本文转载自微信公众号「小菜良记」,作者蔡不菜丶 。转载本文请联系小菜良记公众号。
k8s 我们已经从 NameSpace、Pod、PodController到Volumn都介绍过了,相信看完的小伙伴们也会很有收获的~那么今天我们继续来到k8s的课堂,这节我们将要来说下 k8S 搭建完服务后如何访问!
首先我们要清楚什么是Service 和 Ingress。简单来说,这两个组件都是用来做流量负载的。那么什么又是流量负载呢?当我们在集群内部已经通过 pod 部署了我们的应用服务,那么下一步要干啥?那就是让用户访问到我们的应用服务,这个才是最重要的,不然你部署完了,用户却访问不了,那岂不是无用功~
一、Service
在 k8s 中,pod 是应用程序的载体,我们可以通过 pod的 IP 来访问我们的应用程序,但是我们已经清楚了 pod 是具有生命周期的,一旦 pod 出现问题,pod控制器将会将pod销毁进行重新创建。那么这个时候 pod 的Ip就会发生变化,因此利用 pod IP 访问应用程序的方式直接 pass了,那么为了解决这个问题,k8s 引入了 Service 的资源概念,通过这个资源,可以整合多个pod,提供一个统一的入口地址,通过访问 Service 的入口地址就能访问到后面的 pod服务!
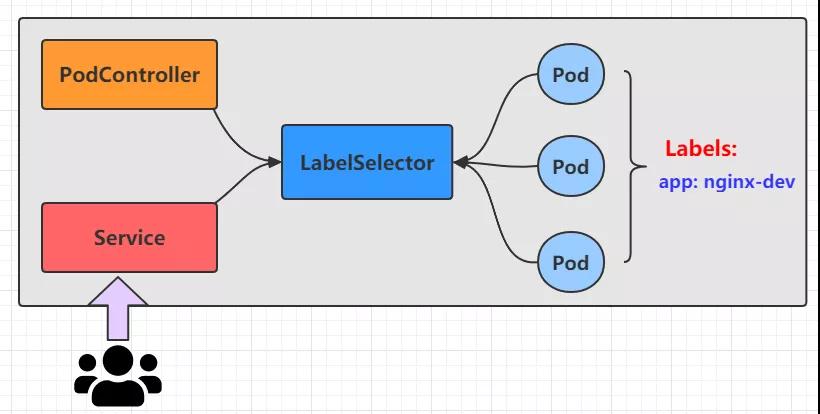
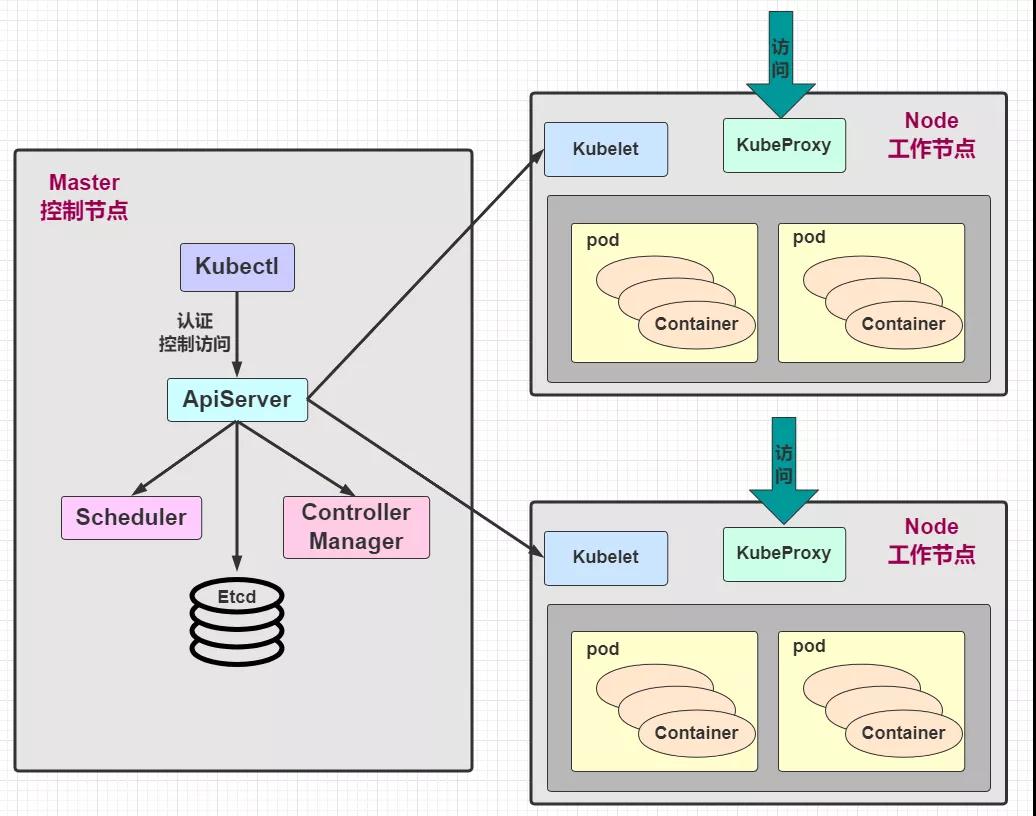
Service不是凭空出现的,不知道你是否还记得 Node 节点上的关键组件 kube-proxy!关键点来了哦~我们看个老图回忆一下:
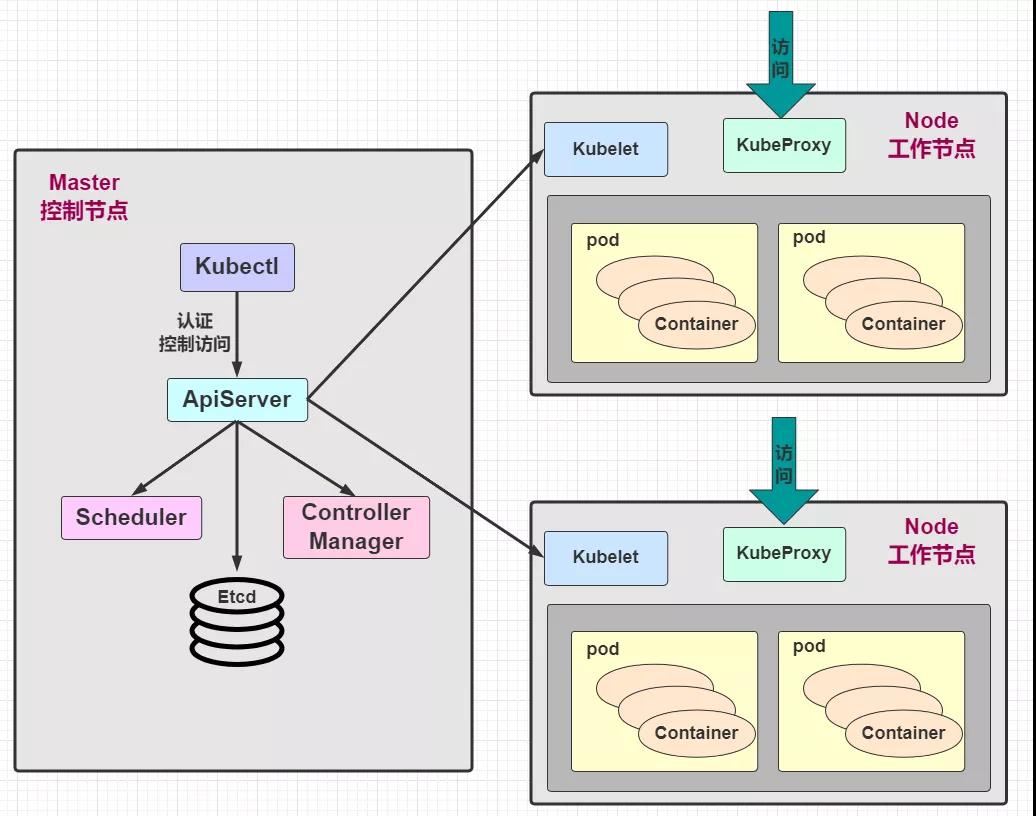
这张图有看过之前的博文都不会陌生,是的!kube-proxy 在这里面起到了关键性的作用,每个 Node 节点上都运行着一个 kube-proxy 服务进程,当创建 Service 的时候会通过 api-server 向 etc写入创建的 service 的信息,而 kube-proxy 会基于监听的机制发现这种 Service 的变动,然后 它会将最新的Service信息转换成对应的访问规则
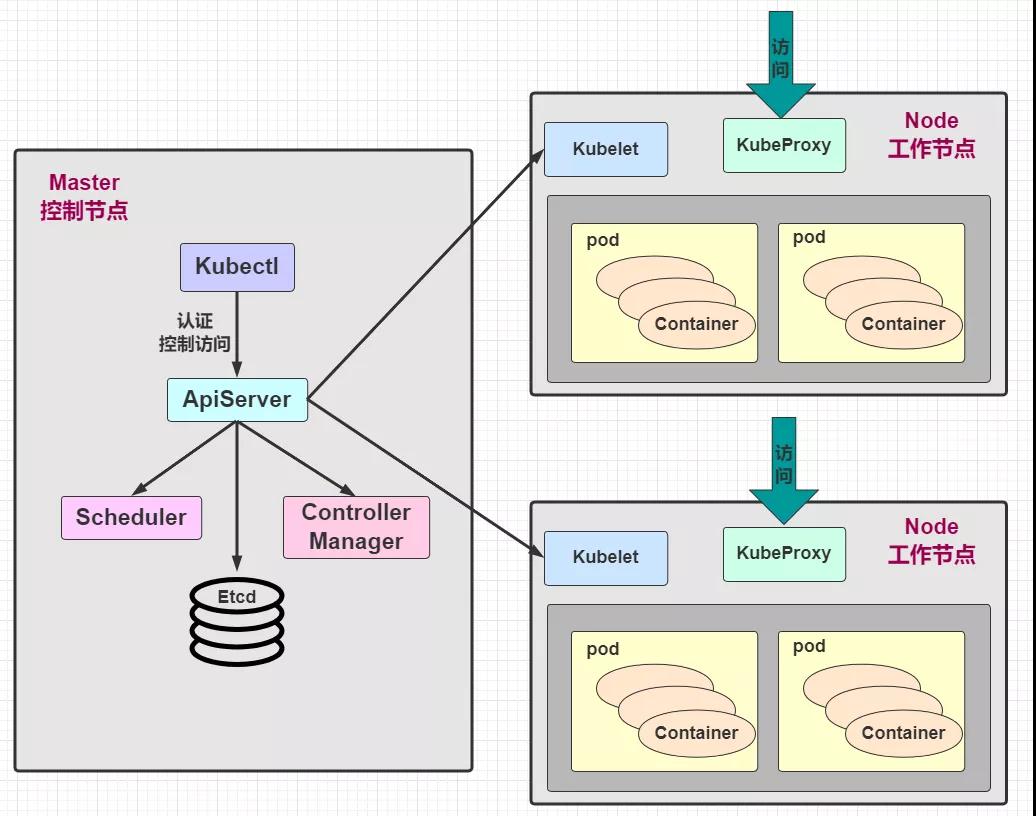
到这里,应该对Service有个大概的概念,起码知道了它的用处,接下来我们不妨更加深入的了解一下~
1)工作模式
kube-proxy 支持 3 种工作模式,如下:
1. userSpace
这个模式比较稳定,但是效率比较低!在 userSpace 模式下,kube-proxy 会为每一个 Service 创建一个监听端口,当有请求发往Cluster IP 的时候,会被 Iptables 规则重定向到 kube-proxy 监听的端口上,kube-proxy 会根据 LB 算法选择一个 Pod 提供服务并建立起连接。
这个模式下,kube-proxy 充当的角色是一个 四层负责均衡器,由于 kube-proxy 运行在 userSpace 模式下,在进行转发处理的时候会增加内核和用户空间之间的数据拷贝,因此效率比较低。
2. iptables
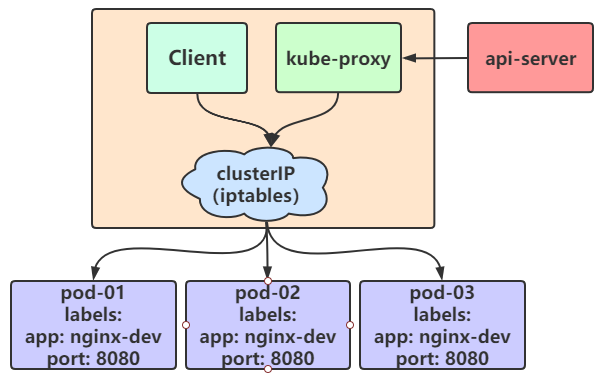
在 iptables 模式下,kube-proxy 会为 Service 后端的每个 pod 都创建对应的 iptable 规则,直接将发往 Cluster IP 的请求重定向到一个 pod IP 上。该模式下 kube-proxy 不承担四层负载均衡器的角色,只负责创建 iptables 的规则。该模式的优点便是较 userspace 模式来说效率更高,但是不能提供灵活的 LB 策略。当后端Pod不可用的时候也无法进行重试。
3. ipvs
这种模式与 iptables 模式形似,kube-proxy 会监控pod的变化并且创建相应的 ipvs 规则。但是 ipvs 规则相对于 iptables 来说转发效率更高,而且支持更多的 LB 算法。
实践
上面了解到3种工作模式。我们来简单试一下 ipvs 的作用。首先准备一份资源清单:
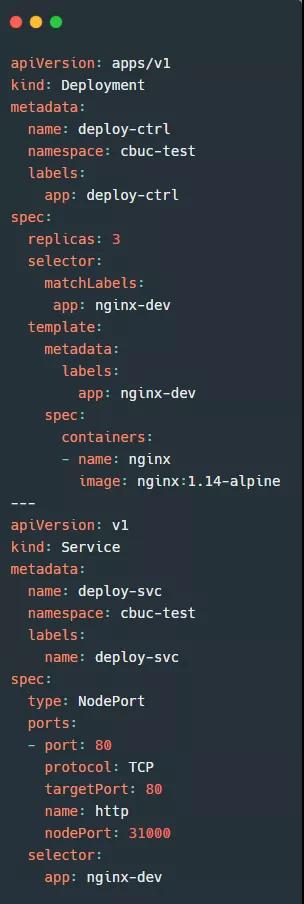
这份清单上半部分是创建一个 Pod控制器,下半部分是创建一个 Service。

然后我们输入 ipvsadm -Ln命令即可看到 ipvs规则策略:
10.108.230.12 是 service 提供的访问入口,当访问这个入口的时候,可以发现后面有三个 pod 的服务在等待调用,kube-proxy 会基于 rr(轮询)的策略,将请求分发到其中一个pod上去,这个规则会同时在集群内的所有节点上都生成,所以在任何一个节点上访问都可以!
此模式必须安装 ipvs 内核模块,否则会降低为 iptables
开启 ipvs:
- kubectl edit cm kube-proxy -n kube-system
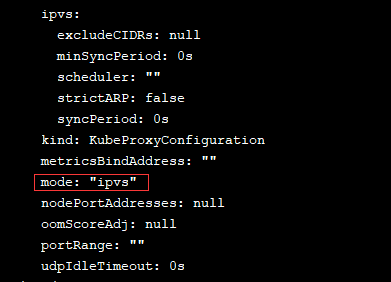
编辑后保存(:wq) 退出
- kubectl delete pod -l k8s-app=kube-proxy -n kube-system
- ipvsadm -Ln
2)Service 使用
上面已经介绍完了 Service 的几种工作模式。下面我们进入Service 的使用阶段。我们上面已经做了简单的实践,创建了一个 Deploy ,一个 Service ,然后我们可以通过 serviceIp + targetPort 或 nodeIp + nodePort访问资源
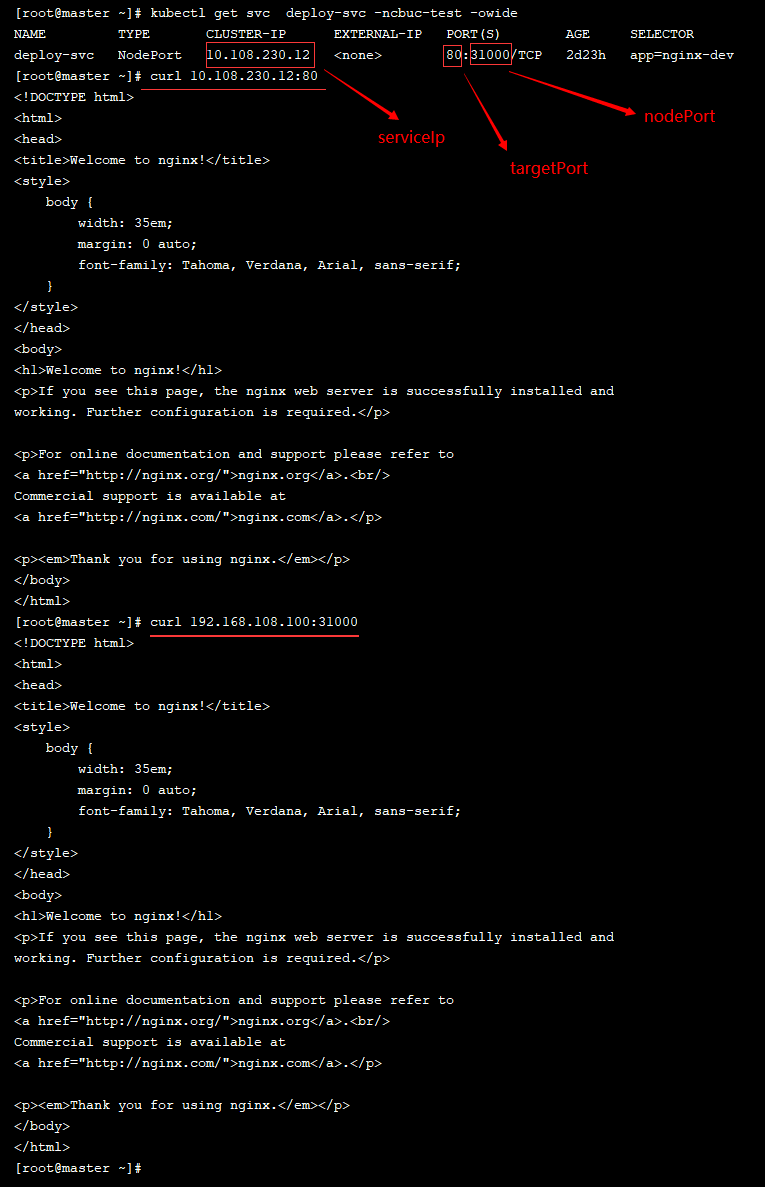
但是在学习 Service 的使用,仅仅这个是不够的,Service又分为5种类型,下面将一一介绍。
1. ClusterIP
我们先看下 ClusterIP 类型的Service的资源清单:
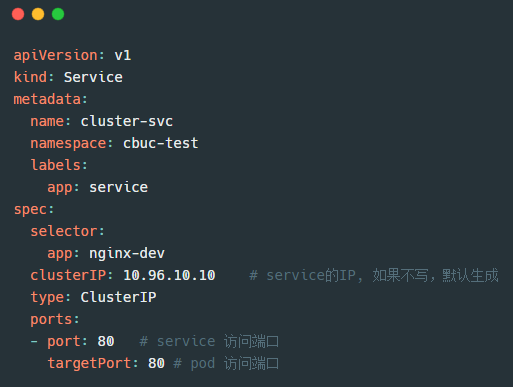
通过创建后测试访问 clusterIp + port
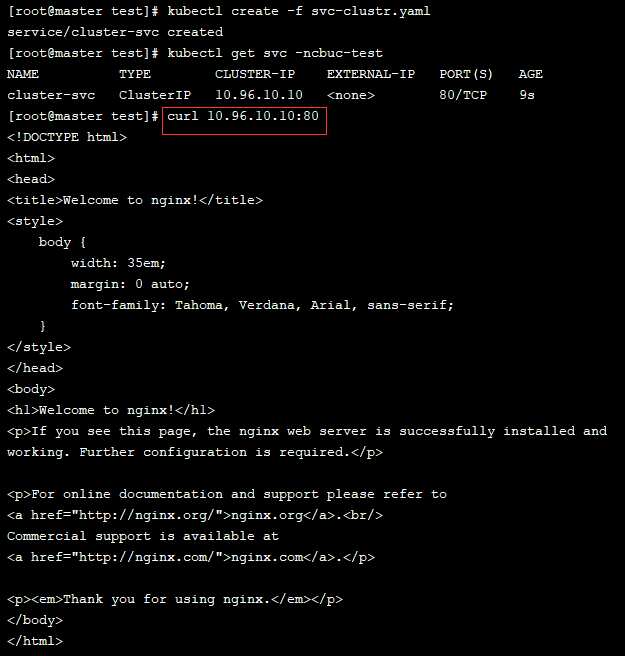
我们再查看下 ipvs 规则,可以看到该service已经可以转发到对应的3个pod上
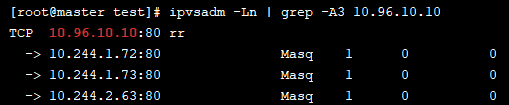
接下来我们可以通过 describe 指令查看该service有哪些信息:
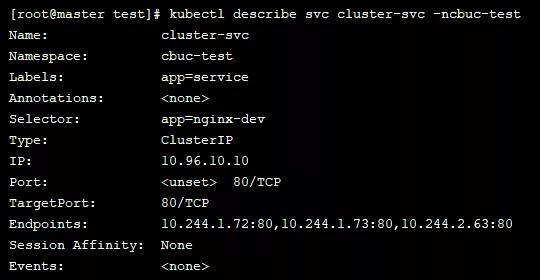
扫了一遍发现 Endpoints 和 Session Affinity 都是我们之间没有见过的。那这个又是个什么东西呢?
Endpoint
Endpoint 是 k8s 中的一个资源对象,存储在etcd中,用来记录一个 service 对应的所有Pod 的访问地址,它是根据 service 配置文件中 selector 描述产生的。一个Service由一组Pod组成,这些Pod通过 Endpoint 暴露出来,可以说 Endpoint 是实际实现服务的端口的集合。通俗来说,Endpoint 是 service 和 pod 之间的桥梁
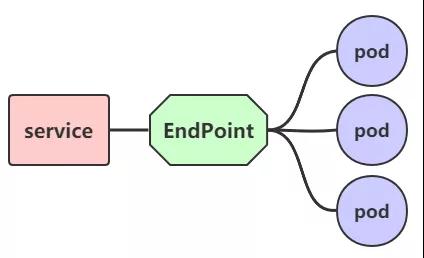
既然是一个资源,那么我们就可以获取到

负载分发
我们上面已经成功的实现了通过 Service 访问到Pod 资源,那么我们再做一些修改,分别进入3个pod编辑 usr/share/nginx/index.html 文件:
- # pod01
- Pod01 : ip - 10.244.1.73
- # pod02
- Pod01 : ip - 10.244.1.73
- # pod03
- Pod03 : ip - 10.244.2.63
然后我们再次尝试通过 curl 10.96.10.10:80命令查看结果:
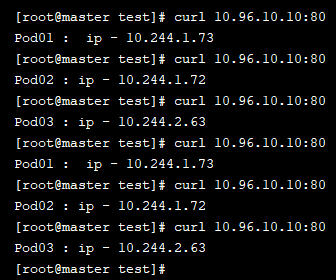
眼尖的你是否有发现,这种负载分发策略不就是轮询吗!对于 Service 的访问,k8s提供了两种负载分发策略:
- 如果未定义分发策略,默认使用 kube-proxy 的策略,比如随机、轮询
- 基于客户端地址的会话保持模式,即来自同一个客户端发起的所有请求都会转发到固定的一个pod上。而这里就需要用到我们上面提到的没有见过的东西 sessionAffinity
之前我们用 ipvsadm -Ln 命令查看分发策略的时候,里面有个 rr 字段不知道你有没有注意到,没错,这个 rr 值得就是轮询的意思
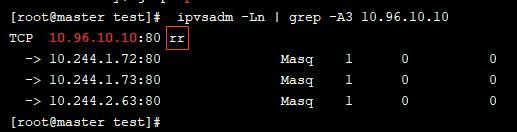
如果我们想要开启会话保持的分发策略,那么只需要在spec中添加 sessionAffinity:ClientIP 选项
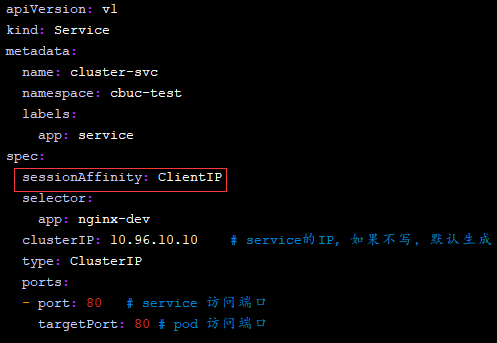
再次通过 ipvsadm -Ln 命令查看分发策略就可以发现结果已经发生变化了
我们简单测试一下:

这样子就已经实现了会话保持的分发策略!
注意:ClusterIp 的 Service,不支持外部访问,也就是说通过浏览器访问是不生效的,只能在集群内部访问
2. HeadLiness
很多服务都需要支持定制化,如果将产品定位为服务,那么这个产品毋庸是成功。在某些场景中,开发人员并不想要使用 service 提供的负载均衡功能,而是希望自己来控制负载均衡策略。针对这种情况的发生,k8s也是很好的支持了,引入了 HeadLiness Service,这类 Service 不会分配 ClusterIp,如果想要访问 service,只能通过 Service 域名进行查询。
我们来看下 HeadLiness 的资源清单模板:
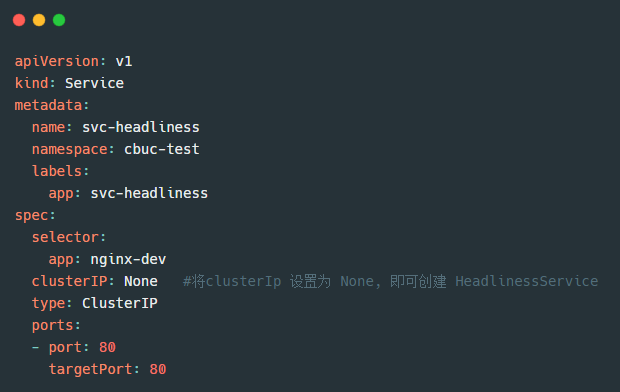
唯一跟 ClusterIp 不同的便是 clusterIP: None 属性的变化。

通过创建后可以发现,ClusterIP并未分配,我们继续查看 Service 的详情
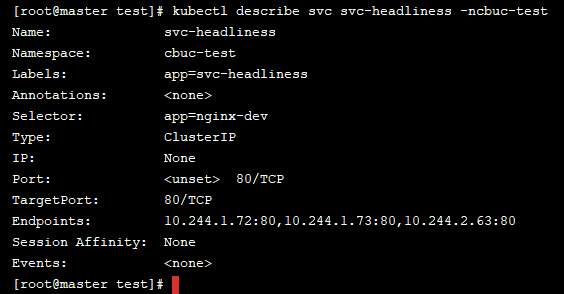
通过详情我们可以发现 Endpoints 已经生效了,然后我们任意进入到一个pod中,查看域名解析情况:

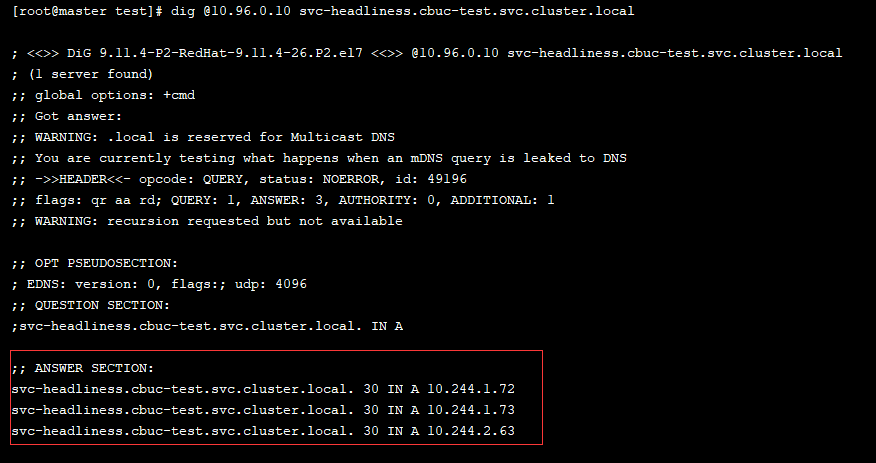
可以看到域名也已经解析完成,默认域名为service名称.命名空间.svc.cluster.local
3. NodePort
上面的两个service类型,都是只能在集群内部才能访问,但是我们部署服务肯定是想让用户通过集群外部可以使用的。那么这个时候就需要用到我们开头创建的service类型,那就是 NodePort service。
这种类型的Service的工作原理也不难,其实 就是将 service的端口映射到 Node 的一个端口上,然后通过 NodeIp+NodePort进行访问
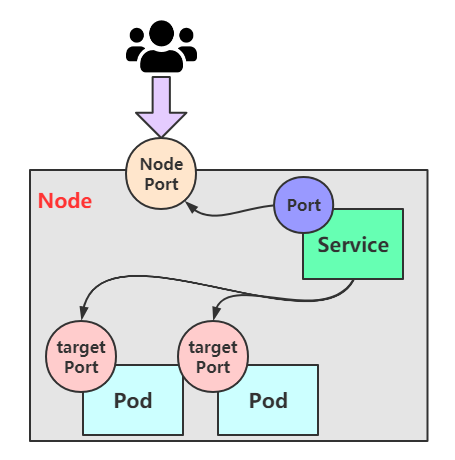
看了原理图是不是感觉豁然开朗啦。那么来看看是怎么通过资源清单创建的:
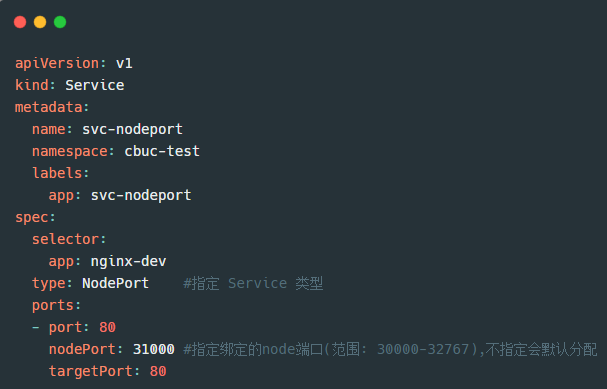
我们通过以上资源清单创建service,然后访问:
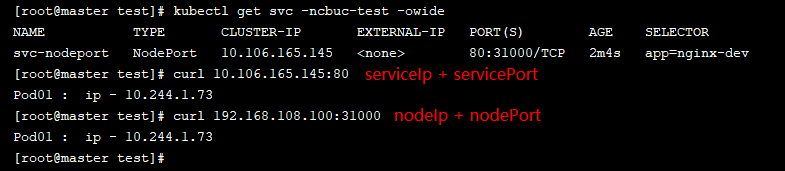
可以看出通过两种方式都是可以访问的,我们也可以在浏览器试试看:

这结果也是如我们所愿!
不要感觉到这里就已经心满意足了哦,虽然说已经可以成功让用户访问到了~我们趁热打铁继续再了解剩下的两种类型~
4. LoadBalancer
LoadBalancer 听名字就知道跟负载均衡有关。这个类型与 NodePort 很相似,目的都是向外部暴露一个端口,主要的区别在于 LoadBalancer 会在集群的外部再做一个负载均衡器,而这个设备是需要外部环境支持的,外部环境发送到这个设备的请求,会被设备负载之后转发到集群中。
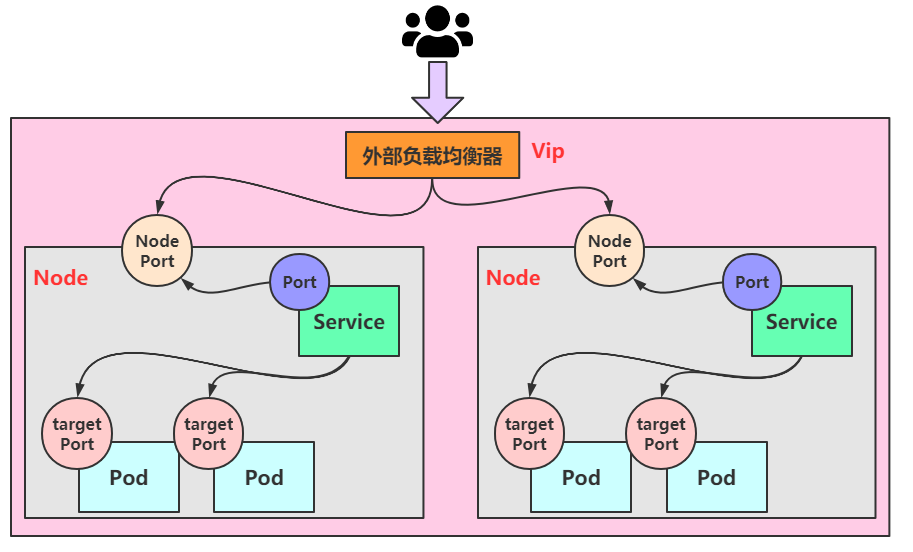
图中有个Vip的概念,这里的Vip指的是 Vitual IP,也就是虚拟IP,外部用户通过访问这个虚拟IP,可以负载到我们不同的service上,达到负载均衡和高可用的特点
5. ExternalName
ExternalName 类型的service 是用于引入集群外部的服务,它通过 externalName 属性指定外部一个服务的地址,然后在集群内部访问此service就可以访问到外部服务了。
资源清单:
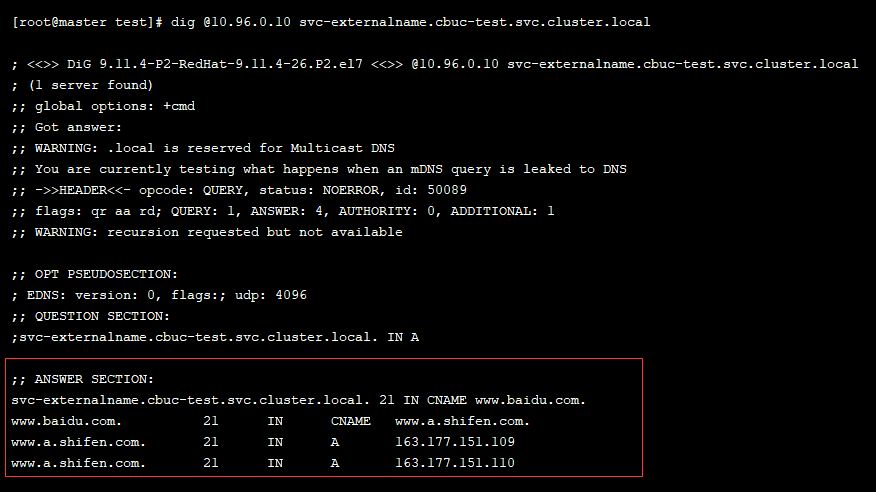
创建后我们可以查看域名解析,发现已经解析成功:
- dig @10.96.0.10 svc-externalname.cbuc-test.svc.cluster.local
二、Ingress
1)工作模式
上面我们已经讲完了 Service几种类型的用法,我们已经知晓了想让外部用户访问到我们pod中的服务有两种类型的service是支持的,分别是:NodePort和LoadBalancer,但是其实认真分析一下,我们不难发现这两种service 的缺点:
NodePort:会占用集群机器的很多端口,当集群服务变多的时候,这个缺点就越发明显
LoadBalancer:每个Service都需要一个LB,比较麻烦和浪费资源,并且需要 k8s之外的负载均衡设备支持
这种缺点当然不只是我们能够发现,作为k8s的启动者早已意识到了,紧接着便推出了 Ingress 的概念。Ingress 仅需要一个 NodePort或 LB 就可以满足暴露多个Service的需求:
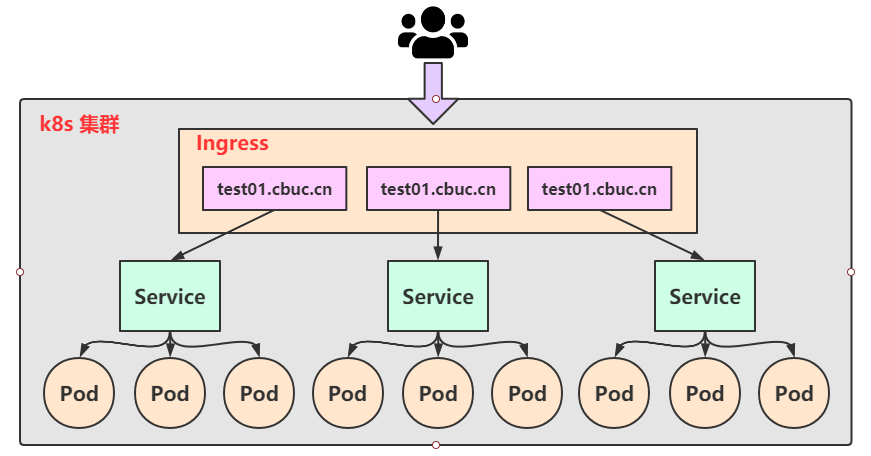
实际上,Ingress就相当于一个7层的负载均衡器,是 K8s 对反向代理的一个抽象,它的工作原理类似于 Nginx,可以理解成在 Ingress 里 建立诸多的隐射规则,然后 Ingress Controller通过监听这些配置规则转化成 Nginx 的反向代理配置,然后对外提供该服务。这边涉及到了两个重要的概念:
- Ingress:K8s 中的一个资源对象,作用是定义请求如何转发到 service 的规则
- Ingress Controller:具体实现反向代理及负载均衡的程序,对Ingress定义的规则进行解析,根据配置的规则来实现请求转发,有很多种实现方式,如 Nginx、Contor、Haproxy等
Ingress 控制器 有很多中可以实现请求转发的方式,我们通常上也会选择我们比较熟悉的 Nginx 作为负载,接下来我们就以 Nginx 为例,我们先来了解一下其工作原理:
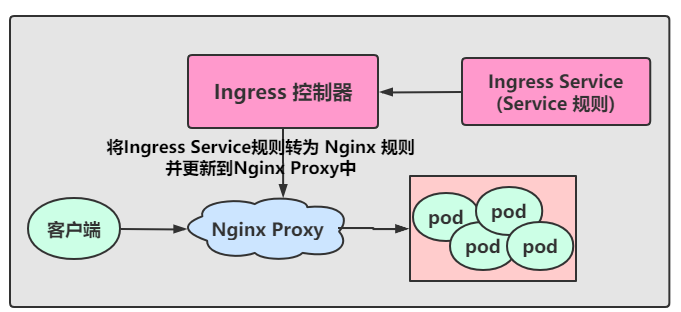
- 用户编写 Ingress Service规则, 说明每个域名对应 K8s集群中的哪个Service
- Ingress控制器会动态感知到 Ingress 服务规则的变化,然后生成一段对应的Nginx反向代理配置
- Ingress控制器会将生成的Nginx配置写入到一个运行中的Nginx服务中,并动态更新
- 然后客户端通过访问域名,实际上Nginx会将请求转发到具体的Pod中,到此就完成了整个请求的过程
了解了工作原理,我们就来落地实现~
2)Ingress使用
1. 环境搭建
在使用 Ingress之前,我们需要先搭建一个 Ingress 环境
步骤一:
- # 拉取我们需要的资源清单
- wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/nginx-0.30.0/deploy/static/mandatory.yaml
- wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/nginx-0.30.0/deploy/static/provider/baremetal/service-nodeport.yaml
步骤二:
- # 创建资源
- kubectl apply -f ./
步骤三:
查看资源是否创建成功

到这里我们就已经准备好了 Ingress 环境,接下来来到测试环节~
我们准备了两个Service,两个 Deployment,和创建了6个副本的Pod
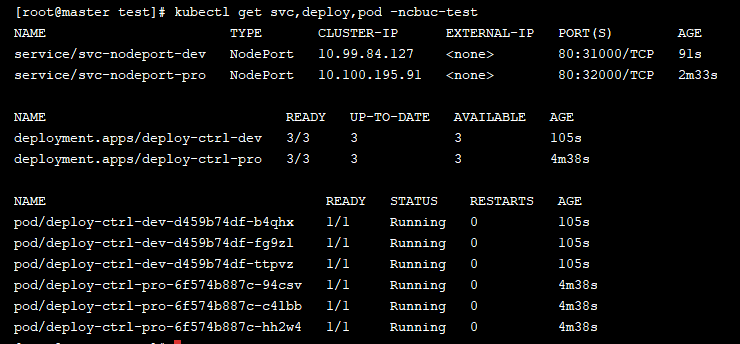
如果到现在还准备不出这些资源的小伙伴得回头做功课了哦~
大致结构图如下:
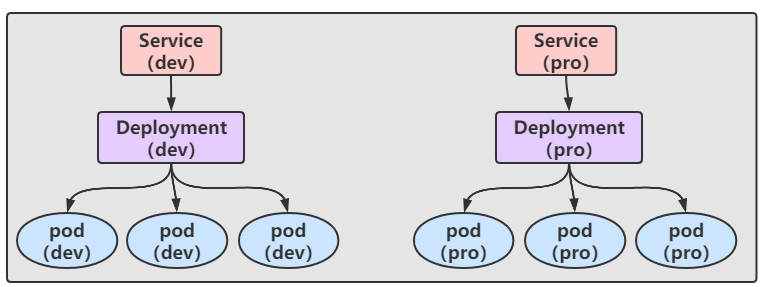
那我们现在就准备一个 Ingress 来达到以下的结果
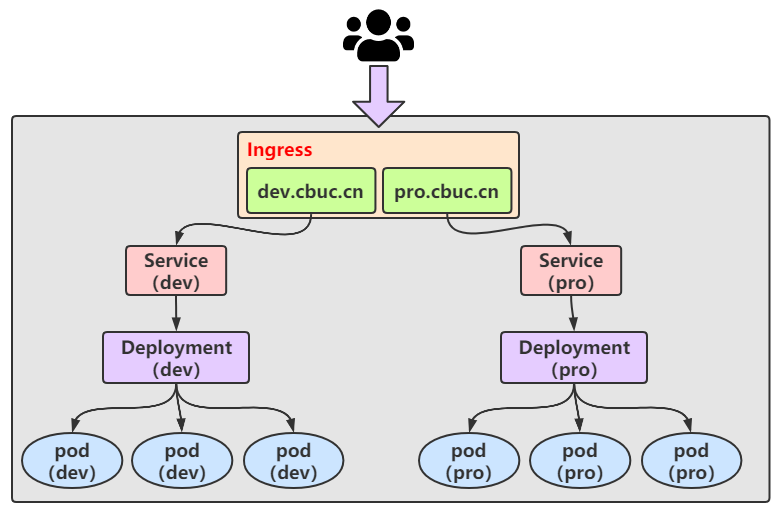
准备 Ingress 的资源清单:
- apiVersion: extensions/v1beta1
- kind: Ingress
- metadata:
- name: ingress-htpp
- namespace: cbuc-test
- spec:
- rules:
- - host: dev.cbuc.cn
- http:
- paths:
- - path: /
- backend:
- serviceName: svc-nodeport-dev
- servicePort: 80
- - host: pro.cbuc.cn
- http:
- paths:
- - path: /
- backend:
- serviceName: svc-nodeport-pro
- servicePort: 80
通过创建后我们还需要在我们电脑的本地 hosts 添加域名映射:
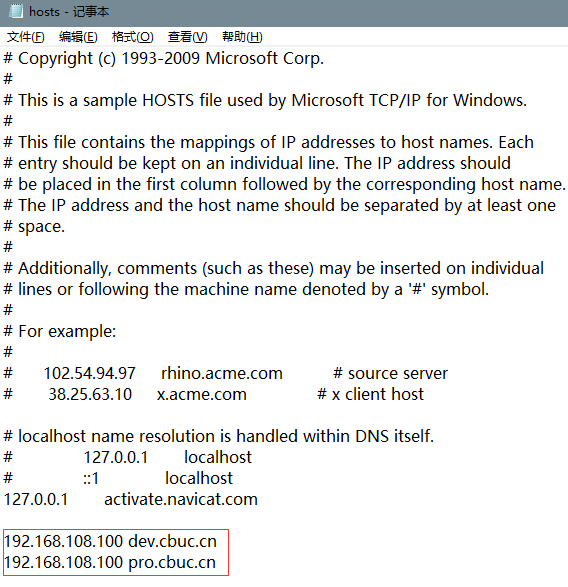
然后在网页上通过 域名+nodePort 的方式就可以访问到了
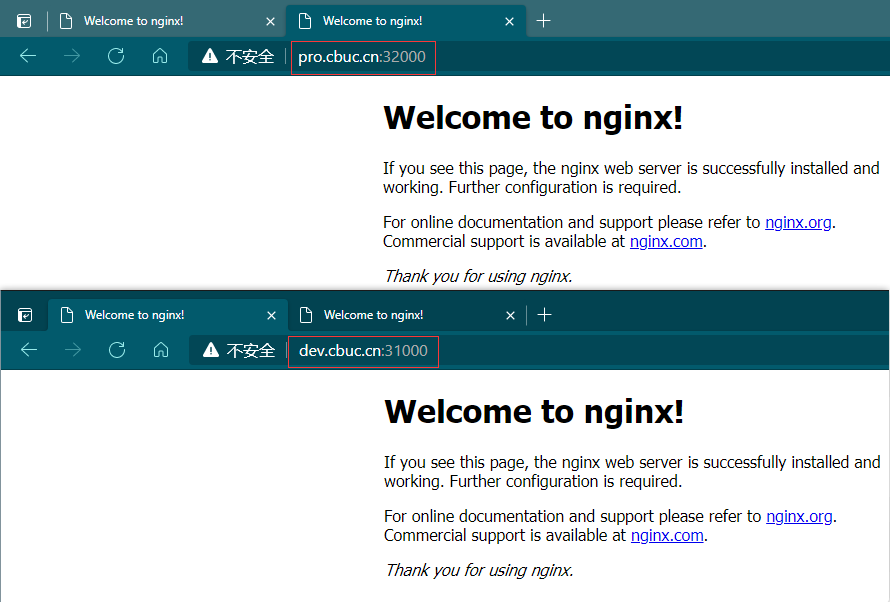
到这里我们就实现了Ingress 的访问方式!