【51CTO.com快译】在人工智能(AI)研究领域,除了使用TensorFlow和PyTorch等流行平台,目前还有许多出色的、略显小众的开源工具与资源。在本文中,我们将和您讨论七种可用于各种前沿研究的开源AI库。它们所涉及到的领域包括量子机器学习(ML)、加密计算等方面。由于它们提供了开源的许可证,因此您可以对其内容进行增加,分叉,或修改,以满足实际的项目需求。
DiffEqFlux.jl:用Julia语言实现神经微分方程
- MIT许可证
- GitHub星数:481
- 存储库地址:https://github.com/SciML/DiffEqFlux.jl/
专为科学计算而设计的Julia编程语言,是一种相对年轻的编程语言(目前只有“9岁”,而Python已有“30岁”了)。Julia旨在弥合Python等高级生产力语言与C++等高速语言之间的差距。它更接近于在硬件中执行各种机器类操作。Julia语言可以将即时编译与动态编程的范式相结合。虽然这会让首次执行需要长时间的编译,但随着时间的推移,它会以接近C语言的速度,去运行各种算法。
虽然该语言是专为科学计算与研究而设计的,但是它往往被人们用于机器学习和人工智能领域。借助Flux.jl(下文将会介绍到)等可用于微编程的软件包,Julia语言正在通过打造其社区和生态系统,以实现快速的迭代、推理和训练。
作为围绕着Julia语言开发的一种软件包,DiffEqFlux.jl通过与DifferentialEquations.jl和Flux.jl工具包相结合,以促进神经微分方程的构建。
当然,除了神经微分方程,DiffEqFlux.jl还支持随机微分方程、以及通用偏微分方程等。同时,它还通过支持GPU,以满足前沿生产系统的性能需求。您可以通过链接--https://julialang.org/blog/2019/01/fluxdiffeq/,了解更多有关DiffEqFlux.jl的信息。
PennyLane:一个同时适合机器学习和量子计算的库
- Apache 2.0
- GitHub星数:817
- 存储库地址:https://github.com/PennyLaneAI/pennylane
PennyLane利用自动化微分技术,在深度学习和量子电路模拟方面取得了巨大成功。最初,PennyLane基于Autograd库实现了大部分自动化微分的功能。之后,它又添加了其他的后端库。目前,PennyLane能够支持使用PyTorch和TensorFlow后端,以及不同的量子模拟器和设备。作为一个通用库,它主要用于构建那些可以通过反向传播,进行训练和更新的量子与混合电路。
PennyLane团队对其采用了一流的编码和单元测试风格。由于是开源的(持有Apache 2.0许可证),因此它在GitHub上拥有大量的贡献者,并能紧跟量子机器学习领域。
Flux.jl:一种自动化微分的新方法
- MIT“Expat”许可证
- GitHub星级:2.9k
- 存储库地址:https://github.com/FluxML/Flux.jl
Flux.jl是一个功能强大的软件库,可被用于自动化微分类机器学习和一般性微分编程。它既支持Julia编程语言,又持有开源的MIT许可证。
通常,PyTorch的fast.ai和TensorFlow的Keras都采用的是较高级别的应用程序库接口,而Flux.jl采用支持各种数学与科学计算的编码与方程模式,来实现机器学习。
Flux.jl可被用在许多涉及到Julia语言的机器学习项目里,其中就包含了前文讨论过的DiffEqFlux.jl。不过,对于那些希望从Python中获得与Autograd或JAX最相似体验的初学者来说,Zygote.jl(一个基于Flux的高级自动化微分库)才是最好的起点。
Tensorflow Probability:正确并不意味着确定
- Apache 2.0
- GitHub星级:3.3k
- 存储库地址:https://github.com/tensorflow/probability
TensorFlow Probability提供了可用于推理不确定性、概率和统计分析的工具。这些功能都有助于我们建立针对模型预测的信心,以避免分布外(out-of-distribution)输入数据对于推理输出的影响。这正是传统深度学习模型所无法做到的。
下面我将通过TensorFlow Probability文档中的一个示例,和您讨论在未考虑到不确定性或随机过程时,可能导致的错误。该示例是一个关于回归问题的简单案例。我们将定义和讨论不确定性的两大类:任意性(aleatoric)和认知性(epistemic)。
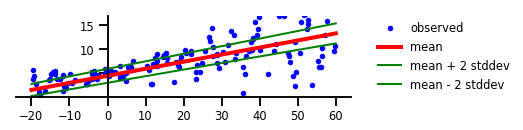
首先,让我们来看如何使用简单的线性回归模型,来拟合数据。此处并未用到任何一种不确定性。
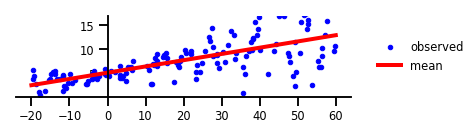
毫无疑问,我们得到了一条线段,它是遵循所有观察所得出的中心趋势线。虽然该线段能够告诉我们一些关于数据的信息,但是它只是其中的一部分。如果真实情况变化过快,那么模型输出和观察之间的差异会存在偏离,该线段也就无法很好地解释真实数据了。接下来,让我们看看模型在应用认知的不确定性情况下,会发生什么改变。
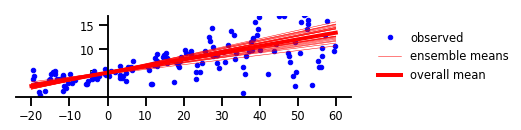
其实,认知的不确定性往往来自缺乏经验。也就是说,认知不确定性会随着对给定类型训练样本量的增加而减少。毕竟,在机器学习的模型中,基于稀有样本类型和边缘情况的预测,可能会导致危险的错误结果。
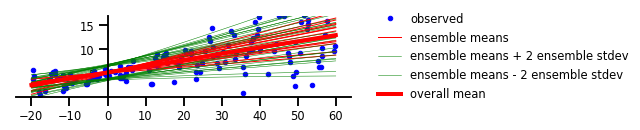
此处任意不确定性代表了事件或预测的内在随机性,就像掷骰子一样。如果我们将其应用到该示例的回归问题中,就会得到如下图所示的线段。
其中的任意不确定性是由统计误差的范围所表示的。我们可以看到,尽管认知不确定性似乎捕获了数据与y轴交叉的枢轴点,但是任意不确定性产生了一个缓慢变化的误差范围。该误差范围会在数据分布上逐渐扩大,并在右侧呈现出松散的沙粒点。
那么,如果将任意和认知的不确定性方法,同时应用到该回归问题的示例中呢?我们将可以对高度不确定性区域,通过预测来检验直觉的观察。该模型估计可以同时捕获枢轴区域和数据中的潜在随机性。不过,TensorFlow Probability在基于具有径向基函数核的变分高斯过程层,展示了“功能上的不确定性”。
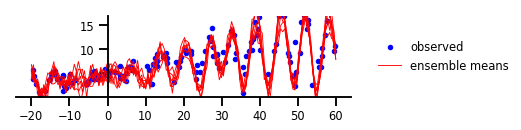
如上图所示,该自定义的不确定性模型,捕获了数据中从未被发现到的周期性。如果您对此方面感兴趣的话,请参见2019年TensorFlow开发者峰会上,有关TensorFlow Probability的公开演示--https://www.youtube.com/watch?v=BrwKURU-wpk。
TensorFlow Probability所提供的工具,可被用于为机器学习模型注入对于已知未知性参数(任意不确定性)、和未知未知性参数(认知性)的洞见,以及针对概率和统计推理的应用。随着AI和ML模型在日常生活中的广泛应用,我们更需要通过此类软件库,来构建一个“知道什么时候不知道”的模型。
PySyft:深挖背后的数据
- Apache 2.0
- GitHub星级:7k
- 存储库地址:https://github.com/OpenMined/PySyft
如今,人们在日常生活中所产生的敏感数据,包括健康记录、约会偏好、以及财务记录等。人们通常希望仅出于非常特定的目的,并且仅由非常特定的人员或算法,来访问这些数据,同时仅将它们用于预期的目的。例如,人们可能会让他们的医生能够访问其医疗扫描记录,但不允许当地药房(或者更糟的是快餐配送应用)作为广告营销的来源。而当人们谈论AI安全时,他们往往会将此类风险归咎于公司、政府、或其他机构缺乏隐私保护的技术应用和政策。
PySyft是一个针对尊重隐私的机器学习,而构建的软件库。通过相关工具,PySyft能够协助用户在机器学习和计算中,合理地处理那些他们“并不拥有、且无法看到的数据”,进而实现了一种罕见的、尊重隐私的机器学习方式。
AutoKeras:教机器去自行调整超级参数
- Apache 2.0
- GitHub星级:7.9k
- 存储库地址:https://github.com/keras-team/autokeras
随着深度学习已经成为人工智能的重要方法,将深度神经网络组合在一起,来解决诸如:图像分割、分类或预测偏好与行为等典型问题,已变得越来越容易。通过Keras和PyTorch的fast.ai等高级库,我们可以将多个层次连接在一起,并轻松地将它们拟合成有价值的数据集。使用Keras,就像使用model.fit的API一样简单。由于AutoKeras添加了一个额外的简单自动化层,因此它在运行时,您甚至无需指定模型的架构。
如今,我们既不需要通过定制CUDA代码和自定义的梯度检查,才能构建深度神经网络,也不必再使用TensorFlow 1.x版繁杂的图形会话编程模式。我们只需仔细调整超级参数,便可通过自动化的方式,实现数据集的最佳模型。尽管简单的网格搜索并非设置超级参数的最佳方法(甚至用随机搜索通常会更好),但它确实很常见。
作为一个自动化的机器学习库,AutoKeras将Keras的简便实用程序与自动化的超级参数,甚至是架构调整的便利性相结合。其中最为实用的是AutoKerasAutoModel类,它可以被用于仅通过其输入和输出,来定义“超级模型”。与普通Keras的训练模型类的方式类似,我们可以通过调用fit()方法,来训练AutoKerasAutoModel。它不仅会自动调整超级参数,而且还能开发出已优化的内部架构。总之,像AutoKeras之类的自动化机器学习(AutoML)工具,能够大幅节省开发人员的宝贵时间。
JAX,一个新型快速的自动化微分库
- Apache 2.0
- GitHub星数:12.3k
- 存储库地址:https://github.com/google/jax
作为世界顶级AI研究机构之一,Google DeepMind不仅将JAX作为功能性自动化微分工具纳入其工作流程,而且他们一直在开发着一套完整的、以JAX为中心的生态系统。该生态系统包括了:用于深度强化学习的RLax、用于在函数式和面向对象编程范式之间组合与转换的Haiku、用于图形深度学习的Jraph、以及许多其他基于JAX的工具,所有这些都持有开源且友好的Apache 2.0许可证。
值得一提的是,对于那些有兴趣利用JAX的实时编译、硬件加速(包括对最新GPU的支持)、以及纯JAX的功能,进行AI研究的人员来说,DeepMind JAX生态系统是一个不错的起点。
小结
在许多时候,AI研究人员可能只会关注鲜少的常用专业工具。尽管他们往往无需从头开始每个项目,但是确切地知道哪个开源库适合哪一类项目,还是非常有必要的。通过上述讨论,我们为您列出了用于AI研究的七种优秀的开源库,它们涵括从自动化机器学习到微分量子电路。希望上述列表能够为您提供丰富的功能、以及足够的开发选择。
原文标题:The 7 Best Open Source AI Libraries You May Not Have Heard Of,作者:Kevin Vu
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】