前言
笔者一直觉得如果能知道从应用到框架再到操作系统的每一处代码,是一件Exciting的事情。今天笔者就从Linux源码的角度看下Server端的Socket在进行Accept的时候到底做了哪些事情(基于Linux 3.10内核)。
一个最简单的Server端例子
众所周知,一个Server端Socket的建立,需要socket、bind、listen、accept四个步骤。
今天,笔者就聚焦于accept。
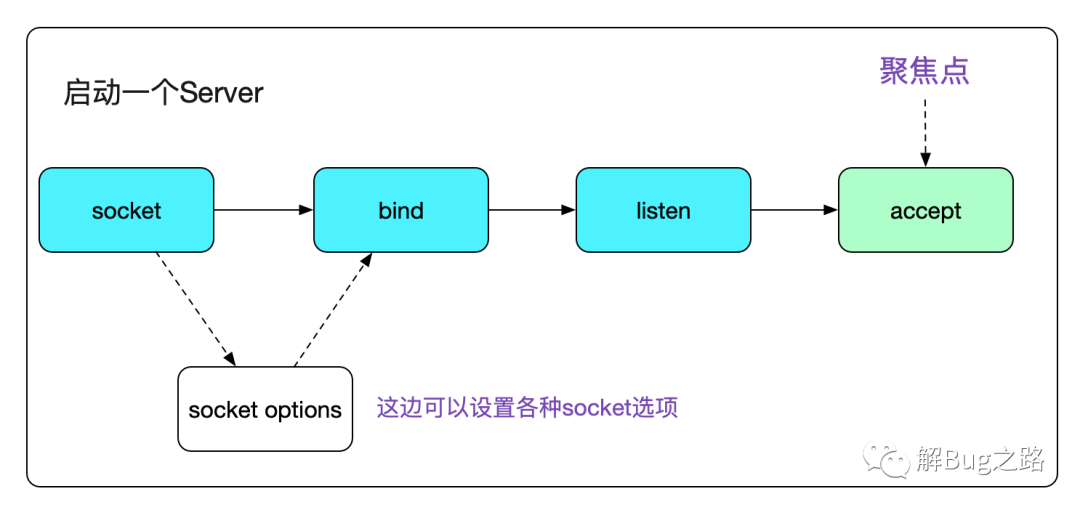
代码如下:
void start_server(){
// server fd
int sockfd_server;
// accept fd
int sockfd;
int call_err;
struct sockaddr_in sock_addr;
......
call_err=bind(sockfd_server,(struct sockaddr*)(&sock_addr),sizeof(sock_addr));
......
call_err=listen(sockfd_server,MAX_BACK_LOG);
......
while(1){
struct sockaddr_in* s_addr_client = mem_alloc(sizeof(struct sockaddr_in));
int client_length = sizeof(*s_addr_client);
// 这边就是我们今天的聚焦点accept
sockfd = accept(sockfd_server,(struct sockaddr_ *)(s_addr_client),(socklen_t *)&(client_length));
if(sockfd == -1){
printf("Accept error!\n");
continue;
}
process_connection(sockfd,(struct sockaddr_in*)(&s_addr_client));
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
首先我们通过socket系统调用创建了一个Socket,其中指定了SOCK_STREAM,而且最后一个参数为0,也就是建立了一个通常所有的TCP Socket。在这里,我们直接给出TCP Socket所对应的ops也就是操作函数。
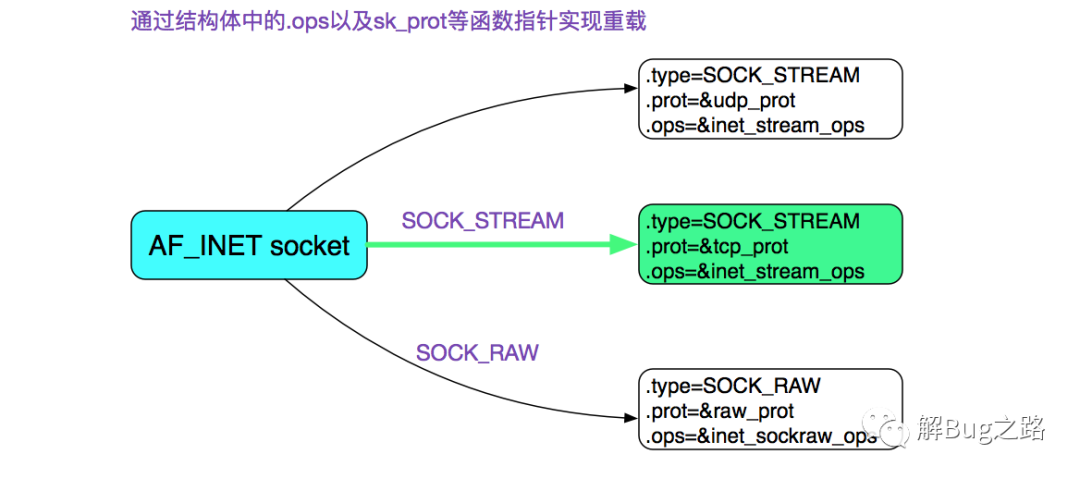
accept系统调用
好了,我们直接进入accept系统调用吧。
#include <sys/socket.h>
// 成功,返回代表新连接的描述符,错误返回-1,同时错误码设置在errno
int accept(int sockfd,struct sockaddr* addr,socklen_t *addrlen);
// 注意,实际上Linux还有个accept扩展accept4:
// 额外添加的flags参数可以为新连接描述符设置O_NONBLOCK|O_CLOEXEC(执行exec后关闭)这两个标记
int accept4(int sockfd, struct sockaddr *addr,socklen_t *addrlen, int flags);
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
注意,这边的accept调用是被glibc用SYSCALL_CANCEL包了一层,其将返回值修正为只有0和-1这两个选择,同时将错误码的绝对值设置在errno内。由于glibc对于系统调用的封装过于复杂,就不在这里细讲了。如果要寻找具体的逻辑,用
// 注意accept和(之间要有空格,不然搜索不到
accept (int
- 1.
- 2.
在整个glibc代码中搜索即可。
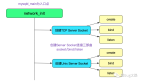
理解accept的关键点是,它会创建一个新的Socket,这个新的Socket来与对端运行connect()的对等Socket进行连接,如下图所示:
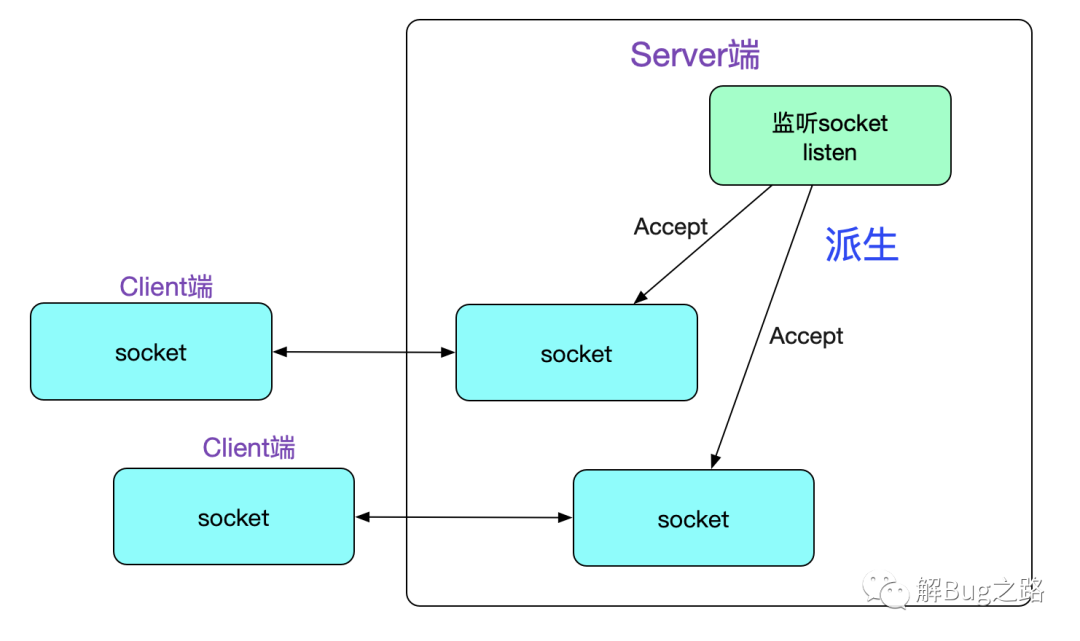
接下来,我们就进入Linux内核源码栈吧
accept
|->SYSCALL_CANCEL(accept......)
......
|->SYSCALL_DEFINE3(accept
// 最终调用了sys_accept4
|->sys_accept4
/* 检测监听描述符fd是否存在,不存在,返回-BADF
|->sockfd_lookup_light
|->sock_alloc /*新建Socket*/
|->get_unused_fd_flags /*获取一个未用的fd*/
|->sock->ops->accept(sock...) /*调用核心*/
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
上述流程如下面所示:
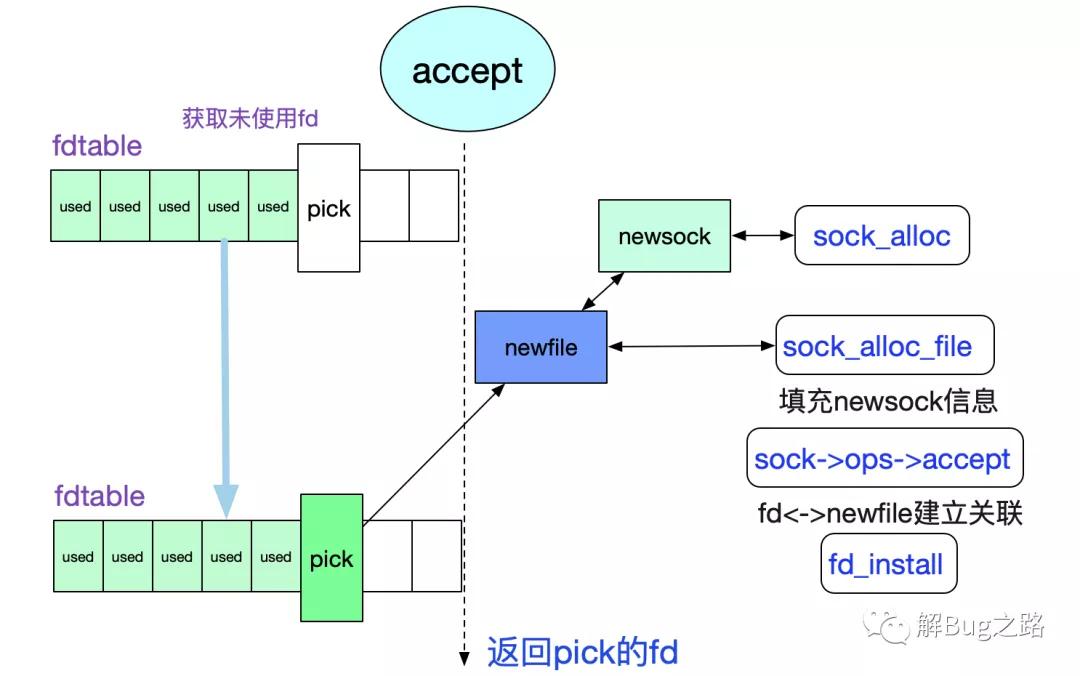
由此得知,核心函数在sock->ops->accept上,由于我们关注的是TCP,那么其实现即为
inet_stream_ops->accept也即inet_accept,再次跟踪下调用栈:
sock->ops->accept
|->inet_steam_ops->accept(inet_accept)
/* 由一开始的sock图可知sk_prot=tcp_prot
|->sk1->sk_prot->accept
|->inet_csk_accept
- 1.
- 2.
- 3.
- 4.
- 5.
好了,穿过了层层包装,终于到具体逻辑部分了。上代码:
struct sock *inet_csk_accept(struct sock *sk, int flags, int *err)
{
struct inet_connection_sock *icsk = inet_csk(sk);
/* 获取当前监听sock的accept队列*/
struct request_sock_queue *queue = &icsk->icsk_accept_queue;
......
/* 如果监听Socket状态非TCP_LISEN,返回错误 */
if (sk->sk_state != TCP_LISTEN)
goto out_err
/* 如果当前accept队列为空 */
if (reqsk_queue_empty(queue)) {
long timeo = sock_rcvtimeo(sk, flags & O_NONBLOCK);
/* 如果是非阻塞模式,直接返回-EAGAIN */
error = -EAGAIN;
if (!timeo)
goto out_err;
/* 如果是阻塞模式,切超时时间不为0,则等待新连接进入队列 */
error = inet_csk_wait_for_connect(sk, timeo);
if (error)
goto out_err;
}
/* 到这里accept queue不为空,从queue中获取一个连接 */
req = reqsk_queue_remove(queue);
newsk = req->sk;
/* fastopen 判断逻辑 */
......
/* 返回新的sock,也就是accept派生出的和client端对等的那个sock */
return newsk
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
上面流程如下图所示:
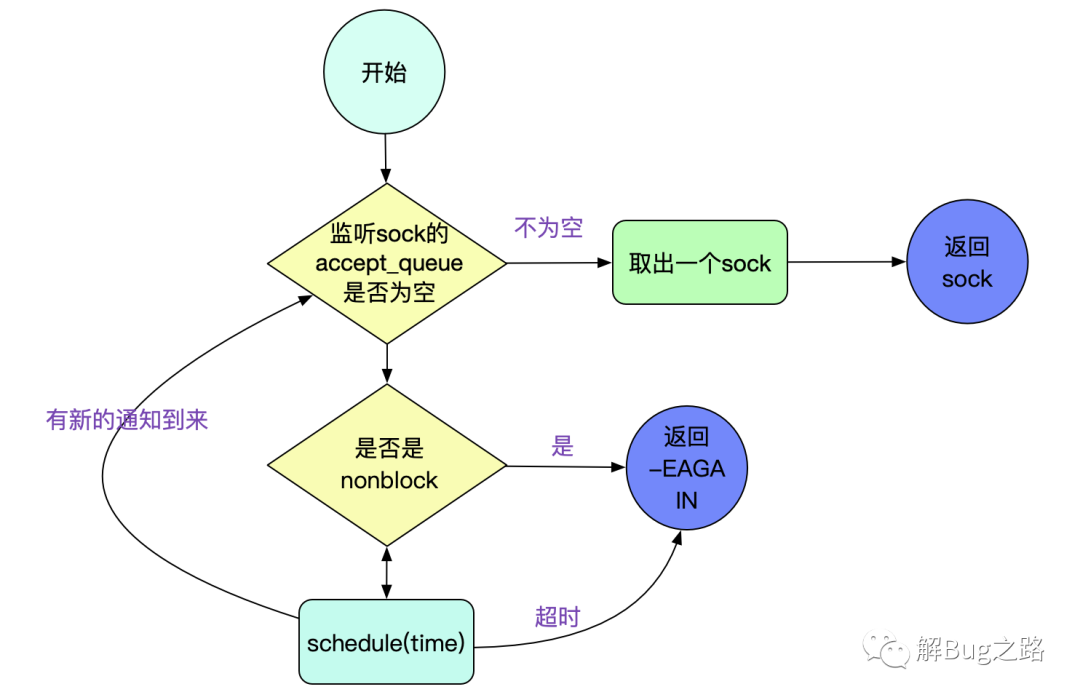
我们关注下inet_csk_wait_for_connect,即accept的超时逻辑:
static int inet_csk_wait_for_connect(struct sock *sk, long timeo)
{
for (;;) {
/* 通过增加EXCLUSIVE标志使得在BIO中调用accept中不会产生惊群效应 */
prepare_to_wait_exclusive(sk_sleep(sk), &wait,
TASK_INTERRUPTIBLE);
if (reqsk_queue_empty(&icsk->icsk_accept_queue))
timeo = schedule_timeout(timeo);
.......
err = -EAGAIN;
/* 这边accept超时,返回的是-EAGAIN */
if (!timeo)
break;
}
finish_wait(sk_sleep(sk), &wait);
return err;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
通过exclusice标志使得我们在BIO中调用accept(不用epoll/select等)时,不会惊群。
由代码得知在accept超时时候返回(errno)的是EAGAIN而不是ETIMEOUT。
EPOLL(在accept时候)”惊群”
由于在EPOLL LT(水平触发模式下),一次accept事件,可能会唤醒多个等待在此listen fd上的(epoll_wait)线程,而最终可能只有一个能成功的获取到新连接(newfd),其它的都是-EGAIN,也即有一些不必要的线程被唤醒了,做了无用功。关于epoll的原理可以看下笔者之前的博客《从linux源码看epoll》:
https://my.oschina.net/alchemystar/blog/3008840
- 1.
在这里描述一下原因,核心就是epoll_wait在水平触发下会在这个fd仍有未处理事件的时候重新塞回ready_list并在此唤醒另一个等待在epoll上的进程!
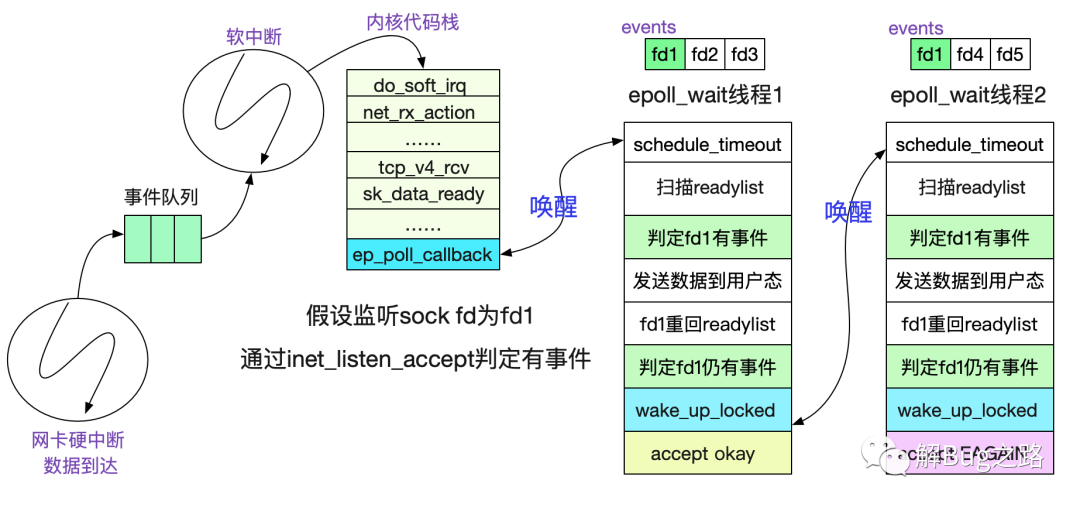
所以我们看到,虽然epoll_wait的时候给自己加了exclusive不会在有中断事件触发的时候惊群,但是水平触发这个机制确也造成了类似”惊群”的现象!
由上面的讨论看出,fd1仍旧有事件是造成额外唤醒的原因,这个也很好理解,毕竟这个事件是另一个线程处理的,那个线程估摸着还没来得及运行,自然也来不及处理!
我们看下在accept事件中,怎么判定这个fd(listen sock的fd)还有未处理事件的。
// 通过f_op->poll判定
epi->ffd.file->f_op->poll
|->tcp_poll
/* 如果sock是listen状态,则由下面函数负责 */
|->inet_csk_listen_poll
/* 通过accept_queue队列是否为空判断监听sock是否有未处理事件*/
static inline unsigned int inet_csk_listen_poll(const struct sock *sk)
{
return !reqsk_queue_empty(&inet_csk(sk)->icsk_accept_queue) ?
(POLLIN | POLLRDNORM) : 0;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
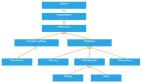
那么我们就可以根据逻辑画出时序图了。
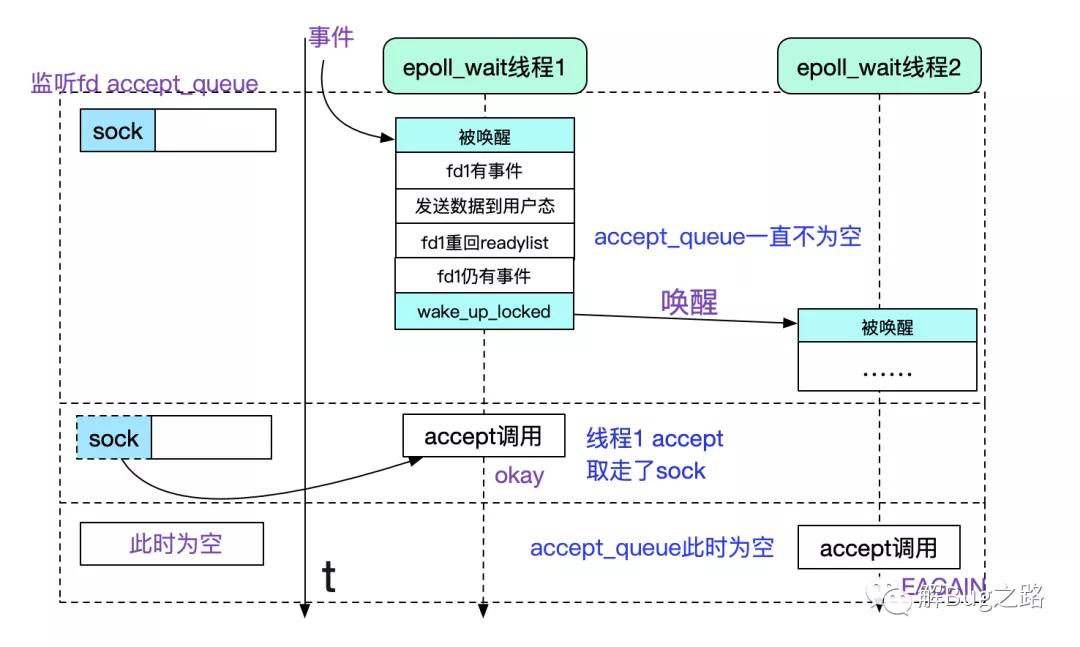
其实不仅仅是accept,要是多线程epoll_wait同一个fd的read/write也是同样的惊群,只不过应该不会有人这么做吧。
正是由于这种”惊群”效应的存在,所以我们经常采用单开一个线程去专门accept的形式,例如reactor模式即是如此。但是,如果一瞬间有大量连接涌进来,单线程处理还是有瓶颈的,无法充分利用多核的优势,在海量短连接场景下就显得稍显无力了。这也是有解决方式的!
采用so_reuseport解决惊群
前面讲过,由于我们是在同一个fd上多线程去运行epoll_wait才会有此问题,那么其实我们多开几个fd就解决了。首先想到的方案是,多开几个端口号,人为分开监听fd,但这个明显带来了额外的复杂性。为了解决这一问题,Linux提供了so_reuseport这个参数,其原理如下图所示:
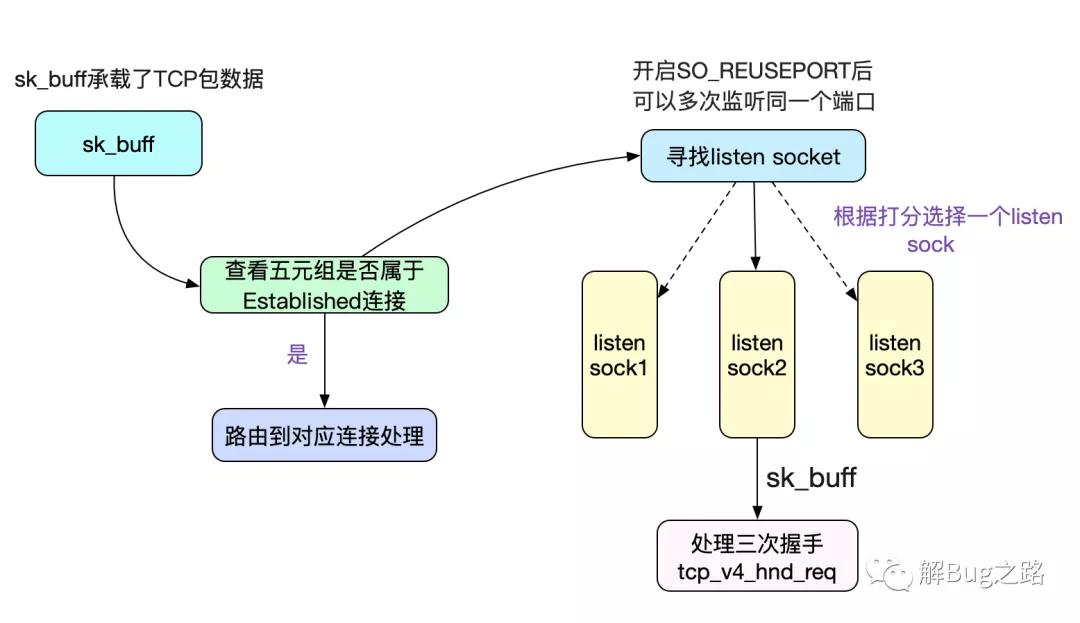
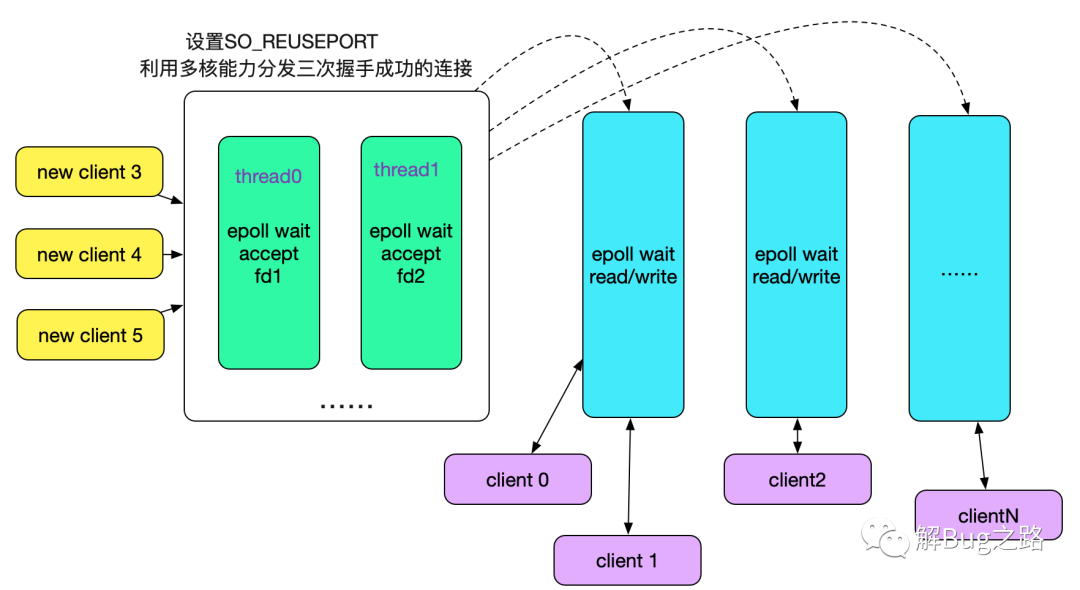
多个fd监听同一个端口号,在内核中做负载均衡(Sharding),将accept的任务分散到不同的线程的不同Socket上(Sharding),毫无疑问可以利用多核能力,大幅提升连接成功后的Socket分发能力。那么我们的线程模型也可以改为用多线程accept了,如下图所示:
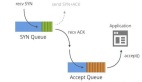
accept_queue全连接队列
在前面的讨论中,accept_queue是accept系统调用中的核心成员,那么这个accept_queue是怎么被填充(add)的呢?如下图所示:
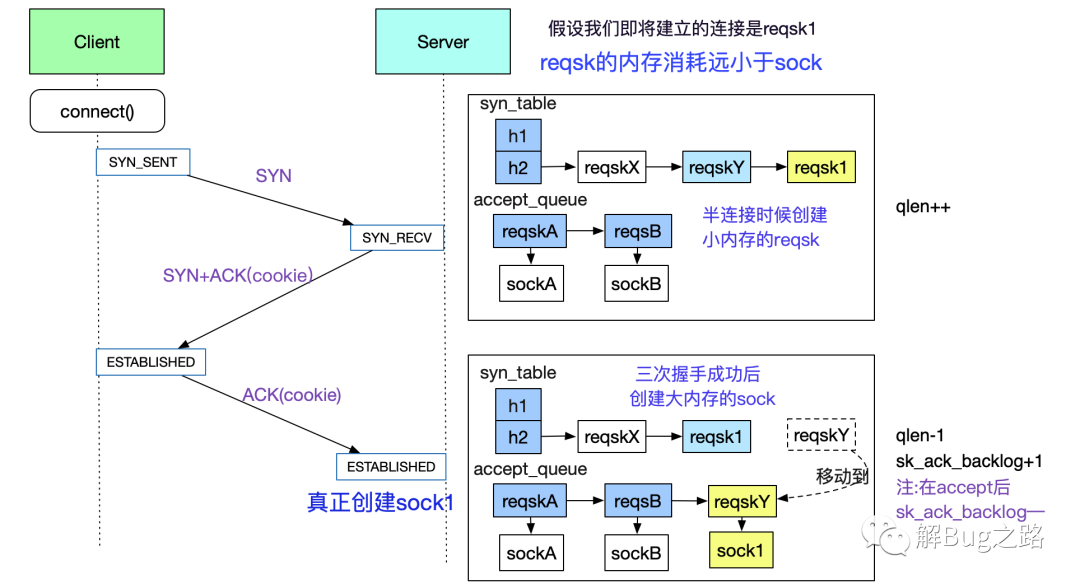
图中展示了client和server在三次交互中,accept_queue(全连接队列)和syn_table半连接hash表的变迁情况。在accept_queue被填充后,由用户线程通过accept系统调用从队列中获取对应的fd
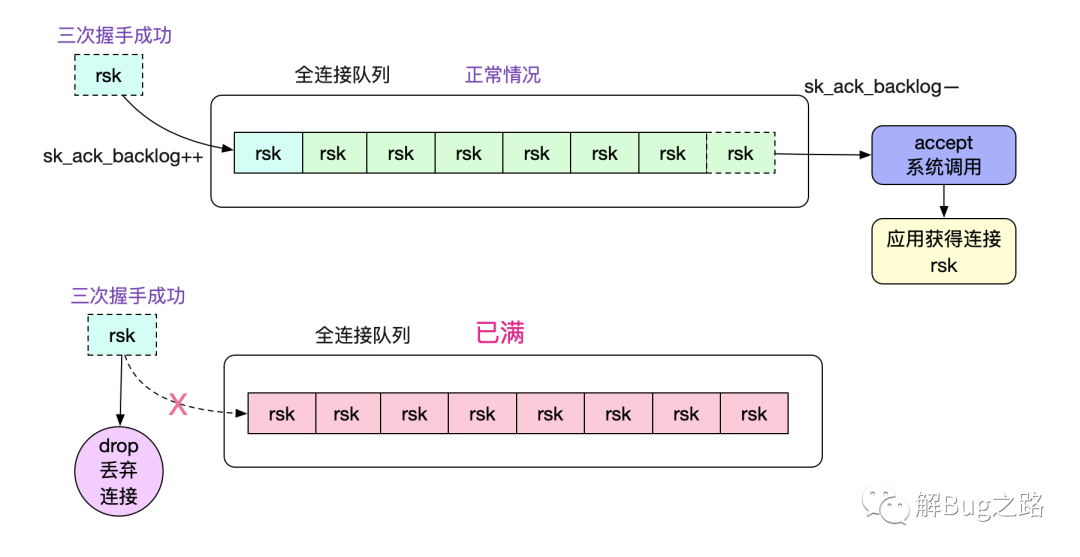
值得注意的是,当用户线程来不及处理的时候,内核会drop掉三次握手成功的连接,导致一些诡异的现象,具体可以看笔者另一篇博客《解Bug之路-dubbo流量上线时的非平滑问题》:
https://my.oschina.net/alchemystar/blog/3098219
- 1.
另外,对于accept_queue具体的填充机制以及源码,可以见笔者另一篇博客的详细分析
《从Linux源码看Socket(TCP)的listen及连接队列》:
https://my.oschina.net/alchemystar/blog/4672630
- 1.
总结
Linux内核源码博大精深,每次扎进去探索时候都会废寝忘食,其间可以看到各种优雅的设计,在此分享出来,希望对读者有所帮助。
本文转载自微信公众号「解Bug之路」,可以通过以下二维码关注。转载本文请联系解Bug之路公众号。