本文转载自微信公众号「数仓宝贝库」,作者赵国生,王健。转载本文请联系数仓宝贝库公众号。
目前,许多网站采取各种各样的措施来反爬虫,其中一个措施便是使用验证码。随着技术的发展,验证码的花样越来越多。验证码最初是几个数字组合的简单的图形验证码,后来加入了英文字母和混淆曲线。有的网站还可能看到中文字符的验证码,这使得识别越发困难。
使用验证码可以防止应用或者网站被恶意注册、攻击,对于网站、APP而言,大量的无效注册、重复注册甚至是恶意攻击很令人头痛。使用验证码能够很大程度上减少这些恶意操作。验证码变得越来越复杂,爬虫的工作也变得越发艰难。有时候我们必须通过验证码的验证才能够访问页面(如图1所示)。
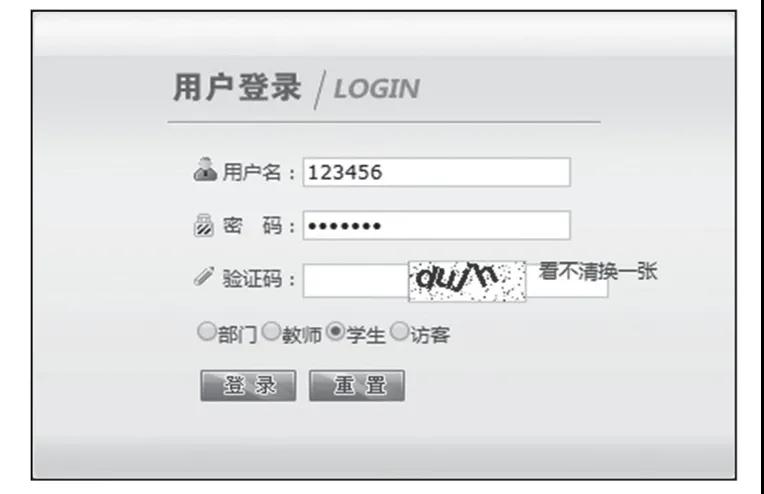
图1 验证码界面
目前主流的 4 种验证码为输入式验证码、滑动式验证码、宫格式验证码和点击式的图文验证,下面我们来分别讲解它们的解决思路。
4种验证码的解决思路
01 输入式验证码
这种验证码主要是通过用户输入图片中的字母、数字、汉字等进行验证,如图2所示。

图2 输入式验证码
解决思路:这是最简单的一种验证码,只要识别出里面的内容,然后填入输入框中即可。这种识别技术叫OCR,这里推荐使用 Python 的第三方库 tesserocr。tesserocr 与 pytesseract 是 Python 的一个 OCR 识别库,但其实是对 Tesseract 做的一层 Python API 封装,pytesseract 是 Google 的 Tesseract-OCR 引擎包装器;所以它们的核心是 Tesseract。对于没有什么背景影响的验证码,直接通过这个库来识别就可以。但是对于有嘈杂的背景的验证码,直接识别的识别率会很低,遇到这种验证码需要先对图片进行灰度化,然后再进行二值化,再去识别,这样识别率会大大提高。
02 滑动式验证码
这种是将备选碎片直线滑动到正确的位置,如图3所示。

图3 滑动式验证码
解决思路:对于这种验证码就比较复杂一点,但也是有相应的办法。我们直接想到的就是模拟人去拖动验证码的行为,点击按钮,然后看到了缺口的位置,最后把拼图拖到缺口位置处完成验证。
第一步:点击按钮。当没有点击按钮的时候图片中的缺口和拼图是没有出现的,点击后才出现,这为我们找到缺口的位置提供了灵感。
第二步:拖到缺口位置。我们知道拼图应该拖到缺口处,但是这个距离如何用数值来表 示?通过第一步观察到的现象,我们可以找到缺口的位置。这里我们可以比较两张图的像素, 设置一个基准值,如果某个位置的差值超过了基准值,那我们就找到了这两张图片不一样的位置,当然我们是从那块拼图的右侧开始并且从左到右,找到第一个不一样的位置时就结束,这时的位置应该是缺口的 left,所以我们使用 selenium 拖到这个位置即可。这里还有个疑问,就 是如何能自动保存这两张图?我们可以先找到这个标签,然后获取它的 location 和 size,接着 是 top = int(location['y'])、bottom = int(location['y'] + size['height'])、left = int(location['x']) 以及right = int(location['x'] + size['width']),然后截图,最后抠图填入这四个位置就行。具体的使用 可以查看 selenium 文档,点击按钮前抠一张图,点击后再抠一张图。最后拖动时需要模拟人的 行为,先加速然后减速。因为这种验证码有行为特征检测,人是不可能做到一直匀速的,否则 它就判定为是机器在拖动,这样就无法通过验证了。
03 宫格验证码
如图4所示的验证码,爬虫难度比较大,每一次出现的都不一样,就算出现一样的,其拖动顺序也不相同。但是,我们发现不一样的验证码个数是有限的,这里采用模版匹配的方 法,把所有出现的验证码保存下来,然后挑出不一样的验证码,按照拖动顺序命名。我们从 左到右从上到下,将其分别设为 1、2、3、4。上图的滑动顺序为 4→3→2→1,所以我们命名 4_3_2_1.png。当验证码出现的时候,用我们保存的图片一一枚举,与出现的这种来比较像素, 方法见“滑动式验证码”部分。如果匹配上了,拖动顺序就为 4→3→2→1。然后使用 selenium 模拟即可。
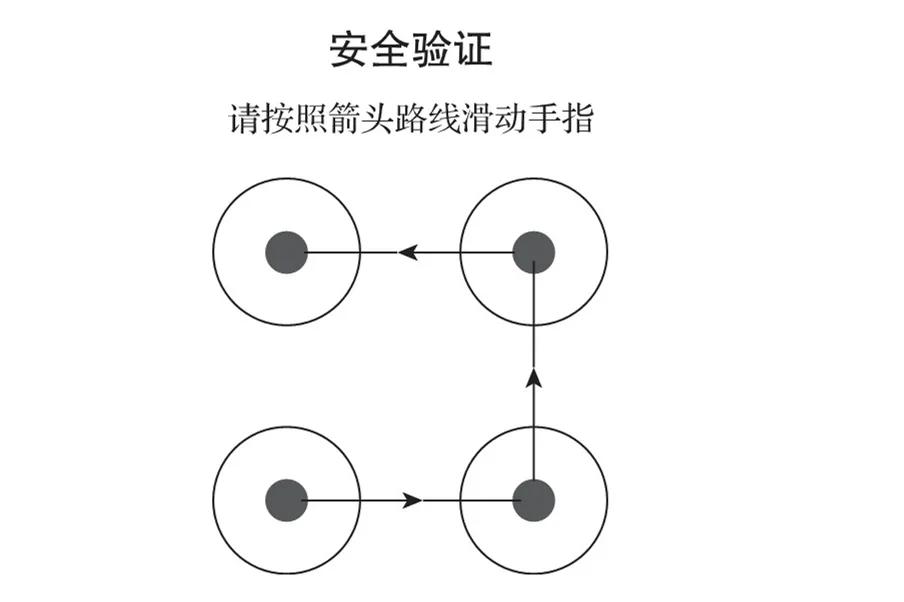
图4 宫格验证码
04 点击式的图文验证和图标选择
1)图文验证:通过文字提醒用户点击图中相同字的位置从而进行验证。
2)图标选择:给出一组图片,按要求点击其中一张或多张。借用万物识别的难度阻挡 机器。这两种原理相似,只不过一个是给出文字,点击图片中的文字,而一个是给出图片,点 出内容相同的图片。这两种都没有特别好的方法,只能借助第三方识别接口来识别出相同的内 容。推荐一个方法,把验证码发过去,会返回相应的点击坐标,然后再使用 selenium 模拟点击即可。
OCR验证码
图片
OCR(Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式来确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程,下面介绍使用这种图像识别技术输入验证码的方法。
验证码识别基本步骤:
1)预处理
2)灰度化
3)二值化
4)去噪
5)分割
6)识别
在使用pytesseract之前,必须安装 Tesseract-OCR,因为pytesserat 依赖于 Tesseract-OCR, 若未安装则无法使用。首先使用 pytesseract 将彩色的图像转化为灰色的图像。
- # 使用路径导入图片
- im = Image.open(imgimgName)
- # 使用byte流导入图片
- # im = Image.open(io.BytesIO(b))
- # 转化到灰度图
- imgry = im.convert('L')
- # 保存图像
- imgry.save('gray-'+imgName)
灰度化的图像如图5所示。

图5 灰度化图像
紧接着将所得的图像二值化,将图片处理为只有黑白两色的图片,利于后面的图像处理和识别。
- # 二值化,采用阈值分割法,threshold为分割点
- Threshold = 140
- Table = [ ]
- For j in range(256):
- If j < threshold:
- Table.append(0)
- Else:
- Table.append(1)
- Out = imgry.point(table,'1')
- Out.save('b'+imgName)
二值化的图像如图 6 所示。

图6 二值化图像
最后进行识别,得到的结果如图7所示。
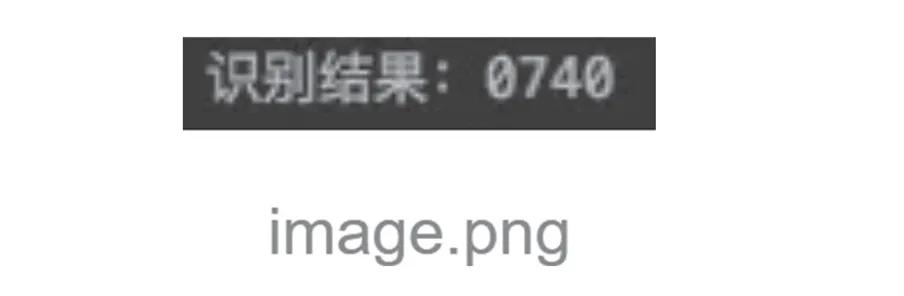
图7 识别结果
- # 识别
- Text = pytesseract.image_to_string(out)
- Print(“识别结果:" +text)
实战案例
目前,很多网站为了防止爬虫肆意模拟浏览器登录,采用增加验证码的方式来拦截爬虫。验证码的形式有多种,最常见的就是图片验证码。
1 基本识别原理概述
1)每一幅图像在结构上,都是由一个个像素组成的矩阵,每一个像素都为单元格。
2)彩色图像的像素由三原色(红、绿、蓝)构成 元组,灰度图像的像素是一个单值,每个像素的值范围为(0, 255)。
某系统门户登录界面中的验证码如图8所示, 现在我们要实现自动的验证码识别。

图8 验证码
2 图像特征
首先,我们仔细观察一下这个验证码图像,可以发现一些如图9所示的固定特征。
1)验证码中的字符数始终为 6,并且是灰度图像。
2)字符间的间隔看起来每次都一样。
3)每个字符都是完全定义的。
4)图像有许多杂散的黑暗像素,以及穿过图像的线条作为干扰因素。
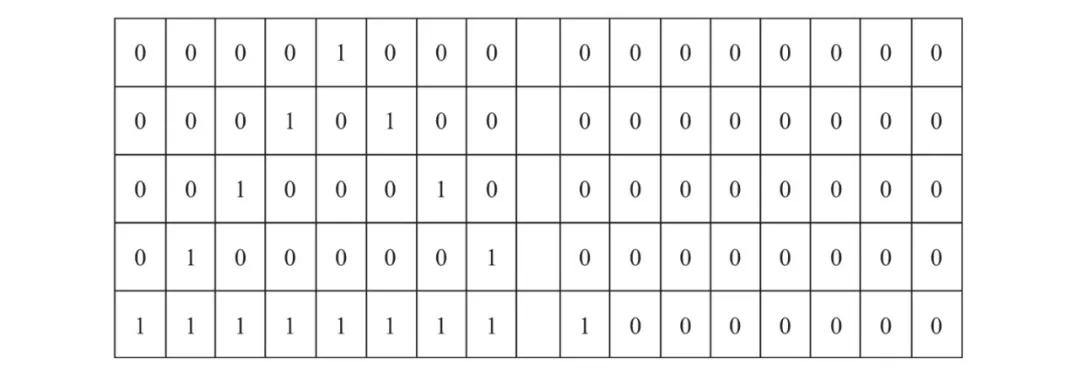
图9 固定特征
3 图像分析
使用一个工具(binary-image)以二进制形式可视化图像(0 表示黑色像素,1 表示白色像 素)。图像尺寸为 45×180,每个字符分配 30 个像素的空间来进行适配,从而使它们的间隔比 较均匀。因此,取得了验证码识别路上的第一步。如图10所示的结果:把图像裁剪成 6 个不同的部分,每个部分的宽度均为 30 像素。

图10 二进制可视化图像
4 字符部分裁剪
图像裁剪的语法如下:
- from PIL import Image
- image = Image.open("filename.png")
- cropped_image = image.crop((left, upper, right, lower)
比如要裁剪第一个字符:
- from PIL import Image
- image = Image.open("captcha.png").convert("L")
- cropped_image = image.crop((0, 0, 30, 45))
- cropped_image.save("cropped_image.png")
得到的图像如图11所示。

图11 结果图像
将其打包到一个循环中,编写了一个简单的脚本,从该站点获取 500 个验证码图像,并将所有裁剪后的字符保存到一个文件夹中。
5 图像去杂
为了“清理”图像中的干扰因素(删除不必要的线和点),我们可以使用一个很简单的算法:字符中的所有像素都是纯黑色(0)。如果它不是完全黑色的,则将它当成白色的。因此,对于值大于0的每个像素,将给其重新赋值为255。使用 load() 函数将图像转换为 45×180 数字矩阵,然后对其进行处理。
- pixel_matrix = cropped_image.load()
- for col in range(0, cropped_image.height):
- for row in range(0, cropped_image.width):
- if pixel_matrix[row, col] != 0:
- pixel_matrix[row, col] = 255
- image.save("thresholded_image.png"
为了清晰起见,将代码应用于原始图像。原始图像如图12所示。

图12 原始图像
矫正后的图像如图13所示。

图13 矫正后的图像
可以看到,并非完全黑暗的所有像素都被删除了,比如通过图像的线。上述方法在图像处理 中的专业术语叫作阈值处理,当然还有很多其他的处理方法,阈值处理只是最简单实用的方法。
6 去除图像中的黑点
图像中有许多杂散的黑暗像素作为干扰因子。循环遍历图像矩阵,如果相邻像素是白色的,并且与相邻像素相对的像素也是白色的,而中心像素是黑色的,则设定中心像素为白色。
- for column in range(1, image.height - 1):
- for row in range(1, image.width - 1):
- if pi xel_matrix[row, column] == 0 and pixel_matrix[row, column - 1] == 255 and
- pixel_matrix[row, column + 1] == 255:
- pixel_matrix[row, column] = 255
- if pi xel_matrix[row, column] == 0 and pixel_matrix[row - 1, column] == 255 and
- pixel_matrix[row + 1, column] == 255:
- pixel_matrix[row, column] = 25
处理后的结果如图14所示。

图14 处理后的结果
经过以上步骤的处理,图像已经只剩下字符框架了。虽然有些字符已经丢失了一些基础像 素,但是每个字符的图像骨架基本上都完备。当然这个是必需的,我们进行这么多处理的主要 目的就是为每个可能的字符都截取生成合适的字符图。
7 构建字符图库
将上述算法裁剪得到的所有字符图像都存储于文件夹下。下一个任务是为属于“ A-Z0-9” 的每个字符找到至少一个样本图像(如图15所示)。这一步就像“训练”步骤,手动为每个 字符选择了一个字符图像并对其更名。

图15 样本图像
8 选择最优的字符图
运行其他几个脚本,以确保每个字符的图像中都有最佳的图像,例如,如果有 20 个“ A” 的字符图像,那么暗色数量最少的图像显然是噪声最少的图像,因此最适合作为骨架图像。选择的原则如下:
1)一个按照字符排序的相似图像(约束条件:黑色像素数量大小,并且相似度 > = 90%~95%)。
2)一个从每个分组字符获得的最佳图像。因此,到目前为止,我们生成了一个像素图像库。我们将其转换为像素矩阵,并将位图字符图转为数字点阵 JSON 文件。
9 识别算法
最后是获取任何新的验证码图像的算法:使用相同的算法尽量减少新图像中不必要的干扰因子。对于新验证码图片中的每个字符,强制通过与生成的 JSON 文件的像素矩阵来匹配,基 于相应的黑色像素匹配来计算相似度。如果一个像素是黑色的,其在图像中的位置恰好是待破 解的验证码,并且此像素位于字符库中的骨架图像 / 位图内的相同位置处,则计数会递增 1。与骨架图像中黑色像素的数量进行对比,计算匹配百分比,选择具有最高匹配百分比的字符就是识别结果的字符。
最终结果如图16所示,若得到的字符为 Z5M3MQ,则验证码被成功识别出来了。

图16 识别结果