择自己需要的版本并下载。比如:
wget http://brick.kernel.dk/snaps/fio-3.5.tar.gz
- 1.
3. 解压并安装
# tar -xzvf ./fio-3.5.tar.gz
.... 省略输出
# cd fio-3.5
# make && make install
.... 省略输出# which fio
/usr/local/bin/fio
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
4. 使用说明
filename=/dev/sdb1 测试文件名称,通常选择需要测试的盘的data目录。
direct=1 测试过程绕过机器自带的buffer。使测试结果更真实。
rw=randwrite 测试随机写的I/O
rw=randrw 测试随机写和读的I/O
bs=16k 单次io的块文件大小为16k
bsrange=512-2048 同上,指定数据块的大小范围
size=5g 本次的测试文件大小为5g,以每次4k的io进行测试。
numjobs=30 本次的测试线程为30.
runtime=1000 测试时间为1000秒,如果不写则一直将5g文件分4k每次写完为止。
ioengine=psync io引擎使用pync方式
rwmixwrite=30 在混合读写的模式下,写占30%
group_reporting 关于显示结果的,汇总每个进程的信息
lockmem=1g 只使用1g内存进行测试。
zero_buffers 用0初始化系统buffer。
nrfiles=8 每个进程生成文件的数量
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
5. 测试示例
混合测试:
fio -filename=/tmp/test -direct=1 -iodepth 1 -thread -rw=randrw -rwmixread=70 -ioengine=psync -bs=512b -size=200m -numjobs=10 -runtime=60 -group_reporting -name=mytest
顺序读:
fio -filename=/dev/test -direct=1 -iodepth 1 -thread -rw=read -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=60 -group_reporting -name=mytest
随机写:
fio -filename=/dev/test -direct=1 -iodepth 1 -thread -rw=randwrite -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=60 -group_reporting -name=mytest
顺序写:
fio -filename=/dev/test -direct=1 -iodepth 1 -thread -rw=write -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=60 -group_reporting -name=mytest
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
6. IO读写测试参考脚本
https://github.com/sunsharing-note/fio_test.git
- 1.
本文转载自微信公众号「运维开发故事」,可以通过以下二维码关注。转载本文请联系运维开发故事众号。