前言
性能优化不管是从方法论还是从实践上都有很多东西,从 C++ 语言本身入手,介绍一些性能优化的方法,希望能做到简洁实用。
实例1
在开始本文的内容之前,让我们看段小程序:
- // 获取一个整数对应10近制的位数
- uint32_t digits10_v1(uint64_t v) {
- uint32_t result = 0;
- do {
- ++result;
- v /= 10;
- } while (v);
- return result;
- }
如果要对这段代码进行优化,你认为瓶颈会是什么呢?代码 -g -O2 后看一眼汇编:
- Dump of assembler code for function digits10_v1(uint64_t):
- 0x00000000004008f0 <digits10_v1(uint64_t)+0>: mov %rdi,%rdx
- 0x00000000004008f3 <digits10_v1(uint64_t)+3>: xor %esi,%esi
- 0x00000000004008f5 <digits10_v1(uint64_t)+5>: mov $0xcccccccccccccccd,%rcx
- 0x00000000004008ff <digits10_v1(uint64_t)+15>: nop
- 0x0000000000400900 <digits10_v1(uint64_t)+16>: mov %rdx,%rax
- 0x0000000000400903 <digits10_v1(uint64_t)+19>: add $0x1,%esi
- 0x0000000000400906 <digits10_v1(uint64_t)+22>: mul %rcx
- 0x0000000000400909 <digits10_v1(uint64_t)+25>: shr $0x3,%rdx
- 0x000000000040090d <digits10_v1(uint64_t)+29>: test %rdx,%rdx
- 0x0000000000400910 <digits10_v1(uint64_t)+32>: jne 0x400900 <digits10_v1(uint64_t)+16>
- 0x0000000000400912 <digits10_v1(uint64_t)+34>: mov %esi,%eax
- 0x0000000000400914 <digits10_v1(uint64_t)+36>: retq
- /*
- 注:对于常数的除法操作,编译器一般会转换成乘法+移位的方式,即
- a / b = a * (1/b) = a * (2^n / b) * (1 / 2^n) = a * (2^n / b) >> n.
- 这里的n=3, b=10, 2^n/b=4/5,0xcccccccccccccccd是编译器对4/5的定点算法表示
- */
指令已经很少了,有多少优化空间呢?先不着急,看看下面这段代码
- uint32_t digits10_v2(uint64_t v) {
- uint32_t result = 1;
- for (;;) {
- if (v < 10) return result;
- if (v < 100) return result + 1;
- if (v < 1000) return result + 2;
- if (v < 10000) return result + 3;
- // Skip ahead by 4 orders of magnitude
- v /= 10000U;
- result += 4;
- }
- }
- uint32_t digits10_v3(uint64_t v) {
- if (v < 10) return 1;
- if (v < 100) return 2;
- if (v < 1000) return 3;
- if (v < 1000000000000) { // 10^12
- if (v < 100000000) { // 10^7
- if (v < 1000000) { // 10^6
- if (v < 10000) return 4;
- return 5 + (v >= 100000); // 10^5
- }
- return 7 + (v >= 10000000); // 10^7
- }
- if (v < 10000000000) { // 10^10
- return 9 + (v >= 1000000000); // 10^9
- }
- return 11 + (v >= 100000000000); // 10^11
- }
- return 12 + digits10_v3(v / 1000000000000); // 10^12
- }
写了一个小程序,digits10_v2 比 digits10_v1 快了 45%, digits10_v3 比digits10_v1 快了60%+。不难看出测试结论跟数据的取值范围相关,就本例来说数值越大,提升越明显。是什么原因呢?附测试程序:
- int main() {
- srand(100);
- uint64_t digit10_array[ITEM_COUNT];
- for( int i = 0; i < ITEM_COUNT; ++i )
- {
- digit10_array[i] = rand();
- }
- struct timeval start, end;
- // digits10_v1
- uint64_t sum1 = 0;
- uint64_t time1 = 0;
- gettimeofday(&start,NULL);
- for( int i = 0; i < RUN_TIMES; ++i )
- {
- sum1 += digits10_v1(digit10_array[i]);
- }
- gettimeofday(&end,NULL);
- time1 = ( end.tv_sec - start.tv_sec ) * 1000 * 1000 + end.tv_usec - start.tv_usec;
- // digits10_v2
- uint64_t sum2 = 0;
- uint64_t time2 = 0;
- gettimeofday(&start,NULL);
- for( int i = 0; i < RUN_TIMES; ++i )
- {
- sum2 += digits10_v2(digit10_array[i]);
- }
- gettimeofday(&end,NULL);
- time2 = ( end.tv_sec - start.tv_sec ) * 1000 * 1000 + end.tv_usec - start.tv_usec;
- // digits10_v3
- uint64_t sum3 = 0;
- uint64_t time3 = 0;
- gettimeofday(&start,NULL);
- for( int i = 0; i < RUN_TIMES; ++i )
- {
- sum3 += digits10_v3(digit10_array[i]);
- }
- gettimeofday(&end,NULL);
- time3 = ( end.tv_sec - start.tv_sec ) * 1000 * 1000 + end.tv_usec - start.tv_usec;
- cout << "sum1:" << sum1 << "\t sum2:" << sum2 << "\t sum3:" << sum3 << endl;
- cout << "cost1:" << time1 << "us\t cost2:" << time2 << "us\t cost3:" << time3 << "us"
- << "\t cost2/cost1:" << (1.0*time2)/time1
- << "\t cost3/cost1:" << (1.0*time3)/time1 << endl;
- return 0;
- }
- /*
执行结果:
- g++ -g -O2 cplusplus_optimize.cpp && ./a.out
- sum1:9944152 sum2:9944152 sum3:9944152
- cost1:27560us cost2:14998us cost3:10525us cost2/cost1:0.544194 cost3/cost1:0.381894
- */
Strength reduction
优化原因不是因为做了循环展开,而是由于不同指令本身的速度就是不一样的,比较、整型的加减、位操作速度都是最快的,而除法/取余却很慢。下面有一个更详细的列表,为了更直观一些,用了clock cycle 来衡量,不过这里的 clock cycle 是个平均值,不同的 CPU 还是稍有差异:
- * comparisons (1 clock cycle)
- * (u)int add, subtract, bitops, shift (1 clock cycle)
- * floating point add, sub (3~6 clock cycle)
- * indexed array access (cache effects)
- * (u)int32 mul (3~4 clock cycle)
- * Floating point mul (4~8 clock cycle)
- * Float Point division, remainder (14~45 clock cycle)
- * (u)int division, remainder (40~80 clock cycle)
虽然大多数场景下,数学运算都不会有太多性能问题,但相对来说,整型的除法运算还是比较昂贵的。编译器就会利用这一特点进行优化,一般称作 Strength reduction.
对于前面的例子,核心原因是 digits10_v2 用比较和加法来减少除法 (/=) 操作,digits10_v3 通过搜索的方式进一步减少了除法操作。由于 cpu 并行处理技术,我们不能简单的用后面的 clock cycle 来衡量性能,但不难看出处理器对类型的还是非常敏感的,以整型和浮点的处理为例:
整型
类型转换
- int--> short/char (0~1 clock cycle)
- int --> float/double (4~16个clock cycle), signed int 快于 unsigned int,唯一一个场景 signed 比 unsigned 快的
- short/char 的计算通常使用 32bit 存储,只是返回的时候做了截取,故只在要考虑内存大小的时候才使用 short/char,如 array
- 注:隐式类型转换可能会溢出,有符号的溢出变成负数,无符号的溢出变成小的整数
运算
- 除法、取余运算unsigned int 快于 signed int
- 除以常量比除以变量效率高,因为可以在编译期做优化,尤其是常量可以表示成2^n时
- ++i和i++本身性能一样,但不同的语境效果不一样,如array[i++]比arry[++i]性能好;当依赖自增结果时,++i性能更好,如a=++b,a和b可复用同一个寄存器
代码示例
- // div和mod效率
- int a, b, c;
- a = b / c; // This is slow
- a = b / 10; // Division by a constant is faster
- a = (unsigned int)b / 10; // Still faster if unsigned
- a = b / 16; // Faster if divisor is a power of 2
- a = (unsigned int)b / 16; // Still faster if unsigned
浮点
- 单精度、双精度的计算性能是一样的
- 常量的默认精度是双精度
- 不要混淆单精度、双精度,混合精度计算会带来额外的精度转换开销,如
- // 混用
- float a, b;
- a = b * 1.2; // bad. 先将b转换成double,返回结果转回成float
- // Example 14.18b
- float a, b;
- a = b * 1.2f; // ok. everything is float
- // Example 14.18c
- double a, b;
- a = b * 1.2; // ok. everything is double
- 浮点除法比乘法慢很多,故可以利用乘法来加快速度,如:
- double y, a1, a2, b1, b2;
- y = a1/b1 + a2/b2; // slow
- double y, a1, a2, b1, b2;
- y = (a1*b2 + a2*b1) / (b1*b2); // faster
这里介绍的大多是编译器的擅长但又不能直接优化的场景,也是平常优化中比较容易忽视的点,其实往往我们往前多走一步,编译器就可以工作得更好。
实例2
先看一个数字转字符串的例子,stringstream 和 sprintf 自然不会是我们考虑的对象,虽然 protobuf 库中的 FastInt32ToBuffer 很不错,其实还能优化,下面的版本就比例子中 stringstream 快 6 倍,代码如下:
- // integer to string
- uint32_t u64ToAscii_v1(uint64_t value, char* dst) {
- // Write backwards.
- char* start = dst;
- do {
- *dst++ = '0' + (value % 10);
- value /= 10;
- } while (value != 0);
- const uint32_t result = dst - start;
- // Reverse in place.
- for (dst--; dst > start; start++, dst--) {
- std::iter_swap(dst, start);
- }
- return result;
- }
不用细读 stringstream/sprintf 的源码,反汇编看下就能知道个大概,对于转字符串这个场景,stringstream/sprintf 就太重了,通常来说越少的指令性能也越好,本文讨论的重点是内存访问,就上面这段代码,有什么内存使用上的问题?如何进一步优化?
分析
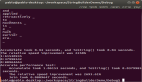
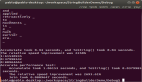
优化前还是得找一下性能热点,下面是 vtune 结果的截图(虽然 cpu time 和汇编指令的消耗对应得不是特别好):
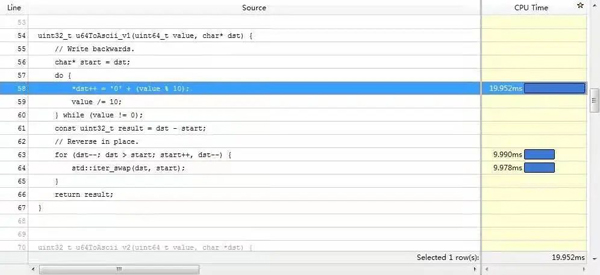
vtune_1
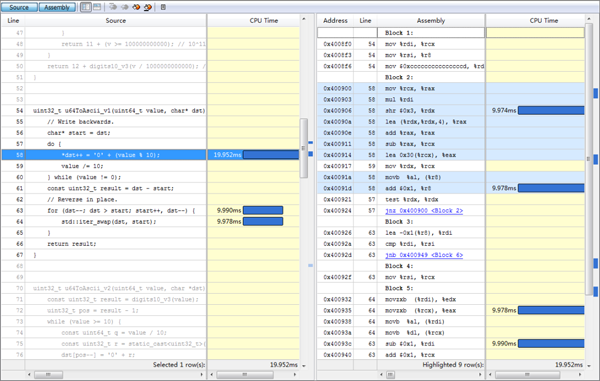
vtune_2
数组 reverse 的开销跟上面生成数组元素相近,reverse有这么耗时么?
从图中的汇编可以看出,一次 swap 对应着两次内存读 (movzxb)、两次内存写 (movb),因为一次写就意味着一个读和一个写,描述的是内存-->cache-->内存的过程。
优化
减少内存写操作 一个很自然的优化想法,应该尽量避免内存写操作,于是代码可以进一步优化,结合 Strength reduction,代码如下:
- uint32_t u64ToAscii_v2(uint64_t value, char *dst) {
- const uint32_t result = digits10_v3(value);
- uint32_t pos = result - 1;
- while (value >= 10) {
- const uint64_t q = value / 10;
- const uint32_t r = static_cast<uint32_t>(value % 10);
- dst[pos--] = '0' + r;
- value = q;
- }
- *dst = static_cast<uint32_t>(value) + '0';
- return result;
- }
实测发现新版本比之前版本性能提升了 10%,还有优化空间么?答案是,有。方案是:通过查表,一次处理2个数字,减少数据依赖,如:
- uint32_t u64ToAscii_v3(uint64_t value, char* dst) {
- static const char digits[] =
- "0001020304050607080910111213141516171819"
- "2021222324252627282930313233343536373839"
- "4041424344454647484950515253545556575859"
- "6061626364656667686970717273747576777879"
- "8081828384858687888990919293949596979899";
- const size_t length = digits10_v3(value);
- uint32_t next = length - 1;
- while (value >= 100) {
- const uint32_t i = (value % 100) * 2;
- value /= 100;
- dst[next - 1] = digits[i];
- dst[next] = digits[i + 1];
- next -= 2;
- }
- // Handle last 1-2 digits
- if (value < 10) {
- dst[next] = '0' + uint32_t(value);
- } else {
- uint32_t i = uint32_t(value) * 2;
- dst[next - 1] = digits[i];
- dst[next] = digits[i + 1];
- }
- return length;
- }
结论:
- u64ToAscii_v3性能比基准版本提升了30%;
- 如果用到悟时的那个测试场景,性能可以提升6.5倍。
下面是完整的测试代码和结果:
- #include <sys/time.h>
- #include <iostream>
- #define ITEM_COUNT 1024*1024
- #define RUN_TIMES 1024*1024
- #define BUFFERSIZE 32
- using namespace std;
- uint32_t digits10_v1(uint64_t v) {
- uint32_t result = 0;
- do {
- ++result;
- v /= 10;
- } while (v);
- return result;
- }
- uint32_t digits10_v2(uint64_t v) {
- uint32_t result = 1;
- for(;;) {
- if (v < 10) return result;
- if (v < 100) return result + 1;
- if (v < 1000) return result + 2;
- if (v < 10000) return result + 3;
- v /= 10000U;
- result += 4;
- }
- return result;
- }
- uint32_t digits10_v3(uint64_t v) {
- if (v < 10) return 1;
- if (v < 100) return 2;
- if (v < 1000) return 3;
- if (v < 1000000000000) { // 10^12
- if (v < 100000000) { // 10^7
- if (v < 1000000) { // 10^6
- if (v < 10000) return 4;
- return 5 + (v >= 100000); // 10^5
- }
- return 7 + (v >= 10000000); // 10^7
- }
- if (v < 10000000000) { // 10^10
- return 9 + (v >= 1000000000); // 10^9
- }
- return 11 + (v >= 100000000000); // 10^11
- }
- return 12 + digits10_v3(v / 1000000000000); // 10^12
- }
- uint32_t u64ToAscii_v1(uint64_t value, char* dst) {
- // Write backwards.
- char* start = dst;
- do {
- *dst++ = '0' + (value % 10);
- value /= 10;
- } while (value != 0);
- const uint32_t result = dst - start;
- // Reverse in place.
- for (dst--; dst > start; start++, dst--) {
- std::iter_swap(dst, start);
- }
- return result;
- }
- uint32_t u64ToAscii_v2(uint64_t value, char *dst) {
- const uint32_t result = digits10_v3(value);
- uint32_t pos = result - 1;
- while (value >= 10) {
- const uint64_t q = value / 10;
- const uint32_t r = static_cast<uint32_t>(value % 10);
- dst[pos--] = '0' + r;
- value = q;
- }
- *dst = static_cast<uint32_t>(value) + '0';
- return result;
- }
- uint32_t u64ToAscii_v3(uint64_t value, char* dst) {
- static const char digits[] =
- "0001020304050607080910111213141516171819"
- "2021222324252627282930313233343536373839"
- "4041424344454647484950515253545556575859"
- "6061626364656667686970717273747576777879"
- "8081828384858687888990919293949596979899";
- const size_t length = digits10_v3(value);
- uint32_t next = length - 1;
- while (value >= 100) {
- const uint32_t i = (value % 100) * 2;
- value /= 100;
- dst[next - 1] = digits[i];
- dst[next] = digits[i + 1];
- next -= 2;
- }
- // Handle last 1-2 digits
- if (value < 10) {
- dst[next] = '0' + uint32_t(value);
- } else {
- uint32_t i = uint32_t(value) * 2;
- dst[next - 1] = digits[i];
- dst[next] = digits[i + 1];
- }
- return length;
- }
- int main() {
- srand(100);
- uint64_t digit10_array[ITEM_COUNT];
- for( int i = 0; i < ITEM_COUNT; ++i )
- {
- digit10_array[i] = rand();
- }
- char buffer[BUFFERSIZE];
- struct timeval start, end;
- // digits10_v1
- uint64_t sum1 = 0;
- uint64_t time1 = 0;
- gettimeofday(&start,NULL);
- for( int i = 0; i < RUN_TIMES; ++i )
- {
- sum1 += u64ToAscii_v1(digit10_array[i], buffer);
- }
- gettimeofday(&end,NULL);
- time1 = ( end.tv_sec - start.tv_sec ) * 1000 * 1000 + end.tv_usec - start.tv_usec;
- // digits10_v2
- uint64_t sum2 = 0;
- uint64_t time2 = 0;
- gettimeofday(&start,NULL);
- for( int i = 0; i < RUN_TIMES; ++i )
- {
- sum2 += u64ToAscii_v2(digit10_array[i], buffer);
- }
- gettimeofday(&end,NULL);
- time2 = ( end.tv_sec - start.tv_sec ) * 1000 * 1000 + end.tv_usec - start.tv_usec;
- // digits10_v3
- uint64_t sum3 = 0;
- uint64_t time3 = 0;
- gettimeofday(&start,NULL);
- for( int i = 0; i < RUN_TIMES; ++i )
- {
- sum3 += u64ToAscii_v3(digit10_array[i], buffer);
- }
- gettimeofday(&end,NULL);
- time3 = ( end.tv_sec - start.tv_sec ) * 1000 * 1000 + end.tv_usec - start.tv_usec;
- cout << "sum1:" << sum1 << "\t sum2:" << sum2 << "\t sum3:" << sum3 << endl;
- cout << "cost1:" << time1 << "us\t cost2:" << time2 << "us\t cost3:" << time3 << "us"
- << "\t cost2/cost1:" << (1.0*time2)/time1
- << "\t cost3/cost1:" << (1.0*time3)/time1 << endl;
- return 0;
- }
- /* 测试结果
- g++ -g -O2 cplusplus_optimize.cpp -o cplusplus_optimize && ./cplusplus_optimize
- sum1:9944152 sum2:9944152 sum3:9944152
- cost1:47305us cost2:42448us cost3:31657us cost2/cost1:0.897326 cost3/cost1:0.66921
- */
看到优化写内存操作的威力了吧,让我们再看一个减少写操作的例子:
- struct Bitfield {
- int a:4;
- int b:2;
- int c:2;
- };
- Bitfield x;
- int A, B, C;
- x.a = A;
- x.b = B;
- x.c = C;
假定 A、B、C 都很小,且不会溢出,可以写成
- union Bitfield {
- struct {
- int a:4;
- int b:2;
- int c:2;
- };
- char abc;
- };
- Bitfield x;
- int A, B, C;
- x.abc = A | (B << 4) | (C << 6);
如果需要考虑溢出,也可以改为
- x.abc = (A & 0x0F) | ((B & 3) << 4) | ((C & 3) <<6 );
读取效率
对于内存的写,最好的办法就是减少写的次数,那么内存的读取呢?教科书的答案是:尽可能顺序访问内存。理解这句话还是得从 cache line 开始,因为实际的 cpu 比较复杂,下面的表述尝试做些简化,如有问题,欢迎指正:
cache line
- 假设 L1cache 大小为 8K,cache line 64 字节、4way,那么整个 cache 会分成32 个集合, 81024/64=128=324,一个内存地址进入哪个 cache line 不是任意的,而是确定在某个集合中,可以通过公式 (set ) = (memory address) / ( line size) % (number of sets )来计算,如地址是 10000,则(set)=10000/64%32 = 28, 即编号为28的集合内的4个 cache line 之一。
- 用 16 进制来描述,10000=0x2710 ,一次内存读取是 64bytes,那么访问内存地址 10000 即意味着地址 0x2700~0x273F 都进集合编号为 28(0x1C) 的 cache line 中了。
cache miss
可以看出,顺序的访问内存是能够比较高效而且不会因为 cache 冲突,导致药频繁读取内存。那什么的情况会导致 cache miss 呢?
- 当某个集合内的 cache line 都有数据时,且该集合内有新的数据就会导致老数据的换出,进而访问老数据就会出现 cache miss。
- 以先后读取 0x2710, 0x2F00, 0x3700, 0x3F00, 0x4700 为例, 这几个地址都在 28 这个编号的集合内,当去读 0x4700 时,假定 CPU 都是以先进先出策略,那么 0x2710 就会被换出,这时候如果再访问 0x2700~0x273F 的数据就 cache miss,需要重新访问内存了。
- 可以看出变量是否有 cache 竞争,得看变量地址间的距离,distance = (number of sets ) (line size) = ( total cache size) / ( number of ways) , 即距离为3264 = 8K/4= 2K的内存访问都可能产生竞争。
- 上面这些不光对变量、对象有用,对代码 cache 也是如此。
建议
对于内存的访问,可以考虑以下一些建议:
- 一起使用的函数存储在一起。函数的存储通常按照源码中的顺序来的,如果函数A,B,C是一起调用的,那尽量让ABC的声明也是这个顺序
- 一起使用的变量存储在一起。使用结构体、对象来定义变量,并通过局部变量方式来声明,都是一些较好的选择。例子见后文:
- 合理使用对齐(attribute((aligned(64)))、预取(prefecting data),让一个cacheline能获取到更多有效的数据
- 动态内存分配、STL容器、string都是一些常容易cache不友好的场景,核心代码处尽量不用
- int Func(int);
- const int size = 1024;
- int a[size], b[size], i;
- ...
- for (i = 0; i < size; i++) {
- b[i] = Func(a[i]);
- }
- // pack a,b to Sab
- int Func(int);
- const int size = 1024;
- struct Sab {int a; int b;};
- Sab ab[size];
- int i;
- ...
- for (i = 0; i < size; i++) {
- ab[i].b = Func(ab[i].a);
- }
静态变量
让我们再回到最前面的优化,u64ToAscii_v3 引入了局部静态变量 (digits),是否合适?通常来说,要具体问题具体分析,没有标准答案。
静态变量和栈地址是分开的,可能会带来 cache miss 的问题,通过去掉 static 修饰符,直接在栈上声明变的方式可以避免,但这种做法可行有几个前提条件:
- 变量大小是要限制的,不超出cache的大小(最好是L1 cache)
- 变量的初始化在栈上完成,故最好不要在循环内部定义,以避免不必要的初始化。
其实内存访问和 CPU 运算是没有一定的赢家,真正做优化时,需要结合具体的场景,仔细测量才能得到答案。
回顾
前面两个实例分别从编译器和内存使用的角度介绍了一些性能优化的方法,后面内容则会回到cpu,从指令并行的角度看看我们常见的逻辑控制有哪些可以优化的点。
从原理上来说,这个系列的优化不是特别区分语言,只是这里我们用C++来描述。
流水线
通常一个 CPU 可以并行执行多条指令,如:4 条浮点乘法,等待 4 个内存访问、一个还为到来的分支比较,不同的运算单元也是可以并行计算,如 for(int i = 0; i < N; ++i) a[i]=0.2; 这里的 i < N 和 ++i 在 a[i]=0.2 可以同时执行。提升指令并行能力,往往就能达到提升性能的目的。
从流水线的角度看,指令 pipeline 的几个阶段:fetch、decode、execute、memory-access、write-back,除了存储器的访问效率会影响并行度外,下一条指令的 fetch/decode 也很关键,而跳转和分支则是又一个拦路虎,这也是本文接下去要主要分析的地方。
函数
本身开销
- 函数调用使得处理器跳到另外一个代码地址并回来,一般需要4 clock cycles,大多数情况处理器会把函数调用、返回和其他指令一起执行以节约时间。
- 函数参数存储在栈上需要额外的时间( 包括栈帧的建立、saving and restoring registers、可能还有异常信息)。在64bit linux上,前6个整型参数(包括指针、引用)、前8个浮点参数会放到寄存器中;64bit windows上不管整型、浮点,会放置4个参数。
- 在内存中过于分散的代码可能会导致较差的code cache
常见的优化手段
- 避免不必要的函数,特别在最底层的循环,应该尽量让代码在一个函数内。看起来与良好的编码习惯冲突(一个函数最好不要超过80行),其实不然,跟这个系列其他优化一样,我们应该知道何时去使用这些优化,而不是一上来就让代码不可读。
- 尝试使用inline函数,让函数调用的地方直接用函数体替换。inline对编译器来说是个建议,而且不是inline了性能就好,一般当函数比较小或者只有一个地方调用的时候,inline效果会比较好
- 在函数内部使用循环(e.g., change for(i=0;i<100;i++) DoSomething(); into DoSomething() { for(i=0;i<100;i++) { ... } } )
- 减少函数的间接调用,如偏向静态链接而不是动态链接,尽量少用或者不用多继承、虚拟继承
- 优先使用迭代而不是递归
- 使用函数来替换define,从而避免多次求值。宏的其他缺点:不能overload和限制作用域(undef除外)
- // Use macro as inline function
- #define MAX(a,b) ((a) > (b) ? (a) : (b))
- y = MAX(f(x), g(x));
- // Replace macro by template
- template <typename T>
- static inline T max(T const & a, T const & b) {
- return a > b ? a : b;
- }
分支预测
应用场景
常见的分支预测场景有 if/else,for/while,switch,预测正确 0~2 clock cycles,错误恢复 12~25 clock cycles。
一般应用分支预测的正确率在90%以上,但个位数的误判率对有较多分支的程序来说影响还是非常大的。分支预测的技术(或者说策略)非常多,这里不会展开介绍,对写程序来说,我们知道越简单的场景越容易预测正确:如分支都在在一个循环内或者几乎没有其他分支。
关键因素
如果对分支预测的概念和作用还不清楚的话,可以看看后面的参考文档。几个影响分支预测因素:
branch target buffer (BTB)
- 分支预测的结果存储一个特殊的cache,该cache是个固定大小的hashtable,通过$pc可以计算出预测结果地址
- 在指令fetch阶段访问,使得分支目标地址在IF阶段就可以读取.预测不正确时更新预测结果
Return Address Stack (RAS)
- 固定大小,操作方式跟stack结构一样,内容是函数返回值地址($pc+4), 使用BTB存储
- 间接的跳转不便于预测,如依赖寄存器、内存地址,好在绝大多数间接的跳转都来自函数返回
- 函数返回地址预测使用BTB,如果关键部分的函数和分支较多,会引起BTB的竞争,进而影响分支命中率
常见的优化手段
1. 消除条件分支
- 代码实例
- if (a < b) {
- r = c;
- } else {
- r = d;
- }
- 优化版本1
- int mask = (a-b) >> 31;
- r = (mask & c) | (~mask & d);
- 优化版本2
- int mask = (a-b) >> 31;
- r = d + mask & (c-d);
- 优化版本3
- // cmovg版本
- r = (a < b) ?c : d;
bool 类型变换
- 实例代码
- bool a, b, c, d;
- c = a && b;
- d = a || b;
- 编译器的行为是
- bool a, b, c, d;
- if (a != 0) {
- if (b != 0) {
- c = 1;
- }
- else {
- goto CFALSE;
- }
- }
- else {
- CFALSE:
- c = 0;
- }
- if (a == 0) {
- if (b == 0) {
- d = 0;
- }
- else {
- goto DTRUE;
- }
- }
- else {
- DTRUE:
- d = 1;
- }
- 优化版本
- char a = 0, b = 0, c, d;
- c = a & b;
- d = a | b;
- 实例代码2
- bool a, b;
- b = !a;
- // 优化成
- char a = 0, b;
- b = a ^ 1;
- 反例
a && b 何时不能转换成 a & b,当 a 不可能为 false 的情况下
a | | b 何时不能转换成 a | b,当 a 不可能为 true 的情况下
2. 循环展开
- 实例代码
- int i;
- for (i = 0; i < 20; i++) {
- if (i % 2 == 0) {
- FuncA(i);
- }
- else {
- FuncB(i);
- }
- FuncC(i);
- }
- 优化版本
- int i;
- for (i = 0; i < 20; i += 2) {
- FuncA(i);
- FuncC(i);
- FuncB(i+1);
- Func
C(i+1); }
- 优化说明
- 优点:减少比较次数、某些CPU上重复次数越少预测越准、去掉了if判断
- 缺点:需要更多的code cache or micro-op cache、有些处理器(core 2)对于小循环性能很好(小于65bytes code)、循环的次数和展开的个数不匹配
- 一般编译器会自动展开循环,程序员不需要主动去做,除非有一些明显优点,比如减少上面的if判断
3. 边界检查
- 实例代码1
- const int size = 16; int i;
- float list[size];
- ...
- if (i < 0 || i >= size) {
- cout << "Error: Index out of range";
- }
- else {
- list[i] += 1.0f;
- }
- // 优化版本
- if ((unsigned int)i >= (unsigned int)size) {
- cout << "Error: Index out of range";
- }else {
- list[i] += 1.0f;
- }
- 实例代码2
- const int min = 100, max = 110; int i;
- ...
- if (i >= min && i <= max) { ...
- //优化版本
- if ((unsigned int)(i - min) <= (unsigned int)(max - min)) { ...
4. 使用数组
- 实例代码1
- float a; int b;
- a = (b == 0) ? 1.0f : 2.5f;
- // 使用静态数组
- float a; int b;
- static const float OneOrTwo5[2] = {1.0f, 2.5f};
- a = OneOrTwo5[b & 1];
- 实例代码2
- // 数组的长度是2的幂
- float list[16]; int i;
- ...
- list[i & 15] += 1.0f;
5. 整形的 bit array 语义,适用于 enum、const、define
- enum Weekdays {
- Sunday, Monday, Tuesday, Wednesday, Thursday, Friday, Saturday
- };
- Weekdays Day;
- if (Day == Tuesday || Day == Wednesday || Day == Friday) {
- DoThisThreeTimesAWeek();
- }
- // 优化版本 using &
- enum Weekdays {
- Sunday = 1, Monday = 2, Tuesday = 4, Wednesday = 8,
- Thursday = 0x10, Friday = 0x20, Saturday = 0x40
- };
- Weekdays Day;
- if (Day & (Tuesday | Wednesday | Friday)) {
- DoThisThreeTimesAWeek();
- }
本块小结
- 尽可能的减少跳转和分支
- 优先使用迭代而不是递归
- 对于长的if...else,使用switch case,以减少后面条件的判断,把最容易出现的条件放在最前面
- 为小函数使用inline,减少函数调用开销
- 在函数内使用循环
- 在跳转之间的代码尽量减少数据依赖
- 尝试展开循环
- 尝试通过计算来消除分支