一、认识kafka
Kafka到底是个啥?用来干嘛的?
官方定义如下:
Kafka is used for building real-time data pipelines and streaming apps. It is horizontally scalable, fault-tolerant, wicked fast, and runs in production in thousands of companies.
翻译过来,大致的意思就是,这是一个实时数据处理系统,可以横向扩展,并高可靠!
实时数据处理,从名字上看,很好理解,就是将数据进行实时处理,在现在流行的微服务开发中,最常用实时数据处理平台有 RabbitMQ、RocketMQ 等消息中间件。
这些中间件,最大的特点主要有两个:
- 服务解耦
- 流量削峰
在早期的 web 应用程序开发中,当请求量突然上来了时候,我们会将要处理的数据推送到一个队列通道中,然后另起一个线程来不断轮训拉取队列中的数据,从而加快程序的运行效率。
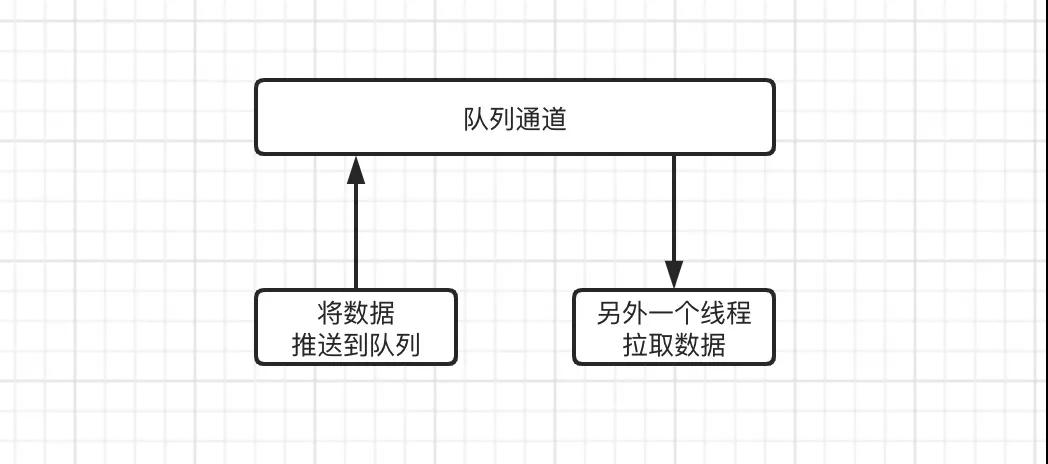
但是随着请求量不断的增大,并且队列通道的数据一致处于高负载,在这种情况下,应用程序的内存占用率会非常高,稍有不慎,会出现内存不足,造成程序内存溢出,从而导致服务不可用。
随着业务量的不断扩张,在一个应用程序内,使用这种模式已然无法满足需求,因此之后,就诞生了各种消息中间件,例如 ActiveMQ、RabbitMQ、RocketMQ等中间件。
采用这种模型,本质就是将要推送的数据,不在存放在当前应用程序的内存中,而是将数据存放到另一个专门负责数据处理的应用程序中,从而实现服务解耦。
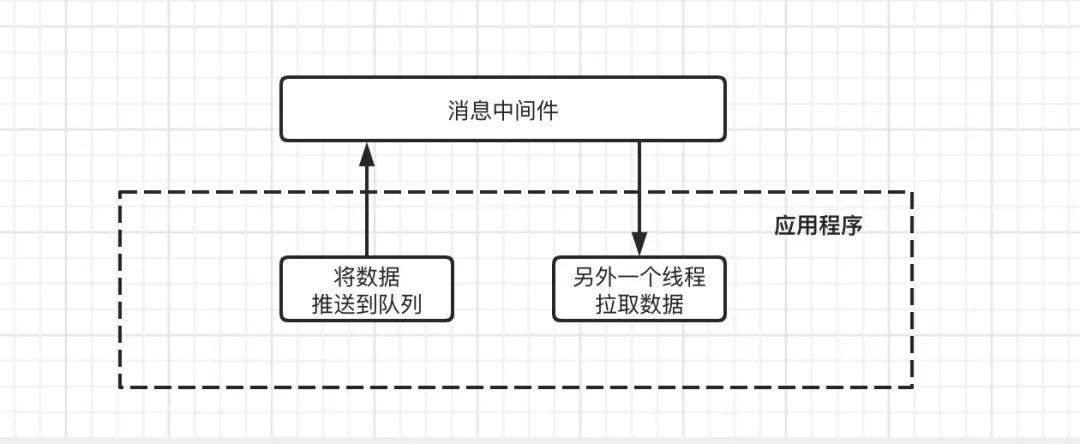
消息中间件:主要的职责就是保证能接受到消息,并将消息存储到磁盘,即使其他服务都挂了,数据也不会丢失,同时还可以对数据消费情况做好监控工作。
应用程序:只需要将消息推送到消息中间件,然后启用一个线程来不断从消息中间件中拉取数据,进行消费确认即可!
引入消息中间件之后,整个服务开发会变得更加简单,各负其责。
Kafka 本质其实也是消息中间件的一种,Kafka 出自于 LinkedIn 公司,与 2010 年开源到 github。
LinkedIn 的开发团队,为了解决数据管道问题,起初采用了 ActiveMQ 来进行数据交换,大约是在 2010 年前后,那时的 ActiveMQ 还远远无法满足 LinkedIn 对数据传递系统的要求,经常由于各种缺陷而导致消息阻塞或者服务无法正常访问,为了能够解决这个问题,LinkedIn 决定研发自己的消息传递系统,Kafka 由此诞生。
在 LinkedIn 公司,Kafka 可以有效地处理每天数十亿条消息的指标和用户活动跟踪,其强大的处理能力,已经被业界所认可,并成为大数据流水线的首选技术。
二、架构介绍
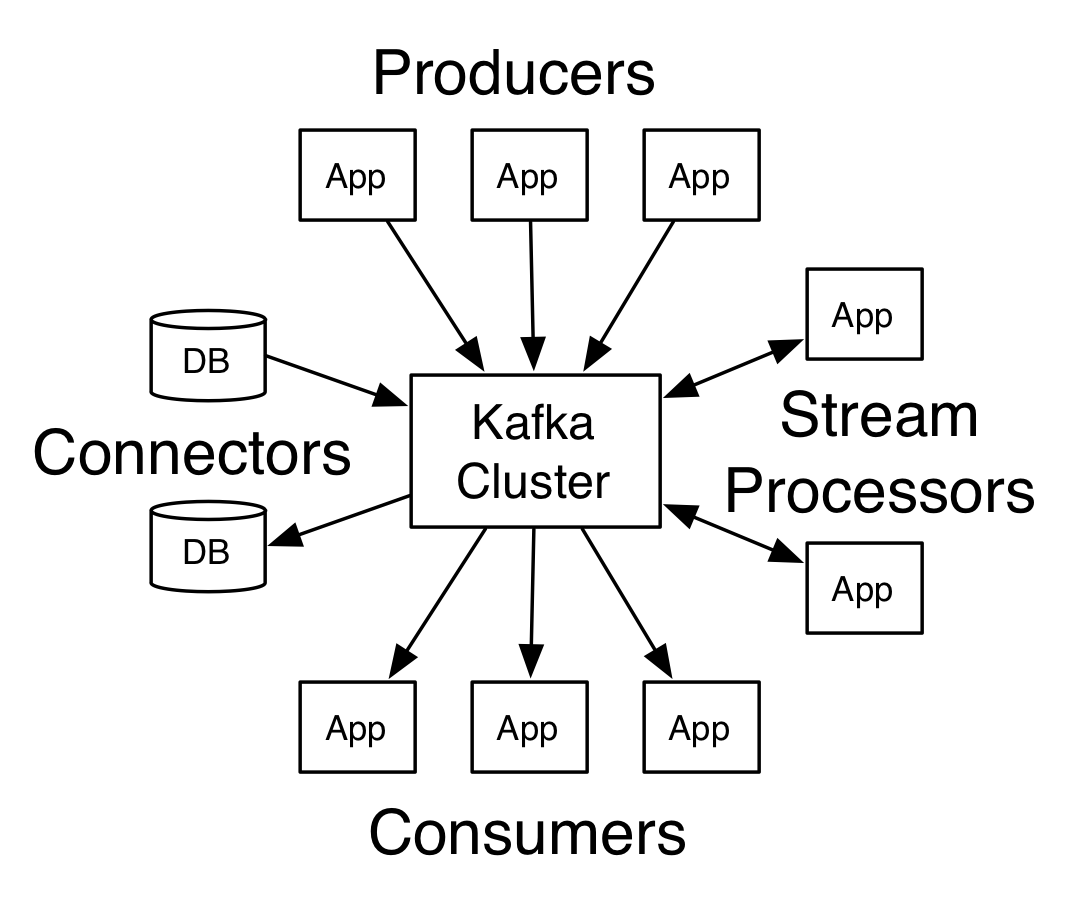
先来看一张图,下面这张图就是 kafka 生产与消费的核心架构模型!
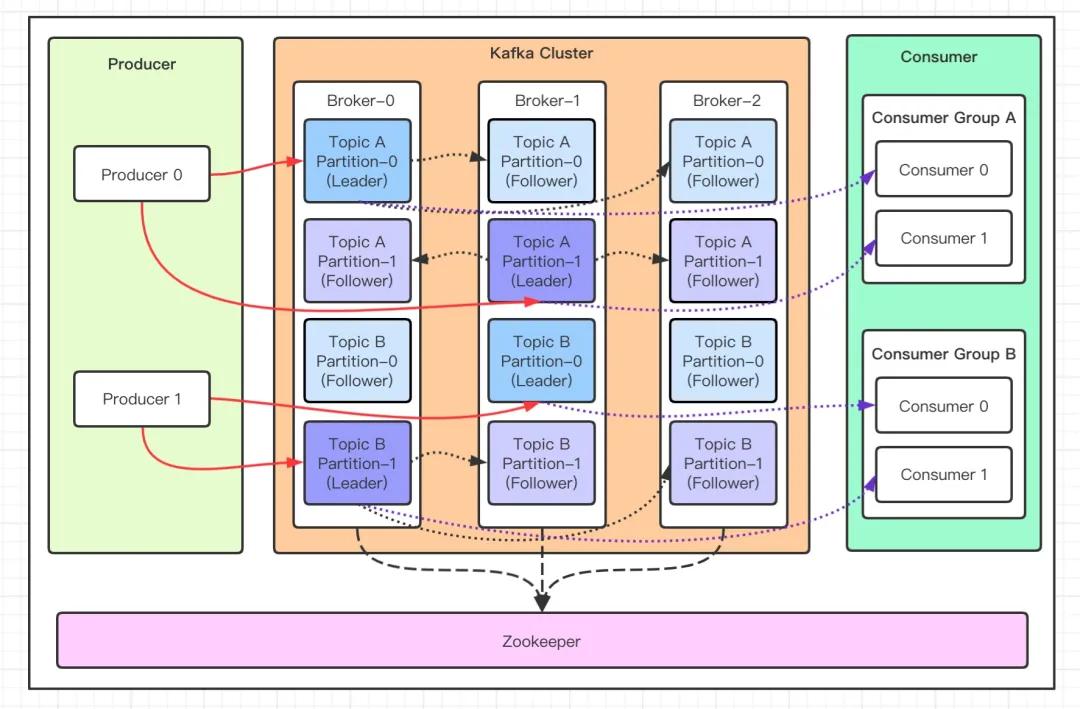
如果你看不懂这些概念没关系,我会带着大家一起梳理一遍!
- Producer:Producer 即生产者,消息的产生者,是消息的入口
- Broker:Broker 是 kafka 一个实例,每个服务器上有一个或多个 kafka 的实例,简单的理解就是一台 kafka 服务器,kafka cluster表示集群的意思
- Topic:消息的主题,可以理解为消息队列,kafka的数据就保存在topic。在每个 broker 上都可以创建多个 topic 。
- Partition:Topic的分区,每个 topic 可以有多个分区,分区的作用是做负载,提高 kafka 的吞吐量。同一个 topic 在不同的分区的数据是不重复的,partition 的表现形式就是一个一个的文件夹!
- Replication:每一个分区都有多个副本,副本的作用是做备胎,主分区(Leader)会将数据同步到从分区(Follower)。当主分区(Leader)故障的时候会选择一个备胎(Follower)上位,成为 Leader。在kafka中默认副本的最大数量是10个,且副本的数量不能大于Broker的数量,follower和leader绝对是在不同的机器,同一机器对同一个分区也只可能存放一个副本
- Message:每一条发送的消息主体。
- Consumer:消费者,即消息的消费方,是消息的出口。
- Consumer Group:我们可以将多个消费组组成一个消费者组,在 kafka 的设计中同一个分区的数据只能被消费者组中的某一个消费者消费。同一个消费者组的消费者可以消费同一个topic的不同分区的数据,这也是为了提高kafka的吞吐量!
- Zookeeper:kafka 集群依赖 zookeeper 来保存集群的的元信息,来保证系统的可用性。
简而言之,kafka 本质就是一个消息系统,与大多数的消息系统一样,主要的特点如下:
- 使用推拉模型将生产者和消费者分离
- 为消息传递系统中的消息数据提供持久性,以允许多个消费者
- 提供高可用集群服务,主从模式,同时支持横向水平扩展
与 ActiveMQ、RabbitMQ、RocketMQ 不同的地方在于,它有一个**分区Partition**的概念。
这个分区的意思就是说,如果你创建的topic有5个分区,当你一次性向 kafka 中推 1000 条数据时,这 1000 条数据默认会分配到 5 个分区中,其中每个分区存储 200 条数据。
这样做的目的,就是方便消费者从不同的分区拉取数据,假如你启动 5 个线程同时拉取数据,每个线程拉取一个分区,消费速度会非常非常快!
这是 kafka 与其他的消息系统最大的不同!
2.1、发送数据
和其他的中间件一样,kafka 每次发送数据都是向Leader分区发送数据,并顺序写入到磁盘,然后Leader分区会将数据同步到各个从分区Follower,即使主分区挂了,也不会影响服务的正常运行。
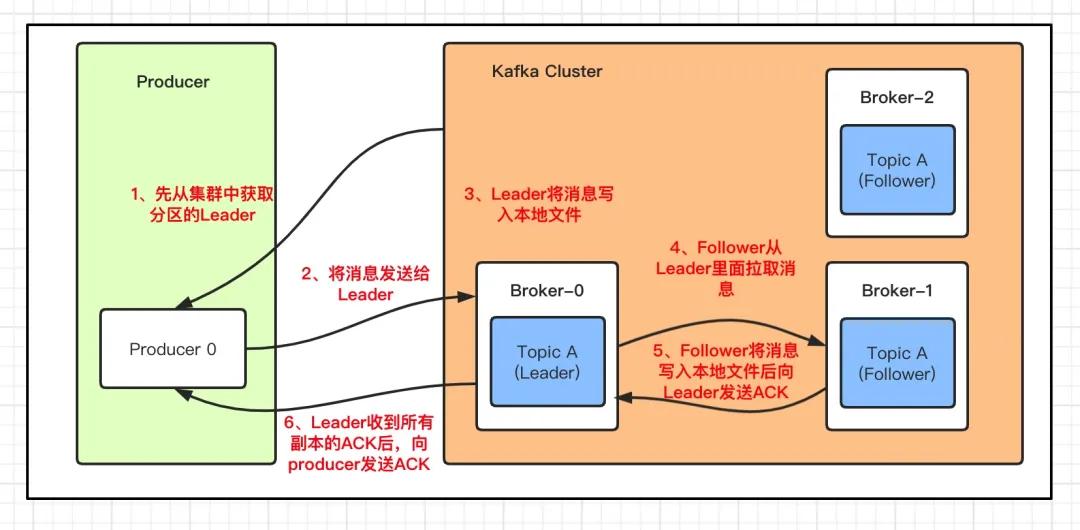
那 kafka 是如何将数据写入到对应的分区呢?kafka中有以下几个原则:
1、数据在写入的时候可以指定需要写入的分区,如果有指定,则写入对应的分区
2、如果没有指定分区,但是设置了数据的key,则会根据key的值hash出一个分区
3、如果既没指定分区,又没有设置key,则会轮询选出一个分区
2.2、消费数据
与生产者一样,消费者主动的去kafka集群拉取消息时,也是从Leader分区去拉取数据。
这里我们需要重点了解一个名词:消费组!
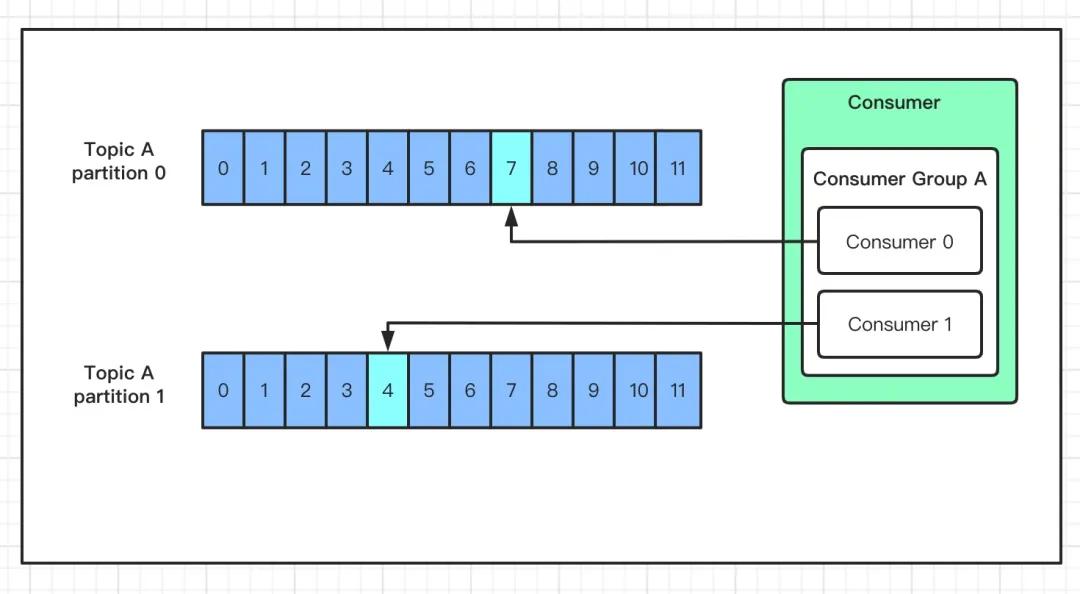
考虑到多个消费者的场景,kafka 在设计的时候,可以由多个消费者组成一个消费组,同一个消费组者的消费者可以消费同一个 topic 下不同分区的数据,同一个分区只会被一个消费组内的某个消费者所消费,防止出现重复消费的问题!
但是不同的组,可以消费同一个分区的数据!
你可以这样理解,一个消费组就是一个客户端,一个客户端可以由很多个消费者组成,以便加快消息的消费能力。
但是,如果一个组下的消费者数量大于分区数量,就会出现很多的消费者闲置。
如果分区数量大于一个组下的消费者数量,会出现一个消费者负责多个分区的消费,会出现消费性能不均衡的情况。
因此,在实际的应用中,建议消费者组的consumer的数量与partition的数量保持一致!
三、kafka 安装
光说理论可没用,下面我们就以 centos7 为例,介绍一下 kafka 的安装和使用。
kafka 需要 zookeeper 来保存服务实例的元信息,因此在安装 kafka 之前,我们需要先安装 zookeeper。
3.1、安装zookeeper
zookeeper 安装环境依赖于 jdk,因此我们需要事先安装 jdk
- # 安装jdk1.8
- yum -y install java-1.8.0-openjdk
下载zookeeper,并解压文件包
- #在线下载zookeeper
- wget http://mirrors.hust.edu.cn/apache/zookeeper/zookeeper-3.4.12/zookeeper-3.4.12.tar.gz
- #解压
- tar -zxvf zookeeper-3.4.12.tar.gz
创建数据、日志目录
- #创建数据和日志存放目录
- cd /usr/zookeeper/
- mkdir data
- mkdir log
- #把conf下的zoo_sample.cfg备份一份,然后重命名为zoo.cfg
- cd conf/
- cp zoo_sample.cfg zoo.cfg
配置zookeeper
- #编辑zoo.cfg文件
- vim zoo.cfg
重新配置dataDir和dataLogDir的存储路径
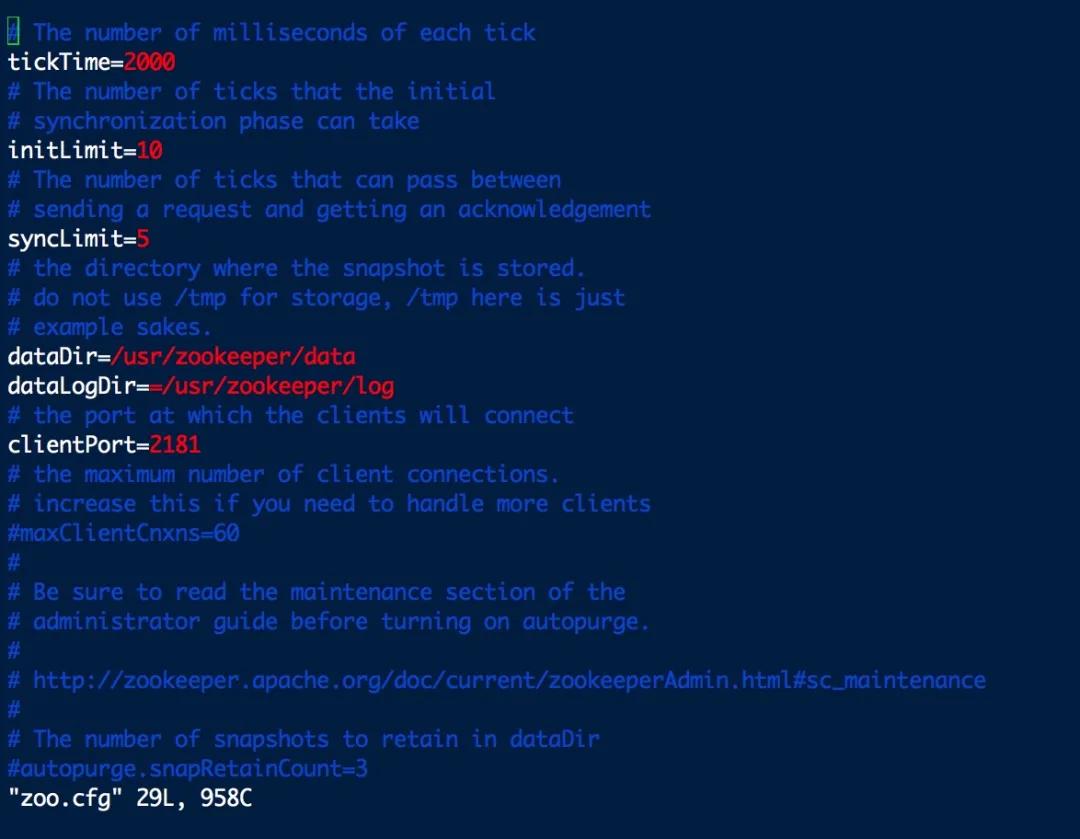
最后,启动 Zookeeper 服务
- #进入Zookeeper的bin目录
- cd zookeeper/zookeeper-3.4.12/bin
- #启动Zookeeper
- ./zkServer.sh start
- #查询Zookeeper状态
- ./zkServer.sh status
- #关闭Zookeeper状态
- ./zkServer.sh stop
3.2、安装kafka
到官网http://kafka.apache.org/downloads.html下载想要的版本,我这里下载是最新稳定版2.8.0。
- #下载kafka 安装包
- wget https://apache.osuosl.org/kafka/2.8.0/kafka-2.8.0-src.tgz
- #解压文件包
- tar -xvf kafka-2.8.0-src.tgz
按需修改配置文件server.properties(可选)
- #进入配置文件夹
- cd kafka-2.8.0-src/config
- #编辑server.properties
- vim server.properties
server.properties文件内容如下:
- broker.id=0
- listeners=PLAINTEXT://localhost:9092
- num.network.threads=3
- num.io.threads=8
- socket.send.buffer.bytes=102400
- socket.receive.buffer.bytes=102400
- socket.request.max.bytes=104857600
- log.dirs=/tmp/kafka-logs
- num.partitions=1
- num.recovery.threads.per.data.dir=1
- offsets.topic.replication.factor=1
- transaction.state.log.replication.factor=1
- transaction.state.log.min.isr=1
- log.retention.hours=168
- log.segment.bytes=1073741824
- log.retention.check.interval.ms=300000
- zookeeper.connect=localhost:2181
- zookeeper.connection.timeout.ms=6000
- group.initial.rebalance.delay.ms=0
其中有四个重要的参数:
- broker.id:唯一标识ID
- listeners=PLAINTEXT://localhost:9092:kafka服务监听地址和端口
- log.dirs:日志存储目录
- zookeeper.connect:指定zookeeper服务地址
可根据自己需求修改对应的配置!
3.3、启动 kafka 服务
- # 进入bin脚本目录
- cd kafka-2.8.0-src/bin
启动 kafka 服务
- nohup kafka-server-start.sh ../config/server.properties server.log 2> server.err &
3.4、创建主题topics
创建一个名为testTopic的主题,它只包含一个分区,只有一个副本:
- # 进入bin脚本目录
- cd kafka-2.8.0-src/bin
- #创建topics
- kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testTopic
运行list topic命令,可以看到该主题。
- # 进入bin脚本目录
- cd kafka-2.8.0-src/bin
- #查询当前kafka上所有的主题
- kafka-topics.sh --list --zookeeper localhost:2181
输出内容:
- testTopic
3.5、发送消息
Kafka 附带一个命令行客户端,它将从文件或标准输入中获取输入,并将其作为消息发送到 Kafka 集群。默认情况下,每行将作为单独的消息发送。
运行生产者,然后在控制台中键入一些消息以发送到服务器。
- # 进入bin脚本目录
- cd kafka-2.8.0-src/bin
- #运行一个生产者,向testTopic主题中发消息
- kafka-console-producer.sh --broker-list localhost:9092 --topic testTopic
输入两条内容并回车:
- Hello kafka!
- This is a message
3.5、接受消息
Kafka 还有一个命令行使用者,它会将消息转储到标准输出。
- # 进入bin脚本目录
- cd kafka-2.8.0-src/bin
- #运行一个消费者,从testTopic主题中拉取消息
- kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testTopic --from-beginning
输出结果如下:
- Hello kafka!
- This is a message
四、小结
本文主要围绕 kafka 的架构模型和安装环境做了一些初步的介绍,难免会有理解不对的地方,欢迎网友批评、吐槽。
由于篇幅原因,会在下期文章中详细介绍 java 环境下 kafka 应用场景!