"协程是轻量级的线程",相信大家不止一次听到这种说法。但是您真的理解其中的含义吗?恐怕答案是否定的。接下来的内容会告诉大家协程是如何在 Android 运行时中被运行的,它们和线程之间的关系是什么,以及在使用 Java 编程语言线程模型时所遇到的并发问题。
协程和线程
协程旨在简化异步执行的代码。对于 Android 运行时的协程,lambda 表达式的代码块会在专门的线程中执行。例如,示例中的 斐波那契 运算:
- // 在后台线程中运算第十级斐波那契数
- someScope.launch(Dispatchers.Default) {
- val fibonacci10 = synchronousFibonacci(10)
- saveFibonacciInMemory(10, fibonacci10)
- }
- private fun synchronousFibonacci(n: Long): Long { /* ... */ }
上面 async 协程的代码块,会被分发到由协程库所管理的线程池中执行,实现了同步且阻塞的斐波那契数值运算,并且将结果存入内存,上例中的线程池属于 Dispatchers.Default。该代码块会在未来某些时间在线程池中的某一线程中执行,具体执行时间取决于线程池的策略。
请注意由于上述代码中未包含挂起操作,因此它会在同一个线程中执行。而协程是有可能在不同的线程中执行的,比如将执行部分移动到不同的分发器,或者在使用线程池的分发器中包含带有挂起操作的代码。
如果不使用协程的话,您还可以使用线程自行实现类似的逻辑,代码如下:
- // 创建包含 4 个线程的线程池
- val executorService = Executors.newFixedThreadPool(4)
- // 在其中的一个线程中安排并执行代码
- executorService.execute {
- val fibonacci10 = synchronousFibonacci(10)
- saveFibonacciInMemory(10, fibonacci10)
- }
虽然您可以自行实现线程池的管理,但是我们仍然推荐使用协程作为 Android 开发中首选的异步实现方案,它具备内置的取消机制,可以提供更便捷的异常捕捉和结构式并发,后者可以减少类似内存泄漏问题的发生几率,并且与 Jetpack 库集成度更高。
工作原理
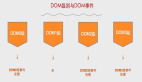
从您创建协程到代码被线程执行这期间发生了什么呢?当您使用标准的协程 builder 创建协程时,您可以指定该协程所运行的 CoroutineDispatcher,如果未指定,系统会默认使用 Dispatchers.Default。
CoroutineDispatcher 会负责将协程的执行分配到具体的线程 。在底层,当 CoroutineDispatcher 被调用时,它会调用封装了 Continuation (比如这里的协程) interceptContinuation 方法来拦截协程。该流程是以 CoroutineDispatcher 实现了 CoroutineInterceptor 接口作为前提。
如果您阅读了我之前的关于 协程在底层是如何实现 的文章,您应该已经知道了编译器会创建状态机,以及关于状态机的相关信息 (比如接下来要执行的操作) 是被存储在 Continuation 对象中。
一旦 Continuation 对象需要在另外的 Dispatcher 中执行,DispatchedContinuation 的 resumeWith 方法会负责将协程分发到合适的 Dispatcher。
此外,在 Java 编程语言的实现中,继承自 DispatchedTask 抽象类的 DispatchedContinuation 也属于 Runnable 接口的一种实现类型。因此,DispatchedContinuation 对象也可以在线程中执行。其中的好处是当指定了 CoroutineDispatcher 时,协程就会转换为 DispatchedTask,并且作为 Runnable 在线程中执行。
那么当您创建协程后,dispatch 方法如何被调用呢?当您使用标准的协程 builder 创建协程时,您可以指定启动参数,它的类型是 CoroutineStart。例如,您可以设置协程在需要的时候才启动,这时可以将参数设置为 CoroutineStart.LAZY。默认情况下,系统会使用 CoroutineStart.DEFAULT 根据 CoroutineDispatcher 来安排执行时机。

分发器和线程池
您可以使用 Executor.asCoroutineDispatcher() 扩展函数将协程转换为 CoroutineDispatcher 后,即可在应用中的任何线程池中执行该协程。此外,您还可以使用协程库默认的 Dispatchers。
您可以看到 createDefaultDispatcher 方法中是如何初始化 Dispatchers.Default 的。默认情况下,系统会使用 DefaultScheduler。如果您看一下 Dispatcher.IO 的实现代码,它也使用了 DefaultScheduler,支持按需创建至少 64 个线程。Dispatchers.Default 和 Dispatchers.IO 是隐式关联的,因为它们使用了同一个线程池,这就引出了我们下一个话题,使用不同的分发器调用 withContext 会带来哪些运行时的开销呢?
线程和 withContext 的性能表现
在 Android 运行时中,如果运行的线程比 CPU 的可用内核数多,那么切换线程会带来一定的运行时开销。上下文切换 并不轻松!操作系统需要保存和恢复执行的上下文,而且 CPU 除了执行实际的应用功能之外,还需要花时间规划线程。除此之外,当线程中所运行代码阻塞的时候也会造成上下文切换。如果上述的问题是针对线程的,那么在不同的 Dispatchers 中使用 withContext 会带来哪些性能上的损失呢?
还好线程池会帮我们解决这些复杂的操作,它会尝试尽量多地执行任务 (这也是为什么在线程池中执行操作要优于手动创建线程)。协程由于被安排在线程池中执行,所以也会从中受益。基于此,协程不会阻塞线程,它们反而会挂起自己的工作,因而更加有效。
Java 编程语言中默认使用的线程池是 CoroutineScheduler 。它以最高效的方式将协程分发到工作线程。由于 Dispatchers.Default 和 Dispatchers.IO 使用相同的线程池,在它们之间切换会尽量避免线程切换。协程库会优化这些切换调用,保持在同一个分发器和线程上,并且尽量走捷径。
由于 Dispatchers.Main 在带有 UI 的应用中通常属于不同的线程,所以协程中 Dispatchers.Default和 Dispatchers.Main 之间的切换并不会带来太大的性能损失,因为协程会挂起 (比如在某个线程中停止执行),然后会被安排在另外的线程中继续执行。
协程中的并发问题
协程由于其能够简单地在不同线程上规划操作,的确使得异步编程更加轻松。但是另一方面,便捷是一把双刃剑: 由于协程是运行在 Java 编程语言的线程模型之上,它们难以逃脱线程模型所带来的并发问题。因此,您需要注意并且尽量避免该问题。
近年来,像不可变性这样的策略相对减轻了由线程所引发的问题。然而,有些场景下,不可变性策略也无法完全避免问题的出现。所有并发问题的源头都是状态管理!尤其是在一个多线程环境下访问可变的状态。
在多线程应用中,操作的执行顺序是不可预测的。与编译器优化操作执行顺序不同,线程无法保证以特定的顺序执行,而上下文切换会随时发生。如果在访问可变状态时没有采取必要的防范措施,线程就会访问到过时的数据,丢失更新,或者遇到 资源竞争 问题等等。
请注意这里所讨论的可变状态和访问顺序并不仅限于 Java 编程语言。它们在其它平台上同样会影响协程执行。
使用了协程的应用本质上就是多线程应用。使用了协程并且涉及可变状态的类必须采取措施使其可控,比如保证协程中的代码所访问的数据是最新的。这样一来,不同的线程之间就不会互相干扰。并发问题会引起潜在的 bug,使您很难在应用中调试和定位问题,甚至出现 海森堡 bug。
这一类型的类非常常见。比如该类需要将用户的登录信息缓存在内存中,或者当应用在活跃状态时缓存一些值。如果您稍有大意,那么并发问题就会乘虚而入!使用 withContext(defaultDispatcher) 的挂起函数无法保证会在同一个线程中执行。
比如我们有一个类需要缓存用户所做的交易。如果缓存没有被正确访问,比如下面代码所示,就会出现并发问题:
- class TransactionsRepository(
- private val defaultDispatcher: CoroutineDispatcher = Dispatchers.Default
- ) {
- private val transactionsCache = mutableMapOf<User, List<Transaction>()
- private suspend fun addTransaction(user: User, transaction: Transaction) =
- // 注意!访问缓存的操作未被保护!
- // 会出现并发问题:线程会访问到过期数据
- // 并且出现资源竞争问题
- withContext(defaultDispatcher) {
- if (transactionsCache.contains(user)) {
- val oldList = transactionsCache[user]
- val newList = oldList!!.toMutableList()
- newList.add(transaction)
- transactionsCache.put(user, newList)
- } else {
- transactionsCache.put(user, listOf(transaction))
- }
- }
- }
即使我们这里所讨论的是 Kotlin,由 Brian Goetz 所编撰的《Java 并发编程实践》对于了解本文主题和 Java 编程语言系统是非常好的参考材料。此外,Jetbrains 针对 共享可变的状态和并发 的主题也提供了相关的文档。
保护可变状态
对于如何保护可变状态,或者找到合适的 同步 策略,取决于数据本身和相关的操作。本节内容启发大家注意可能会遇到的并发问题,而不是简单罗列保护可变状态的方法和 API。总而言之,这里为大家准备了一些提示和 API 可以帮助大家针对可变变量实现线程安全。
封装
可变状态应该属于并被封装在类里。该类应该将状态的访问操作集中起来,根据应用场景使用同步策略保护变量的访问和修改操作。
线程限制
一种方案是将读取和写入操作限制在一个线程里。可以使用队列基于生产者-消费者模式实现对可变状态的访问。Jetbrains 对此提供了很棒的 文档。
避免重复工作
在 Android 运行时中,包含线程安全的数据结构可供您保护可变变量。比如,在计数器示例中,您可以使用 AtomicInteger。又比如,要保护上述代码中的 Map,您可以使用 ConcurrentHashMap。ConcurrentHashMap 是线程安全的,并且优化了 map 的读取和写入操作的吞吐量。
请注意,线程安全的数据结构并不能解决调用顺序问题,它们只是确保内存数据的访问是原子操作。当逻辑不太复杂的时候,它们可以避免使用 lock。比如,它们无法用在上面的 transactionCache 示例中,因为它们之间的操作顺序和逻辑需要使用线程并进行访问保护。
而且,当已修改的对象已经存储在这些线程安全的数据结构中时,其中的数据需要保持不可变或者受保护状态来避免资源竞争问题。
自定义方案
如果您有复合的操作需要被同步,@Volatile 和线程安全的数据结构也不会有效果。有可能内置的 @Synchronized 注解的粒度也不足以达到理想效果。
在这些情况下,您可能需要使用并发工具创建您自己的同步机制,比如 latches、semaphores 或者 barriers。其它场景下,您可以使用 lock 和 mutex 无条件地保护多线程访问。
Kotlin 中的 Mute 包含挂起函数 lock 和 unlock,可以手动控制保护协程的代码。而扩展函数 Mutex.withLock 使其更加易用:
- class TransactionsRepository(
- private val defaultDispatcher: CoroutineDispatcher = Dispatchers.Default
- ) {
- // Mutex 保护可变状态的缓存
- private val cacheMutex = Mutex()
- private val transactionsCache = mutableMapOf<User, List<Transaction>()
- private suspend fun addTransaction(user: User, transaction: Transaction) =
- withContext(defaultDispatcher) {
- // Mutex 保障了读写缓存的线程安全
- cacheMutex.withLock {
- if (transactionsCache.contains(user)) {
- val oldList = transactionsCache[user]
- val newList = oldList!!.toMutableList()
- newList.add(transaction)
- transactionsCache.put(user, newList)
- } else {
- transactionsCache.put(user, listOf(transaction))
- }
- }
- }
- }
由于使用 Mutex 的协程在可以继续执行之前会挂起操作,因此要比 Java 编程语言中的 lock 高效很多,因为后者会阻塞整个线程。在协程中请谨慎使用 Java 语言中的同步类,因为它们会阻塞整个协程所处的线程,并且引发 活跃度 问题。
传入协程中的代码最终会在一个或者多个线程中执行。同样的,协程在 Android 运行时的线程模型下依然需要遵循约束条件。所以,使用协程也同样会出现存在隐患的多线程代码。所以,在代码中请谨慎访问共享的可变状态。