














本文转载自微信公众号「志斌的python笔记」,作者志斌 。转载本文请联系志斌的python笔记公众号。
大家好,我是志斌~
今天志斌来给大家分享一下如何破解文本混淆反爬虫中的图片伪装反爬虫~
01定义
现在许多大型网站的反爬虫方式是将图片与文字混合在一起,放到页面上进行展示。这种混合展示的方式并不会影响用户的正常阅读,但是却可以限制爬虫程序获取这些内容。如下图:
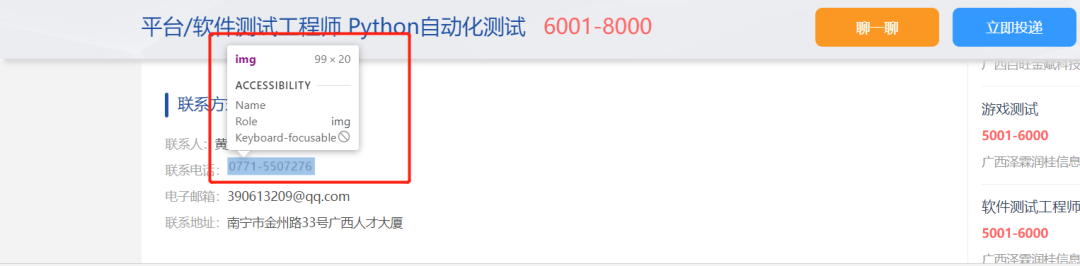
02原理
这种反爬虫的原理十分简单,就是将本应是普通文本内容的部分在前端页面中用图片来进行替换,从而达到“鱼目混珠“的效果。
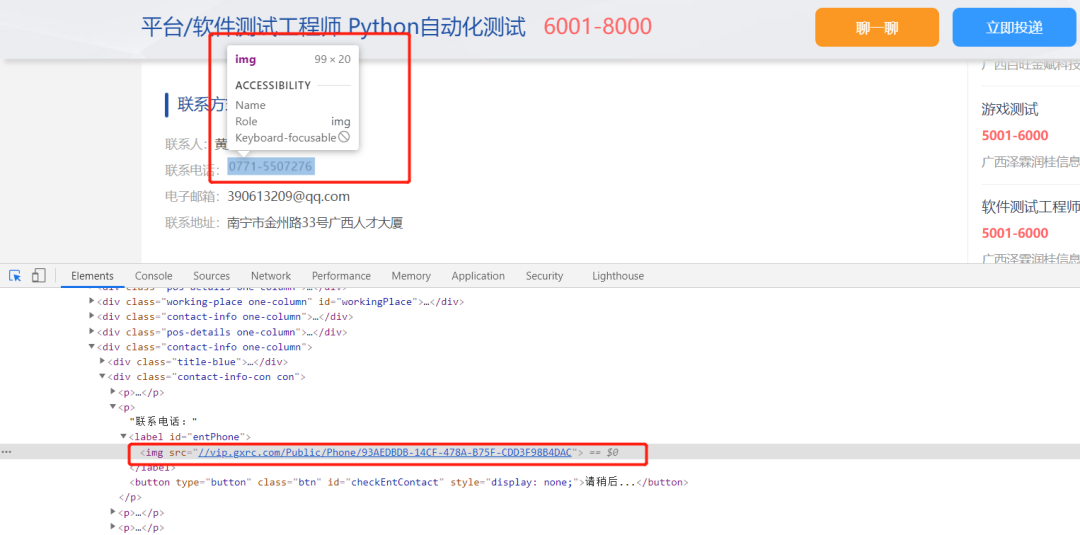
03破解
因为这种反爬虫方式是将内容进行替换,所以我们无法进行绕过,只能破解它来获取我们想要的内容。
破解的方法也比较简单,我们只需要将图片下载下来然后对里面的内容进行提取即可。提取图片中的文字有很多方式,我用的是百度AI来进行提取。代码如下:
- from aip import AipOcr
- APP_ID = '你的APPID'
- API_KEY = 'API Key'
- SECRET_KEY = '你的Secret Key'
- client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
- with open(img,'rb') as f:
- image = f.read()
- word = client.basicGeneral(image)
在之前的文章中我分享过一个用百度api进行提取图片中内容的方式,有兴趣的读者可以看看这篇文章20行代码教你如何批量提取图片中文字。
04小结
1. 图片伪装反爬虫的本质就是用图片替换了原来的内容,从而让爬虫程序无法正常获取,我们只要将里面的内容识别、提取出来就可以破解这种反爬虫。
2. 破解这种反爬虫的难度并不大,但是代码书写可能较为繁琐,读者们可以提前写好流程图,然后在进行书写。
3. 目前这种反爬虫方法已经被各类大型网站所应用,所以大家要掌握这种反爬虫的绕过方法。
4. 本文旨在学习与研究图片伪装反爬虫,请大家不要用于非法用途。
















