Labs 导读
所谓计算虚拟化,从狭义角度可理解为对单个物理服务器的虚拟化,主要包括对服务器上的CPU、内存、I/O设备进行虚拟化,目的就是实现多个虚拟机能各自独立、相互隔离地运行于一个服务器之上。从广义角度还可延伸到云资源池下,各类资源池组网场景下的CPU、内存、I/O设备等资源进行整合、抽象和虚拟化。
1、服务器虚拟化平台概念回顾
在上一篇文章《虚拟化基础》中,我们介绍虚拟化基础的一些基本概念,这里我们按照服务器平台虚拟化后的一个分层结构来简单回顾下。如下:

一个完整的服务器虚拟化平台从下到上包括以下几个部分:
- 底层物理资源:包括网卡、CPU、内存、存储设备等硬件资源,一般将包含物理资源的物理机称为宿主机(Host)。
- 虚拟机监控器(Virtual Machine Monitor,VMM):VMM是位于虚拟机与底层硬件设备之间的虚拟层,直接运行于硬件设备之上,负责对硬件资源进行抽象,为上层虚拟机提供运行环境所需资源,并使每个虚拟机都能够互不干扰、相互独立地运行于同一个系统中。
- 抽象化的虚拟机硬件:即虚拟层呈现的虚拟化的硬件设备。虚拟机能够发现哪种硬件设施,完全由VMM决定。虚拟设备可以是模拟的真实设备,也可以是现实中并不存在的虚拟设备,如VMware的vmxnet网卡。
- 虚拟机:相对于底层提物理机,也称为客户机(Guest)。运行在其上的操作系统则称为客户机操作系统(Guest OS)。每个虚拟机操作系统都拥有自己的虚拟硬件,并在一个独立的虚拟环境中执行。通过VMM的隔离机制,每个虚拟机都认为自己作为一个独立的系统在运行。
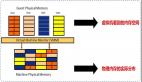
同时,在上一篇文章《虚拟化基础》中,我们提到过Hypervisor就是VMM。其实,这个说法并不准确,至少在VMware的虚拟化解决方案中不准确,在VMware的ESX产品架构中,VMM和Hypervisor还是有一定区别的,如下图所示。
Hypervisor是位于虚拟机和底层物理硬件之间的虚拟层,包括boot loader、x86 平台硬件的抽象层,以及内存与CPU调度器,负责对运行在其上的多个虚拟机进行资源调度。而VMM则是与上层的虚机一一对应的进程,负责对指令集、内存、中断与基本的I/O设备进行虚拟化。当运行一个虚拟机时,Hypervisor中的vmkernel会装载VMM,虚拟机直接运行于VMM之上,并通过VMM的接口与Hypervisor进行通信。而在KVM和Xen架构中,虚拟层都称为Hypervisor,也就是VMM=Hypervisor。
判断一个VMM能否有效确保服务器系统实现虚拟化功能,必须具备以下三个基本特征:
- 等价性(Equivalence Property):一个运行于VMM控制之下的程序(虚拟机),除了时序和资源可用性可能不一致外,其行为应该与相同条件下运行在物理服务器上的行为一致。
- 资源可控性(Resource Control Property):VMM必须能够完全控制虚拟化的资源。
- 效率性(Efficiency Property):除了特权指令,绝大部分机器指令都可以直接由硬件执行,而无需VMM干涉控制。
上述三个基本特征也是服务器虚拟化实现方案的指导思想。
2、x86平台虚拟化面临的问题与挑战
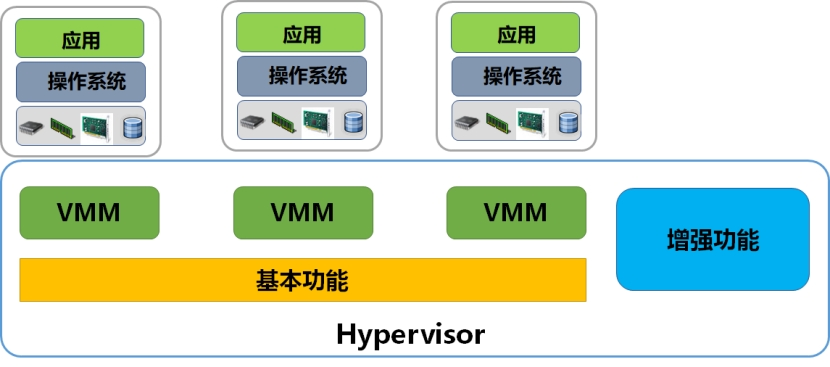
基于x86的操作系统在一开始就被设计为能够直接运行在裸机硬件环境之上,所以自然拥有整个机器硬件的控制权限。为确保操作系统能够安全地操作底层硬件,x86平台使用了特权模式和用户模式的概念对内核程序与用户应用程序进行隔离。在这个模型下,CPU提供了4个特权级别,分别是Ring0、1、2和3。如下图所示:

Ring 0是最高特权级别,拥有对内存和硬件的直接访问控制权。Ring 1、2和3权限依次降低, 无法执行操作讷河系统级别的指令集合。相应的,运行于Ring 0的指令称为“特权指令”;运行于其他级别的称为“非特权指令”。常见的操作系统如Linux与Windows都运行于Ring 0,而用户级应用程序运行于Ring 3。如果低特权级别的程序执行了特权指令,会引起“ 陷入”(Trap)内核态,并抛出一个异常。
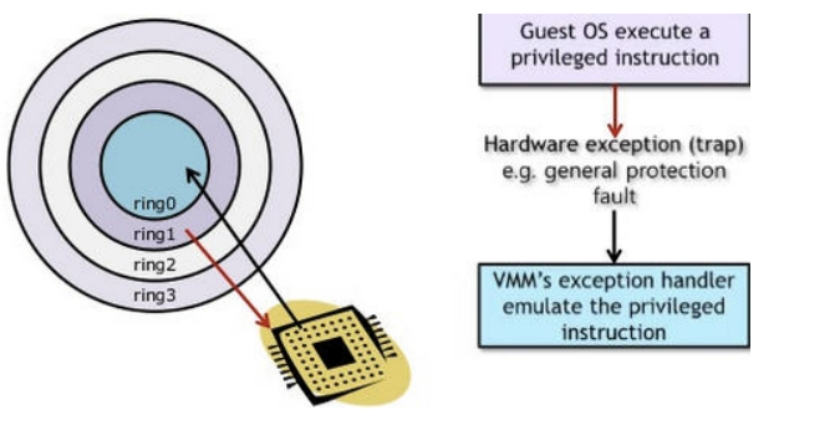
当这种分层隔离机制应用于虚拟化平台,为了满足VMM的“资源可控” 特征,VMM必须处于Ring 0级别控制所有的硬件资源,并且执行最高特权系统调用。而虚拟机操作系统Guest OS则要被降级运行在Ring 1级别,故Guest OS在执行特权指令时都会引起”陷入“。如果VMM能够正常捕获异常,模拟Guest OS发出的指令并执行,就达到了目的。这就是IBM的Power系列所采用的特权解除和陷入模拟的机制,支持这种特性的指令集合通常被认为是“可虚拟化的”。
但是...但是...但是...x86平台的指令集是不虚拟化的。为什么这么说?首先我们来看下x86平台指令集分类,x86平台的指令集大致分为以下4类:
- 访问或修改机器状态的指令。
- 访问或修改敏感寄存器或存储单元的指令, 比如访问时钟寄存器和中断寄存器。
- 访问存储保护系统或内存、地址分配系统的指令(段页之类)。
- 所有I/O指令。
其中,1~4在x86平台都属于敏感指令,第1、4类指令属于敏感指令中的特权指令,由操作系统内核执行,Guest OS在执行两类指令时,因为不处于Ring 0级别,所以会陷入,并抛出异常,这个异常会被VMM捕获,然后模拟Gust OS去执行,并将执行结果返回给Guest OS。到此为止,一切都OK。但是,第2、3类指令属于非特权指令,可以由应用程序调用,也就是可以在Ring 3级别执行,并调用Guest OS内核进程来完成。当应用程序调用这些指令时,由于要修改内存和内部寄存器,这些状态修改需要由Guest OS完成,而Guse OS此时运行在Ring 1级别,虽然也会发生陷入,但是不会抛出异常,这样VMM就捕获不到,也就无法模拟完成。因此,当Guest OS执行这些指令就会导致虚拟机状态异常,甚至影响服务器的状态。在x86平台下,这类指令共有19个,我自己称之为x86平台敏感指令中的边界指令。
就是因为x86平台指令集有上述缺陷,所以为了计算虚拟化技术在x86平台应用,各大虚拟化厂商推出了五花八门的虚拟化技术,其目的都是围绕“如何捕获模拟这19条边界指令”这一命题来设计。在很长一段时间,都是通过软件的方式来解决这个问题,其中包括无需修改内核的全虚拟化与需要修改内核的半虚拟化。尽管半虚拟化要求修改Guest OS内核的方式在一定程度上并不满足“ 等价性”要求,但是在性能上却明显优于全虚拟化。直到2005年Intel与AMD公司分别推出了VT-d与AMD-V,能够在芯片级别支持全虚拟化时,虚拟化技术才得到彻底完善,这就是现在称之为的硬件辅助虚拟化技术。
3、x86平台计算虚拟化解决方案
3.1 全虚拟化
全虚拟化(Full Virtualization)与半虚拟化(Para- Virtualization)的划分,是相对于是否修改Guest OS而言的。如下图所示,全虚拟化通过一层能够完整模拟物理硬件环境的虚拟软件,使得Guest OS与底层物理硬件彻底解耦。因此,Guest OS无需任何修改,虚拟化的环境对其完全透明,也就是说在全虚方案中,虚拟机感知不到自己处于虚拟化环境中,认为自己一直运行在物理硬件上。如下图所示:
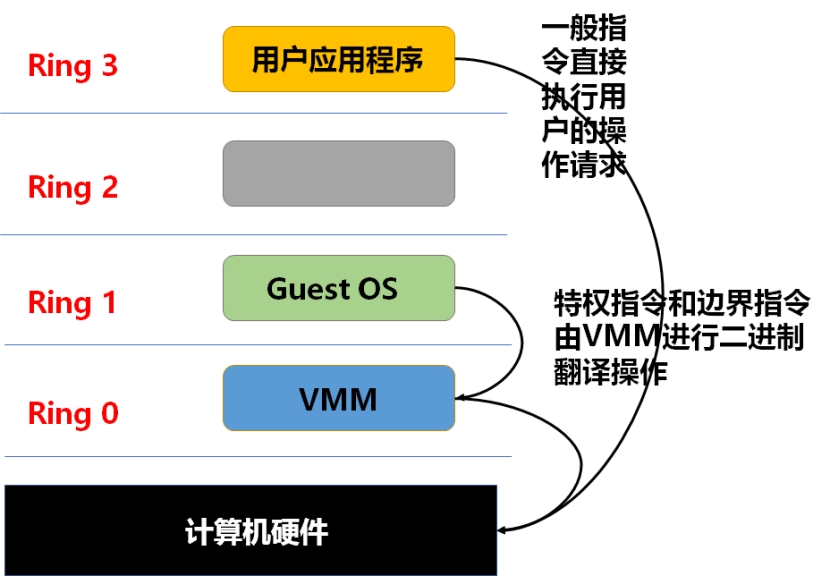
在实现上,通常是结合特权指令的二进制翻译机制与一般指令的直接执行的方式。具体来说, 对于Guest OS发出的特权指令和边界指令,VMM会进行实时翻译,并缓存结果(目的是提高虚拟化性能),而对于一般级别的指令,则无需VMM干涉,可以直接在硬件上执行。异常-捕获-模拟的过程如下图所示:
由于虚拟化环境对Guest OS是完全透明的,全虚拟化模式对于虚拟机的迁移以及可移植性是最佳解决方案,虚拟机可以无缝地从虚拟环境迁移到物理环境中。但是,软件模拟实现的全虚拟化无疑会增加VMM的上下文切换,因为这种方案实现的虚拟机性能不如半虚拟化方案。VMware的ESX系列产品 和Workstations系列产品是全虚拟化技术的典型产品。
3.2 半虚拟化如前所述,x86平台上一直存在一些Ring 3级别可以执行的边界指令,尽管全虚拟化模式通过实时译这些特殊指令解决了这一问题,但是实现开销较大,性能并不如在实际物理机上运行。为了改善性能,半虚拟化技术应运而生, “Para-Virtualization” 可理解为通过某种辅助的方式实现虚拟化。半虚拟化的解决方案如下图所示。
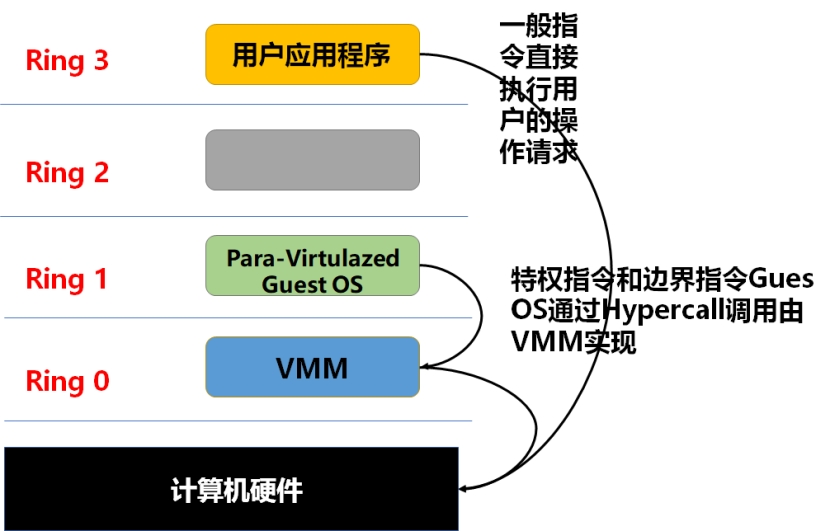
半虚拟化在Guest OS和虚拟层之间增加了一个特殊指令的过渡模块,通过修改Guest OS内核,将执行特权指令和边界指令替换为对虚拟层进行hypercall的调用方式来达到目的。同时,虚拟层也对内存管理、中断处理、时间同步提供了hypercall的调用接口。Hypercall调用过程如下图所示:
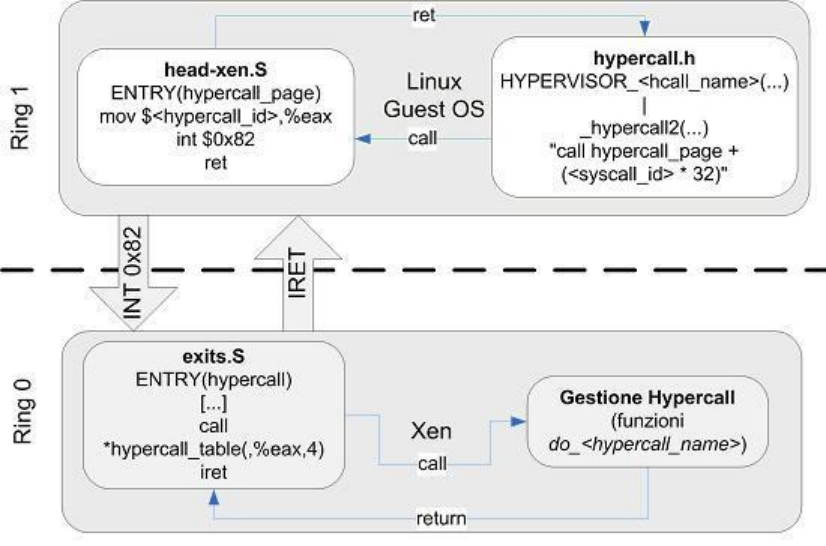
通过这种方式,虚拟机运行的性能得以显著提升。但是,对于某些无法修改内核的操作系统,比如:Windows,则不能使其运行于半虚拟化环境中。而且,由于需要修改Guest OS内核,无法保证虚拟机在物理环境与虚拟环境之间的透明切换。开源项目Xen和华为6.3版本之前的虚拟化解决方案Fusion Compute就是通过修改Linux内核以及提供I/O虚拟化操作的Domain 0的特殊虚拟机,使得运行于虚拟化环境上的虚拟机性能可以接近运行于物理环境的性能,属于半虚拟化技术方案的典型产品。但是,随着业务规模的增大,特殊虚机Domain 0是这种解决方案扩展性和性能方面的瓶颈。
3.3 硬件辅助虚拟化所谓“解铃还须系铃人”,针对敏感指令引发的一系列虚拟化问题,处理器硬件厂商最终给出了自己的解决方案。2005年Intel与AMD公司都效法IBM大型机虚拟化技术分别推出VT-x和AMD-V技术。如下图所示:
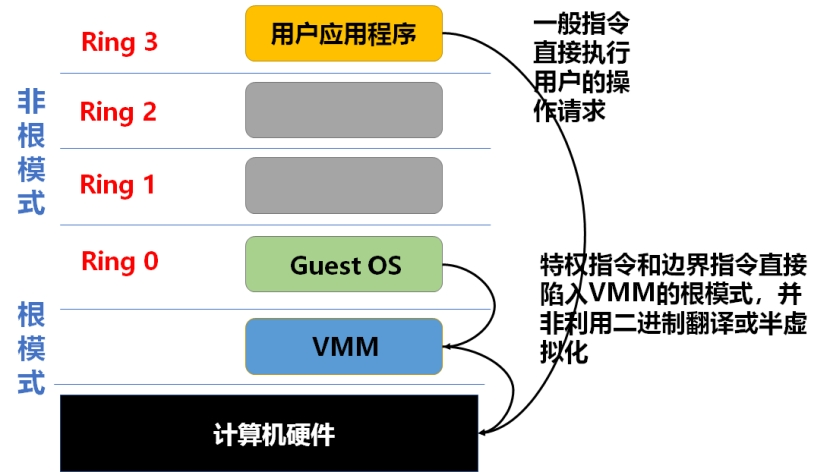
第一代VT-x与AMD-V都试图通过定义新的运行模式,使Guest OS恢复到Ring 0,而让VMM运行在比Ring 0低的级别(可以理解为Ring -1)。比如:Intel公司的VT-x解决方案中,运行于非根模式下的Guest OS可以像在非虚拟化平台下一样运行于Ring 0级别,无论是Ring 0发出的特权指令还是Ring 3发出的敏感指令都会被陷入到根模式的虚拟层。VT-x解决方案具体如下图所示:
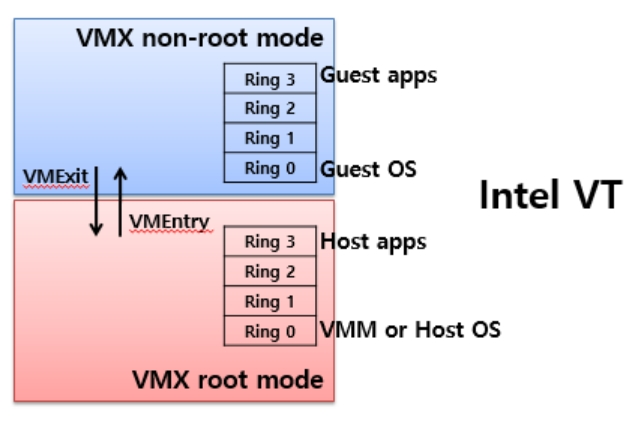
VT-x与AMD-V推出之后,完美解决解决x86平台虚拟化的缺陷,且提升了性能,所以各个虚拟化厂商均快速开发出对应的产品版本,用于支持这种技术。比如:KVM-x86、Xen 3.0与VMware ESX 3.0之后的虚拟化产品。随后Intel和AMD在第二代硬件辅助虚拟化技术中均推出了针对I/O的硬件辅助虚拟化技术VT-d和IOMMU。
总结:x86平台下的三种虚拟化技术,都是围绕x86在虚拟化上的一些缺陷产生的。下图对三种虚拟化技术进行了比较。

从图中可以看出,全虚拟化与半虚拟化的Guest OS的特权级别都被压缩在Ring 1中,而硬件虚拟化则将Guest OS恢复到了Ring 0级别。在半虚拟化中,Guest OS的内核经过修改,所有敏感指令和特权指令都以Hypercall的方式进行调用,而在全虚拟化与硬件虚拟化中,则无需对Guest OS进行修改。全虚拟化中对于特权指令和敏感指令采用了动态二进制翻译的方式,而硬件虚拟化由于在芯片中增加了根模式的支持,并修改了敏感指令的语义,所有特权指令与敏感指令都能够自动陷入到根模式的VMM中。

【本文为51CTO专栏作者“移动Labs”原创稿件,转载请联系原作者】