













【51CTO.com快译】
介绍
本文是对数据平台即服务(Data Platform- as- a- Service,)的后续研究,描述了其高层体系结构,并对数据湖进行了详细介绍。架构的重要之处不在于供应商或特定产品,而在于我们使用的组件的功能。最终,产品的选择取决于许多因素:
• 团队的知识。
• 云服务中的使用效率。
• 能够与我们现有的产品集成。
• 运行成本。
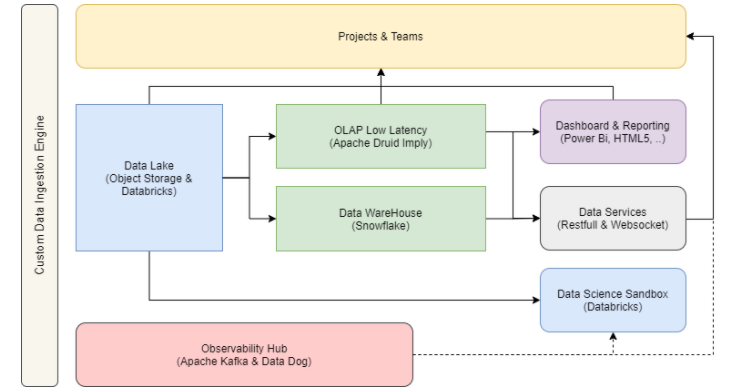
自定义数据域引擎
在本例中,我们设计了一个主要基于 Azure 服务的解决方案。同时,设计了一个架构,允许以敏捷的方式集成或者迁移到其他云服务上。
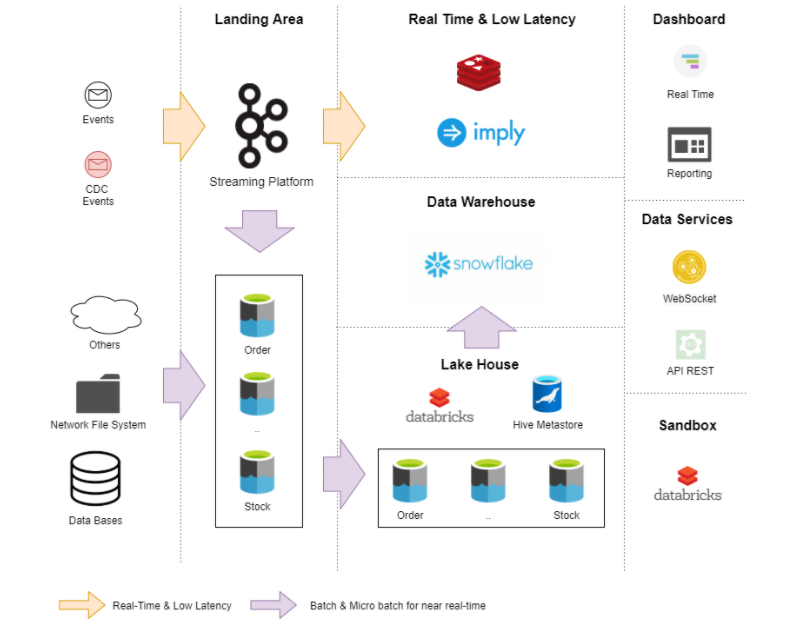
云数据平台架构
拥有敏捷的云数据平台,而不限制供应商取决于:
• 使用开源技术作为平台的核心。这使我们能够将我们的平台转移到另一个云提供商。
• 提供数据集线器服务,用于流式和批处理数据。
• 自动化数据管道允许我们轻松地将数据移动到不同的数据存储库。
• 数据服务层与数据持久化引擎解耦。
数据模型(域驱动设计)
数据平台需要全局数据模型定义。目前,许多企业、特别是一些技术类型的公司,都会采用域驱动设计(Domain Driven Design,DDD)的方法。
关于数据域的一些重要事项如下:
• 数据域有两种视图,生产者数据域和消费者数据域。通常,这些域是不同的,因为消费者的域是来自多个生产者域的数据组成的。
• 特定数据可以有一个主域和一个辅助域。
• 数据域组织不是静态的。可以被更改、合并、演化或删除。
在数据域方面,常用的方法是遵循自底向上的设计。这就意味着从生产者数据域开始,数据产品将被视为自己的消费者进行构建。因此,数据平台需要为他们提供所有必要的工具、服务、支持、标准化流程和集成。
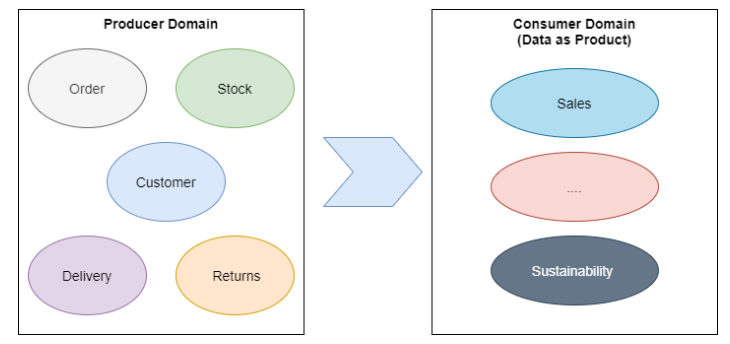
从生产者到消费域
销售域是消费者数据域的一个非常常见的用例,并且非常复杂。什么是销售?在一家拥有多渠道订单(电子商务、社交媒体、实体店...)的大公司里,渠道和部门之间的销售概念略有不同。但是他们是由那些来自多个域的数据所组成的。
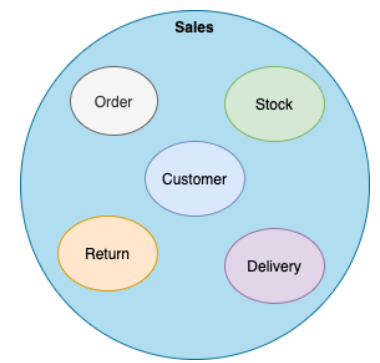
销售域
因为每个团队可能会有不同的数据产品,需要不同的数据、数据验证过程和指标。就好像电商部门和财务部门的销售数据产品是一样的吗?这取决于很多因素。
数据摄取模式
众所周知,一个新的数据平台最宝贵的资源就是数据,上传数据有两种方法:
• Pull : 基于核心团队和集中管理,开发数据管道,将数据摄取到平台中。
• Push:在操作、架构和范式方面,这是最好的方法,但它取决于其他团队。例如,分销团队需要分析销售数据。拥有销售数据需要销售团队将数据推送到数据平台。
遵循“推送”方法,在操作、架构和范式方面,这是一个很好的决策。这取决于企业架构的实际情况,我们必须提供“Pull”功能,因为在许多公司中,通常有许多遗留系统或团队没有准备好推送数据。
在我们看来,提供“Pull”服务的最佳方式是开发一个自动化数据摄取引擎服务。
什么是数据摄取引擎服务?
数据摄取引擎服务是一个自助服务平台,只需要SQL语句和映射,无需代码,允许创建ETL进程和流式处理。
其目标是通过提供多种风格,来涵盖如下方面::
• 允许团队自行将数据推送到交换区。
• 提供一个核心和集中的团队,为非技术团队上传数据。
• 提供一个自助服务平台,简化技术团队的数据摄取。
如果我们对所有类型的数据摄取管道采用相同的方法,将会拥有一整套自动化的连接器,可方便团队推送他们的各种数据。例如:
• 更改数据捕获。
• 事件。
• 图像、文件等...
这里的主要思想是通过构建产品所有者将来用于推送数据的公共组件,从一个不需要的“拉取策略”转向“Push模型”。从而实现自动摄取层。
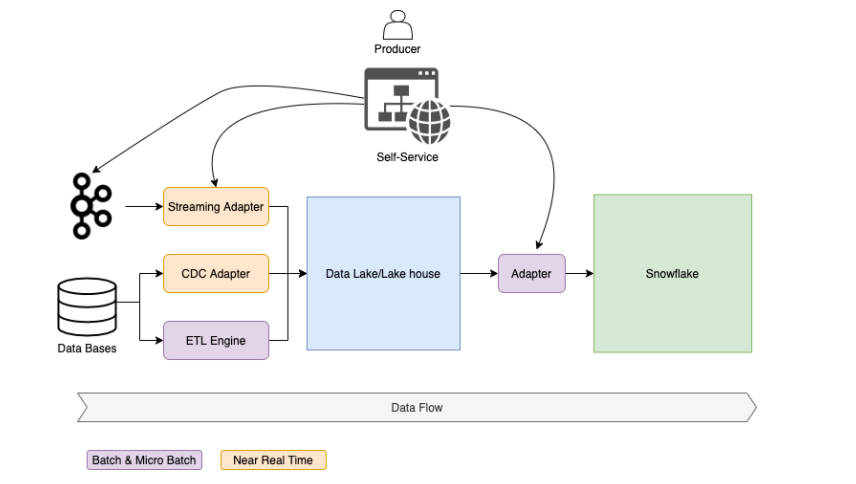
批处理数据流
如图所示,我们必须提供所有的工具和标准流程(摄取、数据质量等),以允许生产商将其数据自动推送到数据平台。这种自助服务可以是 Web 门户或 GitOps 解决方案。
下面的文章将详细介绍如何开发一个摄取引擎。
微服务架构:Push
事件驱动的微服务体系架构是应用基于流的“推送策略”的最佳方案之一。这些体系结构遵循发布-订阅通信模式,通常基于持久消息传递系统,如Apache Kafka。
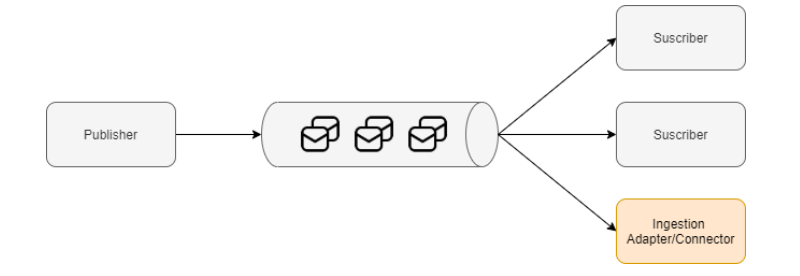
微服务架构模式
这种模式提供了可扩展和松散耦合的架构:
• 发布者向主题发送一条消息。
• 所有注册此主题的订阅者都会收到此消息。事件一次生成,多次消耗。
• 发布者和订阅者操作可以相互独立地操作。它们之间没有依赖关系。
我们可以提供一个标准的接受连接器来订阅这些主题,并将事件以实时的方式摄取数据平台。这些架构在信息范围方面存在挑战,通常不会涵盖:
• 这些持久主题通常具有基于时间或大小的限制。在出现错误场景的情况下,重新处理更为复杂。
• 重新发送历史数据的过程。
• 用于大规模场景的异步数据质量API。
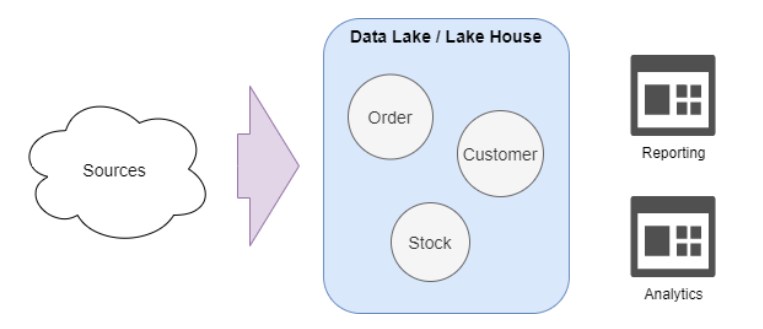
数据湖
数据湖是分析、机器学习环境和存储原始数据的自然选择。数据湖是一个数据存储库,通常基于对象存储,它允许我们存储的内容如下:
• 关系数据库中的结构化数据。
• 来自 NoSQL 或其他来源(CSV、XML、JSON)的半结构化数据。
• 非结构化数据和二进制数据(文档、视频、图像)。
• 目前,云存储服务已经有了很大改进,并提供了不同的服务质量,使我们能够:
• 为热数据提供高性能和低延迟。
• 以较低的成本拥有较大的存储容量和较高的延迟,用于冷数据和热数据。
作为云对象存储,我们选择了Azure Data Lake Storage Gen2。此对象存储提供了一些有趣的特性:
• 体积:它可以管理大量的数据、PB 级的信息和千兆位的吞吐量。
• 性能:针对分析用例进行优化。
• 安全性:它允许POSIX对目录或单个文件的权限。使用服务主体和 OAuth 2.0 将 Azure Data Lake Storage Gen2 文件系统装载到 DBFS
• 事件:它提供了一种服务,可以为每个执行的操作自动生成一个事件,例如创建和删除文件。这些事件允许设计事件驱动的数据流程。
我们必须根据用户和用例做出几个决定:
• 提供对数据的只读访问。为所有用户提供单一的数据存储库。
• 结构化数据和半结构化数据以列格式存储。
• 数据按业务数据域分区存储,并分布在多个对象存储中。
• 提供一个Hive Metastore 服务,通过使用外部表提供spark-SQL访问。这允许拥有数据的单个图像,并将用户从数据的物理位置中抽象出来。
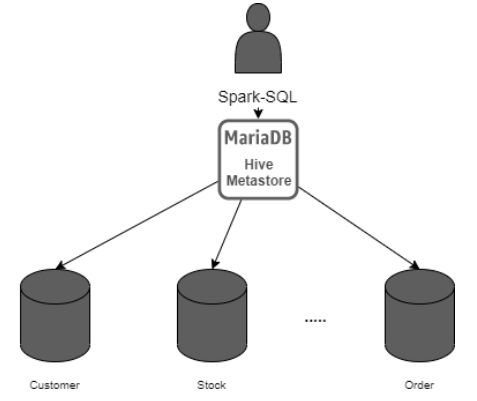
MariaDB
现在,我们可以使用由我们管理的外部配置单元元存储(hivemetastore),这是一个开源版本,而不是带有集成限制的供应商管理的服务。这使我们可以自由地集成任何 Spark 环境,而不管是谁提供了 Spark 平台环境(Databricks、Cloudera 等)。
Spark-SQL 和 Hive Metastore
Spark SQL 为我们提供了一个分布式查询引擎,以更优化的方式使用结构化和半结构化数据,并使用类似于数据目录的 Hive Metastore。使用 SQL,我们可以从以下位置查询数据:
• 数据帧和数据集 API。
• 外部工具,如Databricks Notebooks。这是一个用户友好的工具,方便非技术用户使用数据。
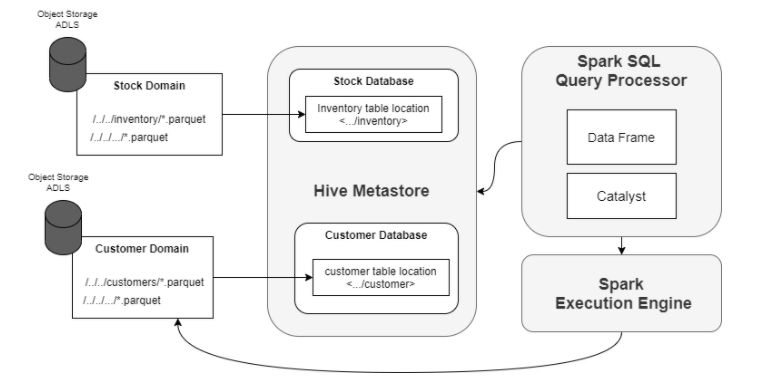
Hive Metastore
数据湖即服务
如果我们把到目前为止描述的所有部分放在一起,就可以设计和构建一个数据湖平台:
• 数据摄取引擎 负责摄取数据,在配置单元元存储中创建和管理元数据。
• 数据湖的核心由对象存储层和 Hive Metastore 组成。这是允许我们将计算层作为服务提供的两个主要组件。
• 计算层由 集成到数据湖中的几个sparks集群组成。这些集群允许使用 spark 作业、SQL 分析或 Databrick Notebooks 访问这些数据。
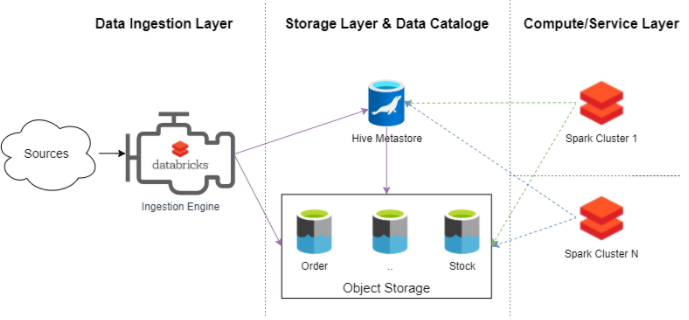
数据湖即服务
在我们看来,提供这种动态且可扩展的计算/服务层的能力使我们能够将数据湖平台作为服务提供,否则我们将拥有与传统本地数据湖更相似的东西。我们可以创建一个 24x7 的永久集群,也可以创建临时集群来运行我们的工作。Spark 集群是计算和服务层的核心。它是我们将在 数据湖平台中提供的服务目录的最小公约数。
例如,我们想为我们的数据产品团队提供沙盒分析服务。我们将为每个人创建一个独立的计算环境,但所有人都将访问相同的数据。要将这些功能作为服务提供,我们需要:
• 基于 Spark 技术定义组成沙箱分析的组件。
• 通过 Web 服务目录或代码方式 (git-ops) 提供自助服务功能。
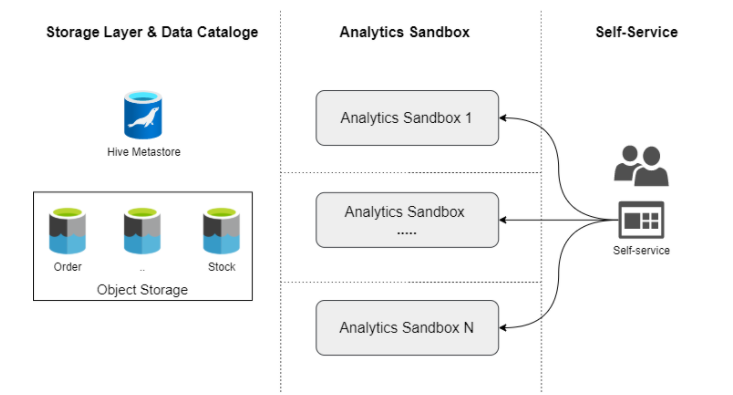
自助服务组件
这是一个非常简化的视图,因为我们没有定义安全性、高可用性或数据质量服务。
Delta Lake提供什么?
Delta Lake是一个开源层,提供了ACID功能,并确保读者永远不会看到不一致的数据。数据管道可以在不影响正在运行的 spark 进程的情况下刷新数据。
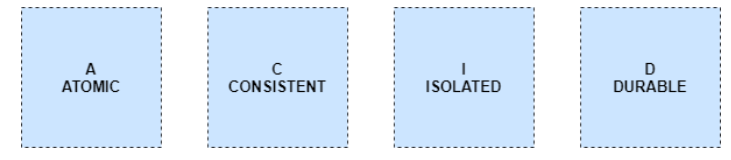
数据管道
还有其他重要的功能,例如:
• Schema on-write:它在写入数据时强制执行模式检查,当检测到模式不匹配时,作业失败。
• Schema Evolution:它支持兼容的方案演变的模式,例如添加新列。
• Time travel:数据版本控制是机器学习用例中的一个重要功能。允许以代码形式管理数据。作为代码存储库,用户拥有数据的版本控制,对于数据集的每一次更改,都会在其整个生命周期中生成数据的新版本。
• Merge:支持合并、更新和删除操作,以实现复杂的摄取方案。
数据湖的演变
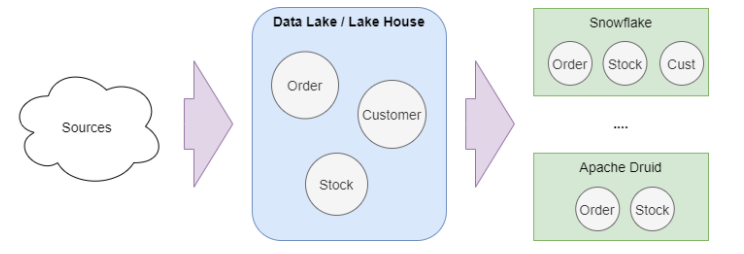
几年前,传统数据湖、数据仓库和数据中心之间的区别是概念性的,也是技术性的。

三者区别
基于 Hadoop、Spark、Parquet、Hive 等的数据湖技术有很多局限性。目前,Delta Lake和ApacheHudi等其他选项为数据湖生态系统添加了新的功能。这些特性与解偶联架构(计算和存储层)、无服务器以及其他新功能,(如SQL分析或来自数据库的Delta引擎)结合,正在开发新一代的数据湖平台。
Databricks 将这一新一代命名为Lake House。在我们看来,现在新一代的成熟度允许数据湖提供两个新角色:
• 数据中心。
数据中心
• 数据仓库的细节和减少梗概。
数据仓库
数据仓库的功能有了很大的提高,但此时,它仍然需要高水平的技术知识来分发数据,并实现与其他产品(如Snowflake、Big query或Oracle Autonomous data Warehouse)相同的性能。
结论
结合Kafka等事件中心,新一代数据湖是成为我们数据平台核心的好选择。 它是一项成熟的技术,主要基于开源,在性价比上非常有竞争力,在不断演进,我们可以在所有云供应商中提供。
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】
















