本文转载自微信公众号「大鱼仙人」,作者大鱼。转载本文请联系大鱼仙人公众号。
眼光不错,小伙子,看到这篇文章了就血赚,这篇文章绝对让你学到开心,这是面试的杀器,其实Redis这个东西吧,我个人认为,真的真的很强大,但是呢,又感觉被吹得有点过头了
不过人家也确实有这个资本,人家性能强大,使用操作也很简单,有提供了各种持久化手段来解决断电丢失的问题,而且人家读写速度都是大几万每秒,甚至十几万的速度,性能强大而且使用简单,所以绝大多数的公司都会使用Redis
于是乎,Redis的面试的优先级也是被大大的提高了,而Redis中的经典的缓存的各种问题,也是成为了程序员的必备技能之一
缓存雪崩、缓存穿透和缓存击穿都是属于比较典型的问题,当然这篇文章就是为了给大家解释清楚这三者到底是怎么回事,还有一般情况下如何来解决相应的问题,当然这篇也没有什么很特殊的厉害的法子,相应的法子估计百度也是一大堆
不过呢,相见既缘分,你看到这篇文章了,我当然要给亲爱的大家准备一篇最齐全的解决法子咯,帮助大家真正的了解并学会解决这些问题
缓存雪崩
不过呢,相见既缘分,你看到这篇文章了,我当然要给亲爱的大家准备一篇最齐全的解决法子咯,帮助大家真正的了解并学会解决这些问题
雪崩,这个词听着就很糟糕,可能很多人已经猜到了个大概了,这指的就是大面积的缓存集体失效
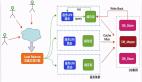
举个典型的例子,在写入本文的时候,比如马上到618的时候,就会很快迎来了一波大促销,大抢购,就是因为访问量特别的高,所以要把这些商品都放在缓存中提高效率,假设这一个页面的数据都缓存了一个小时,那么到了凌晨一点钟的时候,这些商品的缓存就都会过期了,而对这批商品的访问,就都落在了DB上,这样DB就会很容易崩溃
当一点的时候每秒八千个请求,本来缓存可以挺住五千每秒的请求,但是当缓存突然失效的时候,这每秒八千的请求直接全都打在DB上,数据库直接就扛不住了,没准直接就挂了,此时如果没用什么特别的方案来处理这个故障,DBA也容易崩溃,重启数据库,但是会立即被下面的流量打崩
这就是我个人理解的缓存雪崩
同一时间的缓存大面试失效,对于线上的情况来说,应该会是一个灾难,如果你这么做了,恭喜你,埋下了一个大雷,你想想啊,如果DB直接崩了,那意味着用户可能要开始***了,这个时候用户都是熬夜熬了很久等着购买自己心爱的产品呢,结果你软件崩了,啥也买不了了
什么,连我辛苦好几天抢的券都不能用了,什么破软件,卸载,再也不用了,如果真出现这样的场景,收拾东西吧
说的不错,这是个大问题,那一般这种情况该如何处理呢,你都是如何应对的
其实处理这个也很简单了,在批量的往Redis中放置数据的时候,把每个key的失效时间都加个相应的随机值即可

这样就可以避免大面积的缓存数据在同一时间失效这个问题,公司一般使用Redis都是集群部署的,这样将热点数据均匀分布在不同的Redis库中也可以避免全部失效的问题,失效时间设为随机有时候也是一种不错的策略
或者设置热点数据永远不过期,有更新操作就直接更新缓存就好了,看到数据A的缓存过期了,再重新缓存下,数据B的缓存过期了,再重新缓存下B,这样也可以刷下缓存就好了
缓存穿透和缓存击穿
我们先来说下缓存穿透,缓存穿透指的是缓存和数据库都没有的数据,然而用户却不断的发起请求,这样的很可能是就是属于恶意请求
举个例子,我们数据库的ID都是自增上去的,如果发起者的ID为-1的情况,或者ID不存在的特别大的情况,这时候的用户很可能是攻击者,造成数据库的攻击压力会变得很大,严重的可能会导致直接打崩DB
其实这种情况,程序员一般会对这种恶意情况进行过滤,但是万一有漏洞呢,万一有程序员忘记了对参数进行校验,这种情况如果一直用小于0的参数去请求你,每次都能绕开Redis直接打到DB,数据库查不到,每次都这样,并发高点可能就会容易搞崩,一些小的单机系统,基本上用postman可能就能打崩
至于缓存击穿吗,这个和缓存雪崩有点像,但是肯定也是有不一样的地方,缓存雪崩是因为大面积的缓存失效,打崩了DB,而缓存击穿不同的是缓存击穿指的是一个Key非常热点,比如之前的某爽这种事情,占用公共资源的眼球,人们都去喷,此时这个Key就是一个大热点,在不停的扛着大并发,大并发集中的对这一个点进行访问,当这个key在失效的那一瞬间,也就是某爽的这个key突然失效了,持续的大并发就会直接穿破缓存,直接将请求打到DB,就像是在一个完好无损的桶上凿开了一个洞
那该如何解决呢,缓存穿透和击穿这两种情况
缓存穿透吗,这个是程序员必须要做的防备之一,接口层的校验,比如参数的校验、用户的鉴权行为这种,对于那些不合法的请求直接return或者报错就好了
我们在开发的时候,不仅要把用户的行为各种猜测,我们还要做的是提防各种恶意请求,我们要对程序的各个接口有一颗不信任的心,这个不信任指的是对于参数的各种情况、对于用户行为的多方面考虑,因为你不能确定来的请求一定是正常的,不能保证调用方一定是正常的调用方,所以一定要对那些非正常的调用方进行一定的校验和处理
缓存穿透这种需要在代码中根据业务的实际情况来做出相应的控制,对不符合条件的请求做出相应的过滤,这应该属于做基本的要求之一,如果这种情况真出现在生产上,那肯定属于T1级别的重大Bug了
我们常用的法子就是先从缓存中取数据,如果缓存中取不到就直接通过数据库来取数据,如果取不到,我们可以将key和value都是null写入到缓存中,设置一定的时间,可以有效的防止恶意用户反复用同一个ID来暴力攻击,其实我们也可以在网关层做出相应的控制,因为用户不可能在短时间内做出大量的多次请求的,当出现非正常频率的请求的IP或者机器的时候,可以对这些IP和机器进行限制
缓存击穿这种问题,其实最简单的办法就是设置缓存永不过期就好了,这应该是最简单粗暴的方法了,或者通过互斥锁也是可以解决这种
布隆过滤器
在redis中其实还有一个高级点的用法,布隆过滤器Bloom Filter,这个也可以很好的防止缓存穿透的发生,可以说这个就是为了防止这种情况而出生,利用极小的空间可以表示出大量的数据是否存在,但是这个是有一定的缺点的,缺点就是会存在一定的误判率
布隆过滤器可以利用其高效的数据结构和算法快速的判断出你操作的这个key在数据库中是否存在,不存在直接return就好了,也就不用达到DB了,这样就可以很好的避免缓存穿透的问题
即使很多IP同时发起攻击,其实正常的redis集群也是顶得住的,小公司一般用的也是小的redis集群,不过一般他们也不感兴趣对这些公司
简单说下布隆过滤器的原理吧
布隆过滤器,首先想的是啥,你肯定想到的是为啥叫这个名字,玩过lol的小伙伴,肯定第一时间脑海里冒出来的是这个吧
图片
经常玩辅助位置的小伙伴更是喜闻乐见,看见了这个春心开始荡漾了,于是忍不住打开了桌面的lol,点击了play,打完一把感觉队友很气,于是又开了一把...
好了好了,玩笑归玩笑,来理解下这个布隆过滤器吧,我这里只是粗略的说一下原理,不详细的解释
布隆过滤器:一个很大的bit数组组成,系统在初始化的时候,会把数据库已经存在的商品的ID通过哈希再映射到bit数组的位置上,最后便可以通过数组上相应的位置的值是否正确即可判断是否存在商品
这样说,可能有些晦涩
举个例子:现在有一个很大的bit位数组,初始化全部位置为0
数据库中存在商品1、2、3,然后我们有16个哈希函数,把1经过16个哈希函数映射得到16个哈希值,这16个哈希值会对应bit数组的16个位置,置为1;同样的操作对2、3,也都会产生16个哈希值,也就是对应32个哈希位置,也都置为1;
最后会最多产生48个位置,为什么说是最多呢,因为1、2、3的映射可能会映射到同一个位置,所以说最极限的情况就是会产生48个位置的1
此时如果恶意请求携带商品为-1的请求打过来,也会对-1进行相应的操作,于是得到16个哈希值,对应bit数组中的16个位置,我们可以通过判断这16个位置是否全是1来判断数据库中是否存在-1这个商品
你可能也看出来了,这样会存在一定的误判率,也就是存在一种极限情况,1、2、3产生的所有位置的映射值已经将-1的16个位置全部置为1了,当然这种情况也是比较少见的

一句话概述:有0一定不存在,但是全部为1,并不一定存在,所以存在一定的误判率
不错啊,小伙子,经过这么多轮的盘问,看来你对redis掌握的还可以
谢谢面试官的夸奖,请问offer什么时候能发到我的email里呢,毕竟我已经快一个多月没有上班,没有工资了,对于打工人来说,没有工资是很难办的
而且我这副业也还在起步阶段,还在慢慢的写,如果大家都能给个点赞给个关注,我也可以靠这个来恰点饭,这样也不用这么着急要offer,也可以多面试几轮,多给大家扯扯淡了(疯狂暗示)
懂了,接下来我再问问你的设计模式这块,就差不多了,因为我们公司对设计编码这块要求比较高,所以需要考察考察你的编码设计能力
好嘞,没问题,多谢面试官给透漏下一次的面试重点,我回去也好好准备准备
强行暗示下一系列
总结
其实这些问题算是类似的问题,也算是比较常见的问题,不要把这三个搞混了,这些问题应该是面试的香饽饽了,很多面试官都会问,即使不问,如果你能引出这些,并且给面试官讲解请求,那面试官对你的好感也会大大增加
我们对于redis一般就是从三个时间段来解决各种问题的:
1、Redis高可用,哨兵、主从架构、集群,避免全盘直接崩溃的那种,这种主要是避免灾难性的事故
2、过程中,本地ehcache缓存,Hystrix限流和降级来解决高流量,避免大流量直接打崩DB
3、之后的redis持久化:RDB和AOF,重启自动加载数据,快速恢复缓存数据,合理的配置可以做到几乎零丢失数据