本文转载自微信公众号「记录技术记录我」,作者ziwen。转载本文请联系记录技术记录我公众号。
在 Spark 中,内存计算有两层含义:
- 第一层含义就是众所周知的分布式数据缓存;
- 第二层含义是 Stage 内的流水线式计算模式,通过计算的融合来大幅提升数据在内存中的转换效率,进而从整体上提升应用的执行性能;
那 Stage 内的流水线式计算模式到底长啥样呢?在 Spark 中,流水线计算模式指的是:在同一 Stage 内部,所有算子融合为一个函数,Stage 的输出结果,由这个函数一次性作用在输入数据集而产生。
我们用一张图来直观地解释这一计算模式。
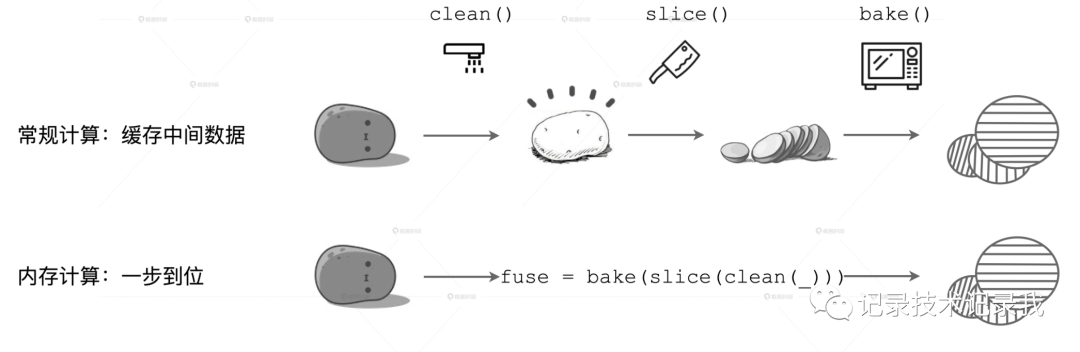
在上面的计算流程中,如果你把流水线看作是内存,每一步操作过后都会生成临时数据,如图中的 clean 和 slice,这些临时数据都会缓存在内存里。
但在下面的内存计算中,所有操作步骤如 clean、slice、bake,都会被捏合在一起构成一个函数。这个函数一次性地作用在“带泥土豆”上,直接生成“即食薯片”,在内存中不产生任何中间数据形态。
由于计算的融合只发生在 Stages 内部,而 Shuffle 是切割 Stages 的边界,因此一旦发生 Shuffle,内存计算的代码融合就会中断。但是,当我们对内存计算有了多方位理解以后,就不会一股脑地只想到用 cache 去提升应用的执行性能,而是会更主动地想办法尽量避免 Shuffle,让应用代码中尽可能多的部分融合为一个函数,从而提升计算效率。