













本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
还在担心大语言模型“啥都吃”,结果被用假信息训练了?
放在以前,这确实是训练NLP模型时值得担心的一个难题。
现在,谷歌从根本上解决了这个问题。
他们做了个名为TEKGEN的AI模型,直接将知识图谱用“人话”再描述一遍,生成语料库,再喂给NLP模型训练。
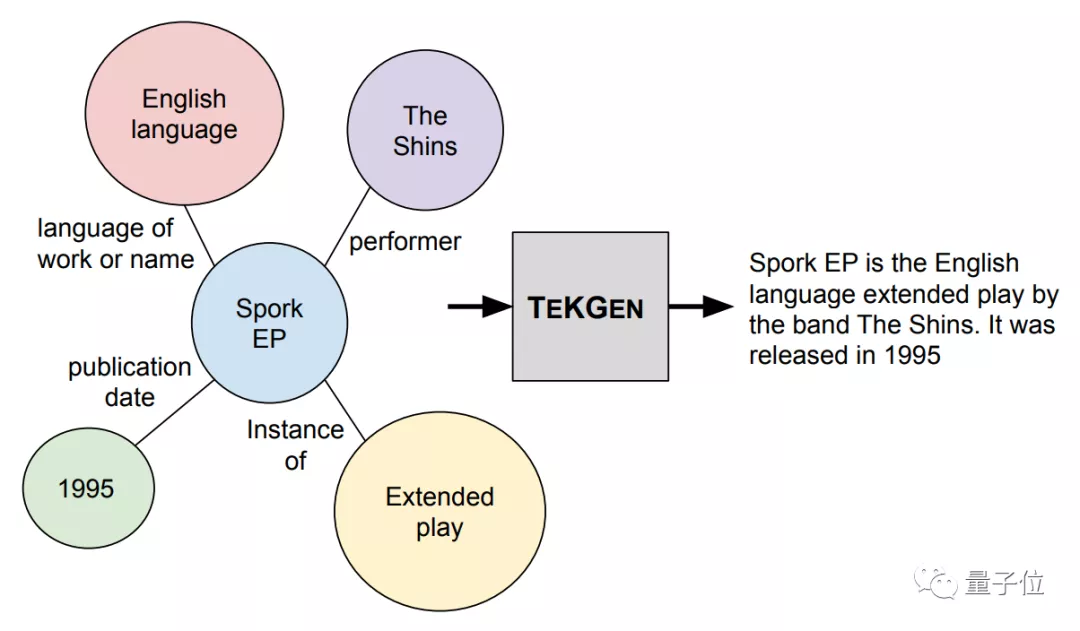
这是因为,知识图谱的信息来源往往准确靠谱,而且还会经过人工筛选、审核,质量有保障。
目前,这项研究已经被NAACL 2021接收。

如何让AI用“人话”描述知识图谱?
谷歌用来描述知识图谱的TEKGEN模型,全名Text from KG Generator(知识图谱文本生成器)。
它会读取一个知识图谱中的所有词语,捋清它们之间的关系,再用“人话”说出来。
从下图中来看,转换语句分为2步:
首先,将关系图谱中的词语,按逻辑进行排列;然后,再添加一些词语、并调整语句间的逻辑关系,将它们变成一段完整的话。
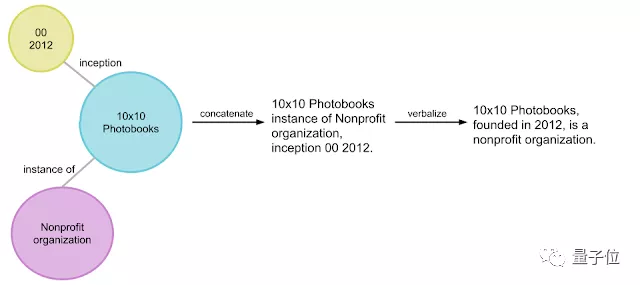
为了实现这个功能,TEKGEN包含4个部分:
- 三元组(包含主语、宾语、关系词)生成器。将维基百科的知识图谱、和维基百科文本描述进行对应,生成训练数据集。
- T5的文本-文本生成器,用于将三元组转换成文本信息。
- 实体子图创建器。用于将三元组中的文本信息转换成语句。
- 语义质量滤波器。这部分用来处理低质量的输出,保证生成的语句质量。
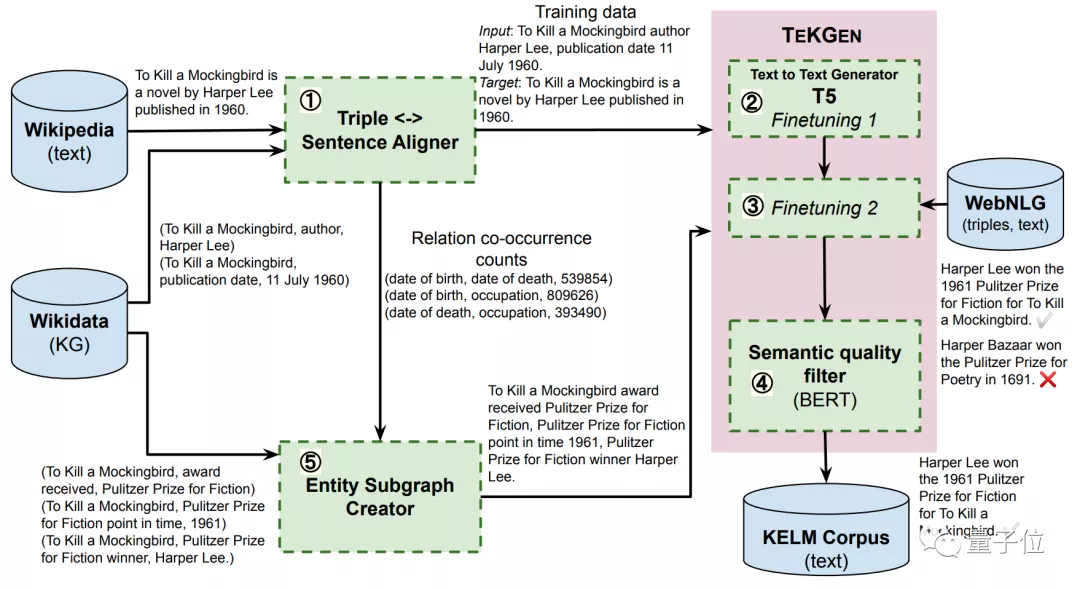
整体来看,用TEKGEN生成语句的流程是这样的:

生成后的语句,就能用来放心地训练大语言模型了。
这份生成的语料库,由4500万个三元组生成,组合起来的句子有1600万句。

那么,用这个语料库训练的NLP模型,是否真能取得更好的效果呢?
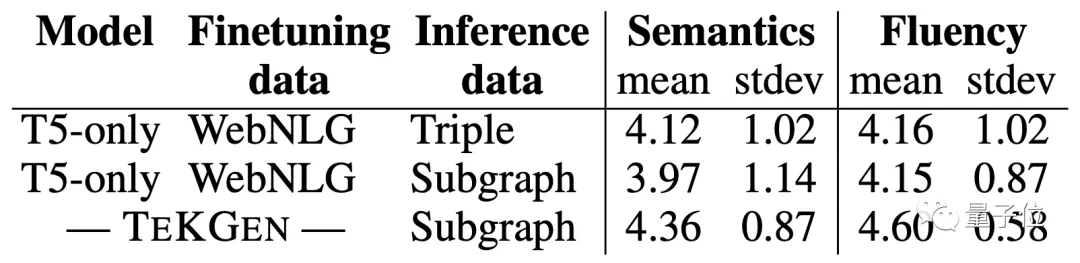
“满分5分,人类给它4.3分”
先来看几个连词成句的实例效果。
从输入的词语来看,只有主语、宾语,以及这两个词语之间的关系。
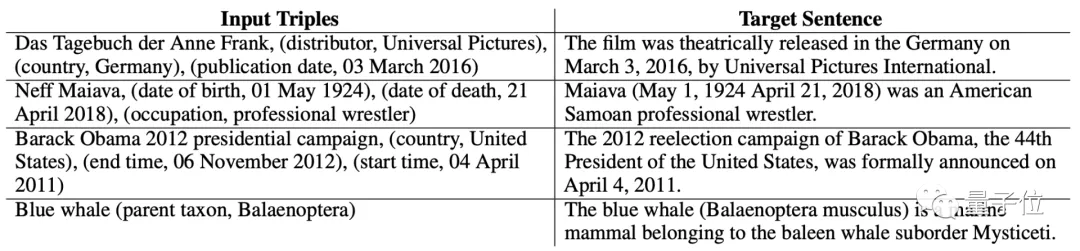
但TEKGEN似乎“悟”出了什么,很快就将这些句子组合成了一段正常的语句。
不仅时间、地点、从属关系等分得非常清楚,逻辑上也符合我们平时说话的语序。
那么,满分5分的话,人类对于AI的“图文转换”能力给出几分呢?
谷歌找了些志愿者来进行测评,从结果来看,TEKGEN在“语义”和“流畅度”两方面,均取得了4.3分以上的好成绩。
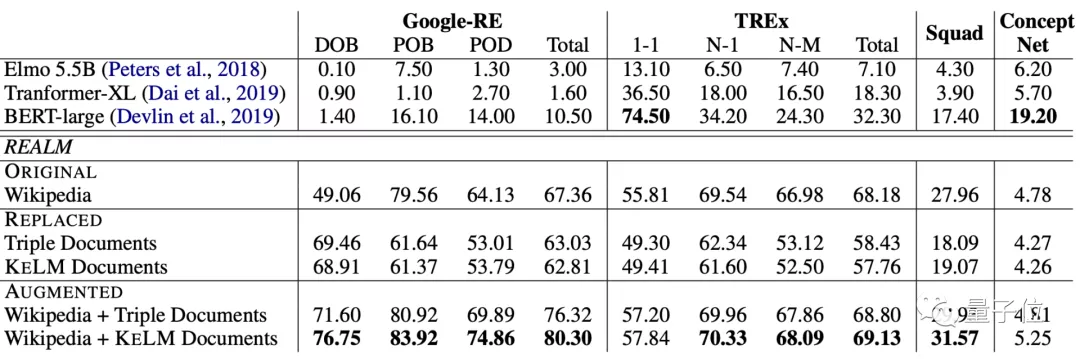
当然,这里面也用LAMA(LAnguage Model Analysis) probe,来对用这个语料库训练的模型进行了评估。
在Google-RE和TREx两个数据集上,经过预训练的模型,在各项任务上均取得了非常好的效果。
说不定,将来真能让AI去试试高考语文的“图文转换”题:
作者介绍
论文一作小姐姐Oshin Agarwal,是宾夕法尼亚大学的计算机系在读博士生,研究方向是自然语言处理中的信息抽取。
这篇论文,是她在谷歌实习期间完成的。
来自谷歌的Heming Ge、Siamak Shakeri和Rami Al-Rfou也参与了这项工作。
目前,作者们已经将这个用知识图谱生成的语料库放了出来。
想要训练NLP模型的小伙伴,可以用起来了~
论文地址:
https://arxiv.org/abs/2010.12688
用知识图谱生成的语料库:
https://github.com/google-research-datasets/KELM-corpus























