Spark SQL 的 Catalyst ,这部分真的很有意思,值得去仔细研究一番,今天先来说说Spark的一些扩展机制吧,上一次写Spark,对其SQL的解析进行了一定的魔改,今天我们按套路来,使用砖厂为我们提供的机制,来扩展Spark...
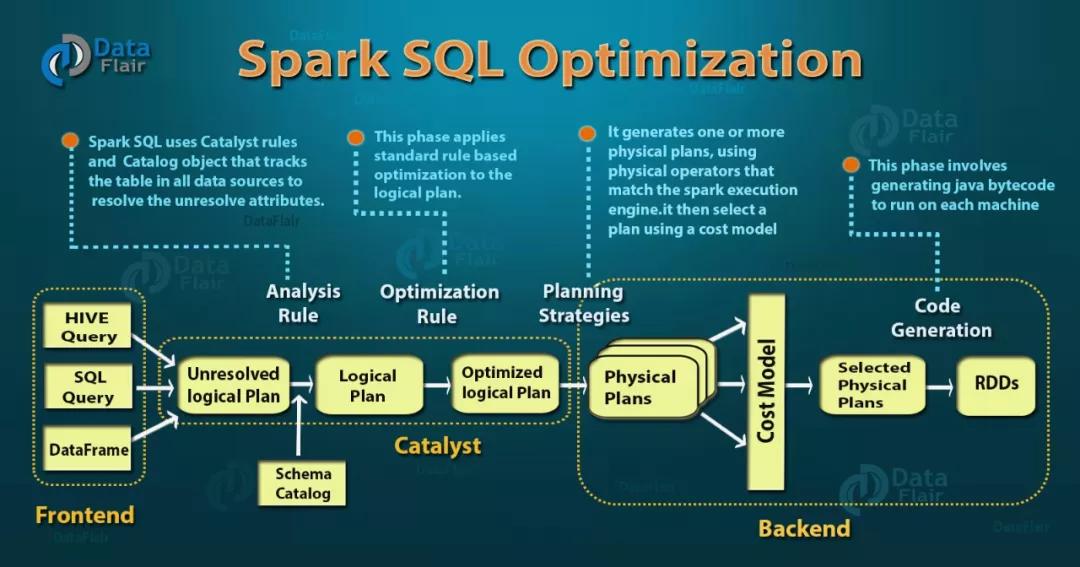
首先我们先来了解一下 Spark SQL 的整体执行流程,输入的查询先被解析成未关联元数据的逻辑计划,然后根据元数据和解析规则,生成逻辑计划,再经过优化规则,形成优化过的逻辑计划(RBO),将逻辑计划转换成物理计划在经过代价模型(CBO),输出真正的物理执行计划。
我们今天举三个扩展的例子,来进行说明。
扩展解析器
这个例子,我们扩展解析引擎,我们对输入的SQL,禁止泛查询即不许使用select *来做查询,以下是解析的代。
package wang.datahub.parser
import org.apache.spark.sql.catalyst.analysis.UnresolvedStar
import org.apache.spark.sql.catalyst.expressions.Expression
import org.apache.spark.sql.catalyst.parser.ParserInterface
import org.apache.spark.sql.catalyst.plans.logical.{LogicalPlan, Project}
import org.apache.spark.sql.catalyst.{FunctionIdentifier, TableIdentifier}
import org.apache.spark.sql.types.{DataType, StructType}
class MyParser(parser: ParserInterface) extends ParserInterface {
/**
* Parse a string to a [[LogicalPlan]].
*/
override def parsePlan(sqlText: String): LogicalPlan = {
val logicalPlan = parser.parsePlan(sqlText)
logicalPlan transform {
case project @ Project(projectList, _) =>
projectList.foreach {
name =>
if (name.isInstanceOf[UnresolvedStar]) {
throw new RuntimeException("You must specify your project column set," +
" * is not allowed.")
}
}
project
}
logicalPlan
}
/**
* Parse a string to an [[Expression]].
*/
override def parseExpression(sqlText: String): Expression = parser.parseExpression(sqlText)
/**
* Parse a string to a [[TableIdentifier]].
*/
override def parseTableIdentifier(sqlText: String): TableIdentifier =
parser.parseTableIdentifier(sqlText)
/**
* Parse a string to a [[FunctionIdentifier]].
*/
override def parseFunctionIdentifier(sqlText: String): FunctionIdentifier =
parser.parseFunctionIdentifier(sqlText)
/**
* Parse a string to a [[StructType]]. The passed SQL string should be a comma separated
* list of field definitions which will preserve the correct Hive metadata.
*/
override def parseTableSchema(sqlText: String): StructType =
parser.parseTableSchema(sqlText)
/**
* Parse a string to a [[DataType]].
*/
override def parseDataType(sqlText: String): DataType = parser.parseDataType(sqlText)
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
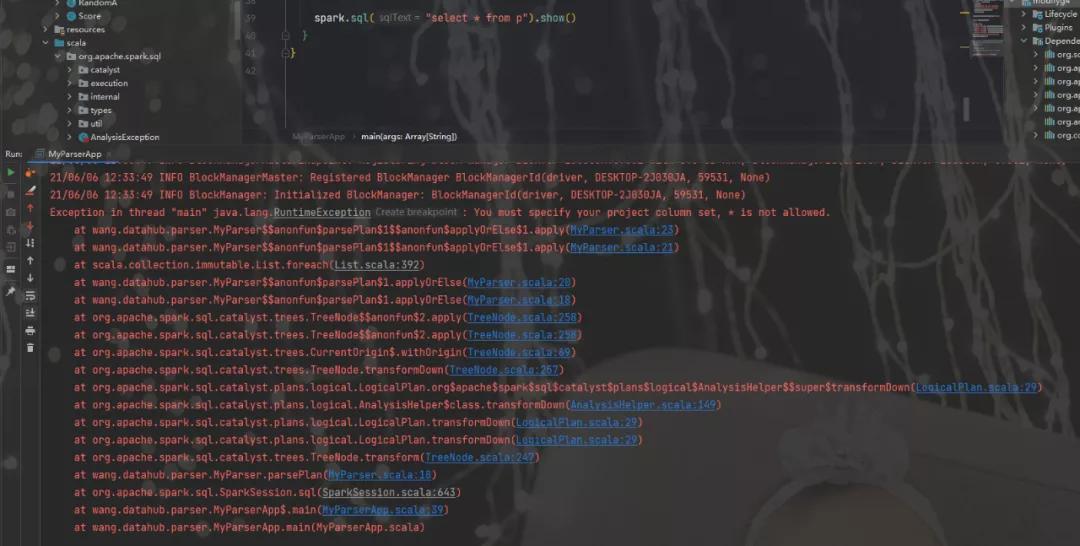
接下来,我们测试一下
package wang.datahub.parser
import org.apache.spark.sql.{SparkSession, SparkSessionExtensions}
import org.apache.spark.sql.catalyst.parser.ParserInterface
object MyParserApp {
def main(args: Array[String]): Unit = {
System.setProperty("hadoop.home.dir","E:\\devlop\\envs\\hadoop-common-2.2.0-bin-master");
type ParserBuilder = (SparkSession, ParserInterface) => ParserInterface
type ExtensionsBuilder = SparkSessionExtensions => Unit
val parserBuilder: ParserBuilder = (_, parser) => new MyParser(parser)
val extBuilder: ExtensionsBuilder = { e => e.injectParser(parserBuilder)}
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.config("spark.master", "local[*]")
.withExtensions(extBuilder)
.getOrCreate()
spark.sparkContext.setLogLevel("ERROR")
import spark.implicits._
val df = Seq(
( "First Value",1, java.sql.Date.valueOf("2010-01-01")),
( "First Value",4, java.sql.Date.valueOf("2010-01-01")),
("Second Value",2, java.sql.Date.valueOf("2010-02-01")),
("Second Value",9, java.sql.Date.valueOf("2010-02-01"))
).toDF("name", "score", "date_column")
df.createTempView("p")
// val df = spark.read.json("examples/src/main/resources/people.json")
// df.toDF().write.saveAsTable("person")
//,javg(score)
// custom parser
// spark.sql("select * from p ").show
spark.sql("select * from p").show()
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
下面是执行结果,符合我们的预期。
扩展优化器
接下来,我们来扩展优化器,砖厂提供了很多默认的RBO,这里可以方便的构建我们自己的优化规则,本例中我们构建一套比较奇怪的规则,而且是完全不等价的,这里只是为了说明。
针对字段+0的操作,规则如下:
- 如果0出现在+左边,则直接将字段变成右表达式,即 0+nr 等效为 nr
- 如果0出现在+右边,则将0变成3,即 nr+0 变成 nr+3
- 如果没出现0,则表达式不变
下面是代码:
package wang.datahub.optimizer
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.catalyst.expressions.{Add, Expression, Literal}
import org.apache.spark.sql.catalyst.plans.logical.LogicalPlan
import org.apache.spark.sql.catalyst.rules.Rule
object MyOptimizer extends Rule[LogicalPlan] {
def apply(logicalPlan: LogicalPlan): LogicalPlan = {
logicalPlan.transformAllExpressions {
case Add(left, right) => {
println("this this my add optimizer")
if (isStaticAdd(left)) {
right
} else if (isStaticAdd(right)) {
Add(left, Literal(3L))
} else {
Add(left, right)
}
}
}
}
private def isStaticAdd(expression: Expression): Boolean = {
expression.isInstanceOf[Literal] && expression.asInstanceOf[Literal].toString == "0"
}
def main(args: Array[String]): Unit = {
System.setProperty("hadoop.home.dir","E:\\devlop\\envs\\hadoop-common-2.2.0-bin-master");
val testSparkSession: SparkSession = SparkSession.builder().appName("Extra optimization rules")
.master("local[*]")
.withExtensions(extensions => {
extensions.injectOptimizerRule(session => MyOptimizer)
})
.getOrCreate()
testSparkSession.sparkContext.setLogLevel("ERROR")
import testSparkSession.implicits._
testSparkSession.experimental.extraOptimizations = Seq()
Seq(-1, -2, -3).toDF("nr").write.mode("overwrite").json("./test_nrs")
// val optimizedResult = testSparkSession.read.json("./test_nrs").selectExpr("nr + 0")
testSparkSession.read.json("./test_nrs").createTempView("p")
var sql = "select nr+0 from p";
var t = testSparkSession.sql(sql)
println(t.queryExecution.optimizedPlan)
println(sql)
t.show()
sql = "select 0+nr from p";
var u = testSparkSession.sql(sql)
println(u.queryExecution.optimizedPlan)
println(sql)
u.show()
sql = "select nr+8 from p";
var v = testSparkSession.sql(sql)
println(v.queryExecution.optimizedPlan)
println(sql)
v.show()
// println(optimizedResult.queryExecution.optimizedPlan.toString() )
// optimizedResult.collect().map(row => row.getAs[Long]("(nr + 0)"))
Thread.sleep(1000000)
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
执行如下
this this my add optimizer
this this my add optimizer
this this my add optimizer
Project [(nr#12L + 3) AS (nr + CAST(0 AS BIGINT))#14L]
+- Relation[nr#12L] json
select nr+0 from p
this this my add optimizer
this this my add optimizer
this this my add optimizer
+------------------------+
|(nr + CAST(0 AS BIGINT))|
+------------------------+
| 2|
| 1|
| 0|
+------------------------+
this this my add optimizer
Project [nr#12L AS (CAST(0 AS BIGINT) + nr)#21L]
+- Relation[nr#12L] json
select 0+nr from p
this this my add optimizer
+------------------------+
|(CAST(0 AS BIGINT) + nr)|
+------------------------+
| -1|
| -2|
| -3|
+------------------------+
this this my add optimizer
this this my add optimizer
this this my add optimizer
Project [(nr#12L + 8) AS (nr + CAST(8 AS BIGINT))#28L]
+- Relation[nr#12L] json
select nr+8 from p
this this my add optimizer
this this my add optimizer
this this my add optimizer
+------------------------+
|(nr + CAST(8 AS BIGINT))|
+------------------------+
| 7|
| 6|
| 5|
+------------------------+
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
扩展策略
SparkStrategies包含了一系列特定的Strategies,这些Strategies是继承自QueryPlanner中定义的Strategy,它定义接受一个Logical Plan,生成一系列的Physical Plan
通过Strategies把逻辑计划转换成可以具体执行的物理计划,代码如下
package wang.datahub.strategy
import org.apache.spark.sql.{SparkSession, Strategy}
import org.apache.spark.sql.catalyst.plans.logical.LogicalPlan
import org.apache.spark.sql.execution.SparkPlan
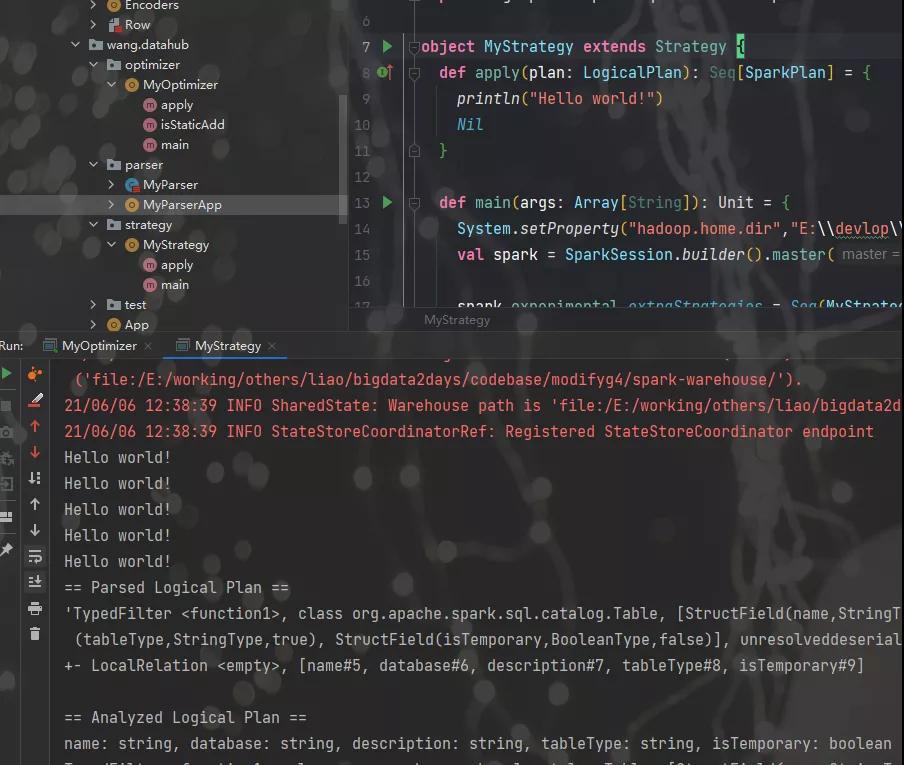
object MyStrategy extends Strategy {
def apply(plan: LogicalPlan): Seq[SparkPlan] = {
println("Hello world!")
Nil
}
def main(args: Array[String]): Unit = {
System.setProperty("hadoop.home.dir","E:\\devlop\\envs\\hadoop-common-2.2.0-bin-master");
val spark = SparkSession.builder().master("local").getOrCreate()
spark.experimental.extraStrategies = Seq(MyStrategy)
val q = spark.catalog.listTables.filter(t => t.name == "six")
q.explain(true)
spark.stop()
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
执行效果
好了,扩展部分就先介绍到这,接下来我计划可能会简单说说RBO和CBO,结合之前做过的一个小功能,一条SQL的查询时间预估。
本文转载自微信公众号「麒思妙想」,可以通过以下二维码关注。转载本文请联系麒思妙想公众号。