本文转载自微信公众号「java宝典」,作者iTengyu。转载本文请联系java宝典公众号。
群里有小伙伴面试时,碰到面试官提了个很刁钻的问题:Mysql为何使用可重复读(Repeatable read)为默认隔离级别???
下面进入正题:
我们都知道事务的几种性质 :原子性、一致性、隔离性和持久性 (ACID)
为了维持一致性和隔离性,一般使用加锁这种方式来处理,但是加锁相对带来的是并发处理能力的降低
而数据库是个高并发的应用,因此对于加锁的处理是事务的精髓.
下面我们来了解一下封锁协议,以及事务在数据库中做了什么
封锁协议(Locking Protocol)
MySQL的锁系统:shared lock 和 exclusive lock 即共享锁和排他锁,也叫读锁(S)和写锁(X),共享锁和排他锁都属于悲观锁。排他锁又可以可以分为行锁和表锁。
封锁协议(Locking Protocol): 在使用X锁或S锁对数据加锁时,约定的一些规则.例如何时申请X或S锁,持续时间,何时释放锁等.
一级、二级、三级封锁协议
对封锁方式规定不同的规则,就形成了各种不同的封锁协议,不同的封锁协议,为并发操作的正确性提供不同程度的保证
一级封锁协议
一级封锁协议定义:事务T在修改数据R之前必须先对其加X锁(排他锁),直到事务结束才释放。事务结束包括正常结束(COMMIT)和非正常结束(ROLLBACK)。
一级封锁协议可以防止丢失修改,并保证事务T是可恢复的。使用一级封锁协议可以解决丢失修改问题。
在一级封锁协议中,如果仅仅是读数据不对其进行修改,是不需要加锁的,它不能保证可重复读和不读“脏”数据。
二级封锁协议
二级封锁协议定义:一级封锁协议加上事务T在读取数据R之前必须先对其加S锁(共享锁),读完后释放S锁。事务的加锁和解锁严格分为两个阶段,第一阶段加锁,第二阶段解锁。
- 加锁阶段: 在对任何数据进行读操作之前要申请并获得S锁(共享锁,其它事务可以继续加共享锁,但不能加排它锁),在进行写操作之前要申请并获得X锁(排它锁,其它事务不能再获得任何锁)。加锁不成功,则事务进入等待状态,直到加锁成功才继续执行。
- 解锁阶段:当事务释放了一个封锁以后,事务进入解锁阶段,在该阶段只能进行解锁操作不能再进行加锁操作。
二级封锁协议除防止了丢失修改,还可以进一步防止读“脏”数据。但在二级封锁协议中,由于读完数据后释放S锁,所以它不能保证可重复读。
二级封锁的目的是保证并发调度的正确性。就是说,如果事务满足两段锁协议,那么事务的并发调度策略是串行性的。保证事务的并发调度是串行化(串行化很重要,尤其是在数据恢复和备份的时候)
三级封锁协议
三级封锁协议定义:一级封锁协议加上事务T在读取数据R之前必须先对其加S锁(共享锁),直到事务结束才释放。在一级封锁协议(一级封锁协议:修改之前先加X锁,事务完成释放)的基础上加上S锁,事务结束后释放S锁
三级封锁协议除防止了丢失修改和不读“脏”数据外,还进一步防止了不可重复读。上述三级协议的主要区别在于什么操作需要申请封锁,以及何时释放。
事务四种隔离级别
在数据库操作中,为了有效保证并发读取数据的正确性,提出的事务隔离级别。上面提到的封锁协议 ,也是为了构建这些隔离级别存在的。
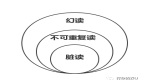
隔离级别 脏读(Dirty Read) 不可重复读(NonRepeatable Read) 幻读(Phantom Read)
| 隔离级别 | 脏读(Dirty Read) | 不可重复读(NonRepeatable Read) | 幻读(Phantom Read) |
|---|---|---|---|
| 未提交读(Read uncommitted) | 可能 | 可能 | 可能 |
| 已提交读(Read committed) | 不可能 | 可能 | 可能 |
| 可重复读(Repeatable read) | 不可能 | 不可能 | 可能 |
| 可串行化(Serializable ) | 不可能 | 不可能 | 不可能 |
为什么是RR
一般的DBMS系统,默认都会使用读提交(Read-Comitted,RC)作为默认隔离级别,如Oracle、SQL Server等,而MySQL却使用可重复读(Read-Repeatable,RR)。要知道,越高的隔离级别,能解决的数据一致性问题越多,理论上性能的损耗更大,且并发性越低。隔离级别依次为: SERIALIZABLE > RR > RC > RU
我们可以通过以下语句设置和获取数据库的隔离级别:
查看系统的隔离级别:
- mysql> select @@global.tx_isolation isolation;
- +-----------------+
- | isolation |
- +-----------------+
- | REPEATABLE-READ |
- +-----------------+
- 1 row in set, 1 warning (0.00 sec)
查看当前会话的 隔离级别:
mysql> select @@tx_isolation;
- mysql> select @@tx_isolation;
- +----------------+
- | @@tx_isolation |
- +----------------+
- | READ-COMMITTED |
- +----------------+
- 1 row in set, 1 warning (0.00 sec)
设置会话的隔离级别,隔离级别由低到高设置依次为:
- set session transacton isolation level read uncommitted;
- set session transacton isolation level read committed;
- set session transacton isolation level repeatable read;
- set session transacton isolation level serializable;
设置当前系统的隔离级别,隔离级别由低到高设置依次为:
- set global transacton isolation level read uncommitted;
- set global transacton isolation level read committed;
- set global transacton isolation level repeatable read;
- set global transacton isolation level serializable;
可重复读(Repeated Read):可重复读。基于锁机制并发控制的DBMS需要对选定对象的读锁(read locks)和写锁(write locks)一直保持到事务结束,但不要求“范围锁(range-locks)”,因此可能会发生“幻影读(phantom reads)” 在该事务级别下,保证同一个事务从开始到结束获取到的数据一致。是Mysql的默认事务级别。
下面我们先来思考2个问题
- 在读已提交(Read Commited)级别下,出现不可重复读问题怎么办?需要解决么?
不用解决,这个问题是可以接受的!毕竟你数据都已经提交了,读出来本身就没有太大问题!Oracle ,SqlServer 默认隔离级别就是RC,我们也没有更改过它的默认隔离级别.
- 在Oracle,SqlServer中都是选择读已提交(Read Commited)作为默认的隔离级别,为什么Mysql不选择读已提交(Read Commited)作为默认隔离级别,而选择可重复读(Repeatable Read)作为默认的隔离级别呢?
历史原因,早阶段Mysql(5.1版本之前)的Binlog类型Statement是默认格式,即依次记录系统接受的SQL请求;5.1及以后,MySQL提供了Row,Mixed,statement 3种Binlog格式, 当binlog为statement格式,使用RC隔离级别时,会出现BUG因此Mysql将可重复读(Repeatable Read)作为默认的隔离级别!
Binlog简介
Mysql binlog是二进制日志文件,用于记录mysql的数据更新或者潜在更新(比如DELETE语句执行删除而实际并没有符合条件的数据),在mysql主从复制中就是依靠的binlog。可以通过语句“show binlog events in 'binlogfile'”来查看binlog的具体事件类型。binlog记录的所有操作实际上都有对应的事件类型的
MySQL binlog的三种工作模式:Row(用到MySQL的特殊功能如存储过程、触发器、函数,又希望数据最大化一直则选择Row模式,我们公司选择的是row) 简介:日志中会记录每一行数据被修改的情况,然后在slave端对相同的数据进行修改。优点:能清楚的记录每一行数据修改的细节 缺点:数据量太大
Statement (默认)简介:每一条被修改数据的sql都会记录到master的bin-log中,slave在复制的时候sql进程会解析成和原来master端执行过的相同的sql再次执行。在主从同步中一般是不建议用statement模式的,因为会有些语句不支持,比如语句中包含UUID函数,以及LOAD DATA IN FILE语句等 优点:解决了 Row level下的缺点,不需要记录每一行的数据变化,减少bin-log日志量,节约磁盘IO,提高新能 缺点:容易出现主从复制不一致
Mixed(混合模式)简介:结合了Row level和Statement level的优点,同时binlog结构也更复杂。
我们可以简单理解为binlog是一个记录数据库更改的文件,主从复制时需要此文件,具体细节先略过
主从不一致实操
binlog为STATEMENT格式,且隔离级别为**读已提交(Read Commited)**时,有什么bug呢?测试表:
- mysql> select * from test;
- +----+------+------+
- | id | name | age |
- +----+------+------+
- | 1 | NULL | NULL |
- | 2 | NULL | NULL |
- | 3 | NULL | NULL |
- | 4 | NULL | NULL |
- | 5 | NULL | NULL |
- | 6 | NULL | NULL |
- +----+------+------+
- 6 rows in set (0.00 sec)
| Session1 | Session2 |
|---|---|
| mysql> set tx_isolation = 'read-committed'; | |
| Query OK, 0 rows affected, 1 warning (0.00 sec) | mysql> set tx_isolation = 'read-committed'; |
| Query OK, 0 rows affected, 1 warning (0.00 sec) | |
| begin; Query OK, 0 rows affected (0.00 sec) |
begin; Query OK, 0 rows affected (0.00 sec) |
| delete from test where 1=1; | |
| Query OK, 6 rows affected (0.00 sec) | |
| insert into test values (null,'name',100); | |
| Query OK, 1 row affected (0.00 sec) | |
| commit; | |
| Query OK, 0 rows affected (0.01 sec) | |
| commit; | |
| Query OK, 0 rows affected (0.01 sec) |
Master此时输出
- select * from test;
- +----+------+------+
- | id | name | age |
- +----+------+------+
- | 7 | name | 100 |
- +----+------+------+
- 1 row in set (0.00 sec)
但是,你在此时在从(slave)上执行该语句,得出输出
- mysql> select * from test;
- Empty set (0.00 sec)
在master上执行的顺序为先删后插!而此时binlog为STATEMENT格式,是基于事务记录,在事务未提交前,二进制日志先缓存,提交后再写入记录的,因此顺序为先插后删!slave同步的是binglog,因此从机执行的顺序和主机不一致!slave在插入后删除了所有数据.
解决方案有两种!(1)隔离级别设为可重复读(Repeatable Read),在该隔离级别下引入间隙锁。当Session 1执行delete语句时,会锁住间隙。那么,Ssession 2执行插入语句就会阻塞住!(2)将binglog的格式修改为row格式,此时是基于行的复制,自然就不会出现sql执行顺序不一样的问题!奈何这个格式在mysql5.1版本开始才引入。因此由于历史原因,mysql将默认的隔离级别设为可重复读(Repeatable Read),保证主从复制不出问题!
RU和Serializable
项目中不太使用**读未提交(Read UnCommitted)和串行化(Serializable)**两个隔离级别,原因:
读未提交(Read UnCommitted)
允许脏读,也就是可能读取到其他会话中未提交事务修改的数据 一个事务读到另一个事务未提交读数据
串行化(Serializable)
使用的悲观锁的理论,实现简单,数据更加安全,但是并发能力非常差。如果你的业务并发的特别少或者没有并发,同时又要求数据及时可靠的话,可以使用这种模式。一般是使用mysql自带分布式事务功能时才使用该隔离级别
RC和 RR
此时我们纠结的应该就只有一个问题了:隔离级别是用读已提交还是可重复读?
接下来对这两种级别进行对比的第一种情况:
在RR隔离级别下,存在间隙锁,导致出现死锁的几率比RC大的多!
实现一个简单的间隙锁例子
- select * from test where id <11 ;
- +----+------+------+
- | id | name | age |
- +----+------+------+
- | 1 | NULL | NULL |
- | 2 | NULL | NULL |
- | 3 | NULL | NULL |
- | 4 | NULL | NULL |
- | 5 | NULL | NULL |
- | 6 | NULL | NULL |
- | 7 | name | 7 |
- +----+------+------+
- 7 rows in set (0.00 sec)
| session1 | session2 |
|---|---|
| mysql> set tx_isolation = 'repeatable-read'; | |
| Query OK, 0 rows affected, 1 warning (0.00 sec) | mysql> set tx_isolation = 'repeatable-read'; |
| Query OK, 0 rows affected, 1 warning (0.00 sec) | |
| Begin; | |
| select * from test where id <11 for update; | |
| insert into test values(null,'name',9); //被阻塞! | |
| commit; | |
| Query OK, 0 rows affected (0.00 sec) | |
| Query OK, 1 row affected (12.23 sec) //锁释放后完成了操作 |
在RR隔离级别下,可以锁住(-∞,10] 这个间隙,防止其他事务插入数据!而在RC隔离级别下,不存在间隙锁,其他事务是可以插入数据!
ps:在RC隔离级别下并不是不会出现死锁,只是出现几率比RR低而已
锁表和锁行
在RR隔离级别下,条件列未命中索引会锁表!而在RC隔离级别下,只锁行
- select * from test;
- +----+------+------+
- | id | name | age |
- +----+------+------+
- | 8 | name | 11 |
- | 9 | name | 9 |
- | 10 | name | 15 |
- | 11 | name | 15 |
- | 12 | name | 16 |
- +----+------+------+
锁表的例子:
| session1 | session2 |
|---|---|
| Begin; | |
| update test set age = age+1 where age = 15; | |
| Rows matched: 2 Changed: 2 Warnings: 0 | |
| insert into test values(null,'test',15); | |
| ERROR 1205 (HY000): Lock wait timeout exceeded; | |
| Commit; |
session2插入失败 查询 数据显示:
- select * from test;
- +----+------+------+
- | id | name | age |
- +----+------+------+
- | 8 | name | 11 |
- | 9 | name | 9 |
- | 10 | name | 16 |
- | 11 | name | 16 |
- | 12 | name | 16 |
- +----+------+------+
半一致性读(semi-consistent)特性
在RC隔离级别下,半一致性读(semi-consistent)特性增加了update操作的并发性!
在5.1.15的时候,innodb引入了一个概念叫做“semi-consistent”,减少了更新同一行记录时的冲突,减少锁等待。所谓半一致性读就是,一个update语句,如果读到一行已经加锁的记录,此时InnoDB返回记录最近提交的版本,判断此版本是否满足where条件。若满足则重新发起一次读操作,此时会读取行的最新版本并加锁!
建议
在RC级别下,用的binlog为row格式,是基于行的复制,Innodb的创始人也是建议binlog使用该格式
互联网项目请用:读已提交(Read Commited)这个隔离级别
总结
由于历史原因,老版本Mysql的binlog使用statement格式,不使用RR隔离级别会导致主从不一致的情况
目前(5.1版本之后)我们使用row格式的binlog 配合RC隔离级别可以实现更好的并发性能.