












在上一篇文章《CPU进化论:复杂指令集》中我们从历史的角度讲述了复杂指令集出现的必然,随着时间的推移,采用复杂指令集架构的CPU出现各种各样的问题,面对这些问题一部分人开始重新思考指令集到底该如何设计。
在这一时期,两个趋势的出现促成一种新的指令集设计思想。
内存与编译器
时间来到了1980s年代,此时容量“高达”64K的内存开始出现,内存容量上终于不再捉襟见肘,价格也开始急速下降,在1977年,1MB内存的价格高达$5000,要知道这可是1977年的5000刀,但到了1994年,1MB内存价格就急速下降到大概只有$6,这是第一个趋势。
此外在这一时期随着编译技术的进步,编译器越来越成熟,渐渐的程序员们开始依靠编译器来生成汇编指令而不再自己手工编写。
这两个趋势的出现让人们有了更多思考。
化繁为简
19世纪末20世纪初意大利经济学家Pareto发现,在任何一组东西中,最重要的只占其中一小部分,约20%,其余80%尽管是多数,却是次要的,这就是著名的二八定律,机器指令的执行频率也有类似的规律。
大概80%的时间CPU都在执行那20%的机器指令,同时CISC中一部分比较复杂的指令并不怎么被经常用到,而且那些设计编译器的程序员也更倾向于组合一些简单的指令来完成特定任务。
与此同时我们在上文提到过的一位计算机科学家,被派去改善微代码设计,但后来这老哥发现有问题的是微代码本身,因此开始转过头来去思考微代码这种设计的问题在哪里。
他的早期工作提出一个关键点,复杂指令集中那些被认为可以提高性能的指令其实在内部被微代码拖后腿了,如果移除掉微代码,程序反而可以运行的更快,并且可以节省构造CPU消耗的晶体管数量。
由于微代码的设计思想是将复杂机器指令在CPU内部转为相对简单的机器指令,这一过程对编译器不可见,也就是说你没有办法通过编译器去影响CPU内部的微代码运行行为,因此如果微代码出现bug那么编译器是无能为力的,你没有办法通过编译器生成其它机器指令来修复问题而只能去修改微代码本身。
此外他还发现,有时一些复杂的机器指令执行起来要比等价的多个简单指令要。
这一切都在提示:为什么不直接用一些简单到指令来替换掉那些复杂的指令呢?
精简指令集哲学
基于对复杂指令集的思考,精简指令集哲学诞生了,精简指令集主要体现在以下三个方面:
1,指令本身的复杂度
精简指令集的思想其实很简单,干嘛要去死磕复杂的指令,去掉复杂指令代之以一些简单的指令。
有了简单指令CPU内部的微代码也不需要了,没有了微代码这层中间抽象,编译器生成的机器指令对CPU的控制力大大增强,有什么问题让写编译器的那帮家伙修复就好了,显然调试编译器这种软件要比调试CPU这种硬件要简单很多。
注意,精简指令集思想不是说指令集中指令的数量变少,而是说一条指令背后代表的动作更简单了。
举个简单的例子,复杂指令集中的一条指令背后代表的含义是“吃饭”的全部过程,而精简指令集中的一条指令仅仅表示“咀嚼一下”的其中一个小步骤。
博主在《你管这破玩意叫编程语言》一文中举得例子其实更形象一些,复杂指令集下一条指令可以表示“给我端杯水”,而在精简指令集下你需要这样表示:

2,编译器
精简指令集的另一个特点就是编译器对CPU的控制力更强。
在复杂指令集下,CPU会对编译器隐藏机器指令的执行细节,就像微代码一样,编译器对此无能为力。
而在精简指令集下CPU内部的操作细节暴露给编译器,编译器可以对其进行控制,也因此,精简指令集RISC还有一个有趣的称呼:“Relegate Interesting Stuff to Compiler”,把一些有趣的玩意儿让编译器来完成。
3,load/store architecture
在复杂指令集下,一条机器指令可能涉及到从内存中取出数据、执行一些操作比如加和、然后再把执行结果写回到内存中,注意这是在一条机器指令下完成的。
但在精简指令集下,这绝对是大写的禁忌,精简指令集下的指令只能操作寄存器中的数据,不可以直接操作内存中的数据,也就是说这些指令比如加法指令不会去访问内存。

毕竟数据还是存放在内存中的,那么谁来读写内存呢?
原来在精简指令集下有专用的 load 和 store 两条机器指令来负责内存的读写,其它指令只能操作CPU内部的寄存器,这是和复杂指令集一个很鲜明的区别。
你可能会好奇,用两条专用的指令来读写内存有什么好处吗?别着急,在本文后半部分我们还会回到load/store指令。
以上就是三点就是精简指令集的设计哲学。
接下来我们用一个例子来看下RISC和CISC的区别。
两数相乘
如图所示就是最经典的计算模型,最右边是内存,存放机器指令和数据,最左侧是CPU,CPU内部是寄存器和计算单元ALU,进一步了解CPU请参考《你管这破玩意叫CPU?》
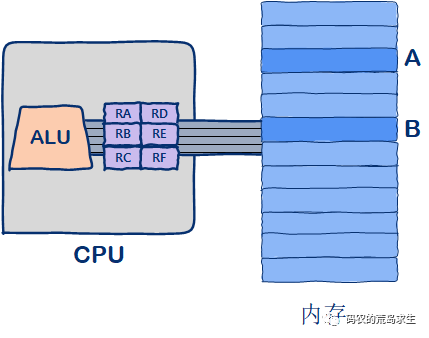
内存中的地址A和地址B分别存放了两个数,假设我们想计算这两个数字之和,然后再把计算结果写回内存地址A。
我们分别来看下在CISC和在RISC下的会怎样实现。
1,CISC
复杂指令集的一个主要目的就是让尽可能少的机器指令来完成尽可能多的任务,在这种思想下CPU需要在从内存中拿到一条机器指令后“自己去完成一系列的操作”,这部分操作对外不可见。
在这种方法下,CISC中可能会存在一条叫做MULT的机器指令,MULT是乘法multiplication的简写。
当CPU执行MULT这条机器指令时需要:
从内存中加载地址A上的数,存放在寄存器中
从内存中夹杂地址B上的数,存放在寄存器中
ALU根据寄存器中的值进行乘积
将乘积写回内存
以上这几部统统都可以用这样一条指令来完成:
- MULT A B
MULT就是所谓的复杂指令了,从这里我们也可以看出,复杂指令并不是说“MULT A B”这一行指令本身有多复杂,而是其背后所代表的任务复杂。
这条机器指令直接从内存中加载数据,程序员(写汇编语言或者写编译器的程序员)根本就不要自己显示的从内存中加载数据,实际上这条机器指令已经非常类似高级语言了,我们假设内存地址A中的值为变量a,地址B中的值为变量b,那么这条机器指令基本等价于高级语言中这样一句:
- a = a * b;
这就是我们在上一篇《CPU进化论:复杂指令集》中提到的所谓抹平差异,semantic gap,抹平高级语言和机器指令之间的差异,让程序员或者编译器使用最少的代码就能完成任务,因为这会节省程序本身占用的内存空间,要知道在在1977年,1MB内存的价格大概需要$5000,省下来的就是钱。
因为一条机器指令背后的操作很多,而程序员仅仅就写了一行“MULT A B”,这行指令背后的复杂操作就必须由CPU直接通过硬件来实现,这加重了CPU 硬件本身的复杂度,需要的晶体管数量也更多。
接下来我们看RISC方法。
2,RISC
相比之下RISC更倾向于使用一系列简单的指令来完成一项任务,我们来看下一条MULT指令需要完成的操作:
从内存中加载地址A上的数,存放在寄存器中
从内存中夹杂地址B上的数,存放在寄存器中
ALU根据寄存器中的值进行乘积
将乘积写回内存
这几步需要a)从内存中读数据;b)乘积;c) 向内存中写数据,因此在RISC下会有对应的LOAD、PROD、STORE指令来分别完成这几个操作。
Load指令会将数据从内存搬到寄存器;PROD指令会计算两个寄存器中数字的乘积;Store指令把寄存器中的数据写回内存,因此如果一个程序员想完成上述任务就需要写这些汇编指令:
- LOAD RA, A
- LOAD RB, B
- PROD RA, RB
- STORE A, RA
现在你应该看到了,同样一项任务,在CISC下只需要一条机器指令,而在RISC下需要四条机器指令,显然RISC下的程序本身所占据的空间要比CISC大,而且这对直接用汇编语言来写程序的程序员来说是很不友好的,因为更繁琐嘛!再来看看这样图感受一下:

但RISC设计的初衷也不是让程序员直接使用汇编语言来写程序,而是把这项任务交给编译器,让编译器来生成机器指令。
标准从来都是一个好东西
让我们再来仔细的看一下RISC下生成的几条指令:
- LOAD RA, A
- LOAD RB, B
- PROD RA, RB
- STORE A, RA
这些指令都非常简单,CPU内部不需要复杂的硬件逻辑来进行解码,因此更节省晶体管,这些节省下来的晶体管可用于其它功能上。
最关键的是,注意,由于每一条指令都很简单,执行的时间都差不多,因此这使得一种能高效处理机器指令的方法成为可能,这项技术是什么呢?
我们在《CPU遇上特斯拉,程序员的心思你别猜》这篇文章中提到过,这就是有名的流水线技术。
指令流水线
流水线技术是初期精简指令集的杀手锏。
在这里我们还是以生产汽车(新能源)为例来介绍一下。
假设组装一辆汽车需要经过四个步骤:组装车架、安装引擎、安装电池、检验。
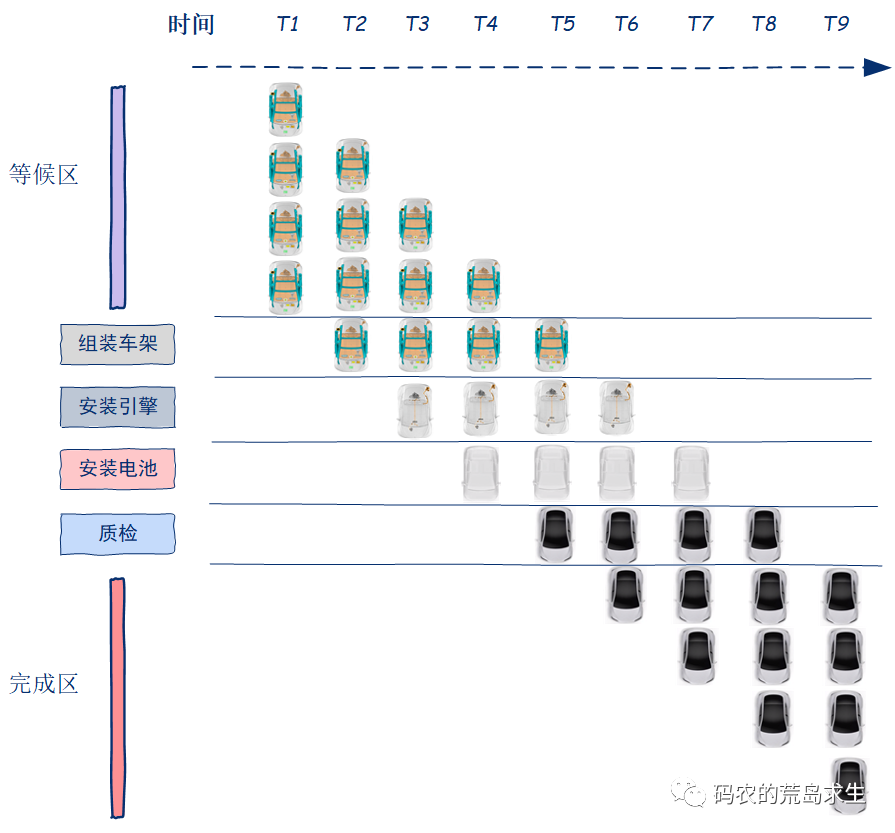
假设这每个步骤需要10分钟,如果没有流水线技术,那么生产一辆汽车的时间是40分钟,只有第一辆汽车完整的经过这四个步骤后下一辆车才能进入生产车间。
这就是最初复杂指令集CPU的工作场景。
显然这是相当低效的,因为当前一辆车在进行最后一个步骤时,前三个步骤:组装车架、安装引擎、安装电池,这三个步骤的工人是空闲。
CPU的道理也是一样的,低效的原因在于没有充分利用资源,在这种方法下有人会偷懒。
但引入流水线技术就不一样了,当第一辆车还在安装引擎时后一辆车就可以进入流水线来组装车架了,采用流水线技术,四个步骤可以同时进行,最大可能的充分利用资源。
原来40分钟才能生产一辆车,现在有了流水线技术可以10分钟就生产出一辆车。
注意,这里的假设是每个步骤都需要10分钟,如果流水线每个阶段的耗时不同,将显著影响流水线的处理能力。
假如其中一个步骤,安装电池,需要20分钟,那么安装电池的前一个和后一个步骤就会有10分钟的空闲,这显然不能充分利用资源。
精简指令集的设计者们当然也明白这个道理,因此他们尝试让每条指令执行的时间都差不多一样,尽可能让流水线更高效的处理机器指令,而这也是为什么在精简指令集中存在Load和Store两条访问内存指令的原因。
由于复杂指令集指令与指令之间差异较大,执行时间参差不齐,没办法很好的以流水线的方式高效处理机器指令(后续我们会看到复杂指令集会改善这一点)。
第一代RISC处理器即为全流水线设计,典型的就是五级流水线,大概1到2个时钟周期就能执行一条指令,而这一时期的CISC大概5到10个时钟周期才能执行一条指令,尽管RISC架构下编译出的程序需要更多指令,但RISC精简的设计使得RISC架构下的CPU更紧凑,消耗更少的晶体管(无需微代码),因此带来更高的主频,这使得RISC架构下的CPU完成相同的任务速度优于CISC。
有流水线技术的加持,采用精简指令集设计的CPU在性能上开始横扫其复杂指令集对手。
名扬天下
到了1980年代中期,采用精简指令集的商业CPU开始出现,到1980年代后期,采用精简指令集设计的CPU就在性能上轻松碾压所有传统设计。
到了1987年采用RISC设计的MIPS R2000处理器在性能上是采用CISC架构(x86)的Intel i386DX两到三倍。
所有其它CPU生成厂商都开始跟进RISC,积极采纳精简指令集设计思想,甚至操作系统MINIX(就是那个Linus上大学时使用的操作系统)的作者Andrew Tanenbaum在90年代初预言:“5年后x86将无人问津”,x86正是基于CISC。

CISC迎来至暗时刻。
接下来CISC该如何绝地反击,要知道Inter以及AMD (x86处理器两大知名生产商) 的硬件工程师们绝非等闲之辈。
预知后事如何,请听下回分解。
总结
CISC中微代码设计的复杂性让人们重新思考CPU到底该如何设计,基于对执行指令的重新审视RISC设计哲学应运而生。
RISC中每条指令更加简单,执行时间比较标准,因此可以很高效的利用流水线技术,这一切都让采用RISC架构的CPU获得了很好性能。
面对RISC,CISC阵营也开始全面反思应如何应对挑战。后续文章将继续这一话题。
希望本文对大家理解精简指令集有所帮助。
本文转载自微信公众号「码农的荒岛求生」,可以通过以下二维码关注。转载本文请联系码农的荒岛求生公众号。















