Redis 的读写都是在内存中进行的,所以它的性能高。而当我们的服务器断开或者重启的时候,数据就会消失,那么我们该怎么解决这个问题呢?
其实 Redis 已经为我们提供了一种持久化的机制,分别是 RDB 和 AOF 两种方式,接下来跟着我一起看看这两个锦囊都是怎么保证数据的持久化的。
持久化
由于 Redis 是基于内存的数据库,所以当服务器出现故障的时候,我们的数据就得不到安全保障。
这个时候就需要将内存中的数据存储到磁盘中,当我们服务器重启时,便可以通过磁盘来恢复数据,这个过程就叫做 Redis 持久化。
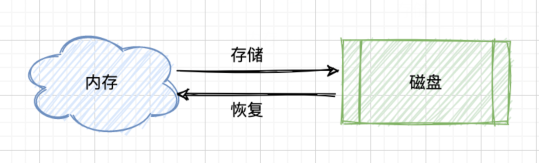
Redis持久化
RDB
简介
RDB全称Redis Database Backup file(Redis数据备份文件),也可以称为Redis数据快照。
- RDB 文件是一个经过压缩的二进制文件(默认:dump.rdb);
- RDB 文件保存在硬盘里;
- 通过保存数据库中的键值对来记录数据库状态。
创建
当 Redis 持久化时,程序会将当前内存中的数据库状态保存到磁盘中。
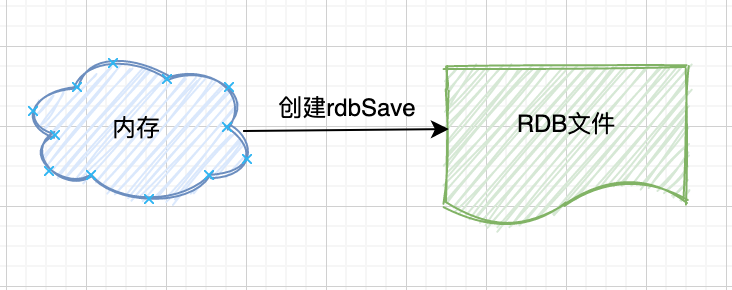
创建
创建 RDB 文件主要有两个 Redis 命令:SAVE 和 BGSAVE。
SAVE
同步操作,执行命令时,会阻塞 Redis 服务器进程,拒绝客户端发送的命令请求。
代码示例:
- def SAVE():
- # 创建 RDB 文件
- rdbSave()
图示:
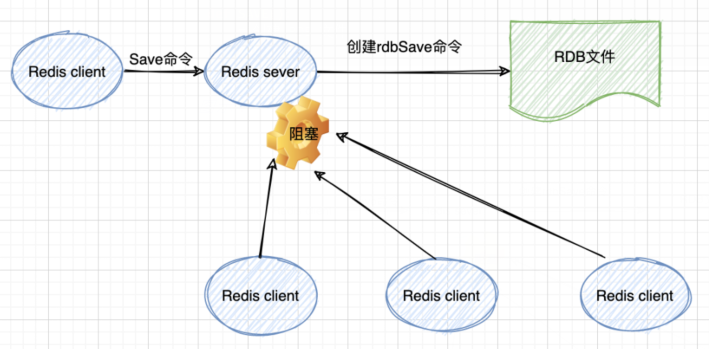
Save命令
BGSAVE
异步操作,执行命令时,子进程执行保存工作,服务器还可以继续让主线程处理客户端发送的命令请求。
代码示例:
- def BGSAVE():
- # 创建子进程
- pid = fork()
- if pid == 0:
- # 子进程负责创建 RDB 文件
- rdbSave()
- # 完成之后向父进程发送信号
- signal_parent()
- elif pid > 0:
- # 父进程继续处理命令请求,并通过轮训等待子进程的信号
- handle_request_and_wait_signal()
- else:
- handle_fork_error()
图示:
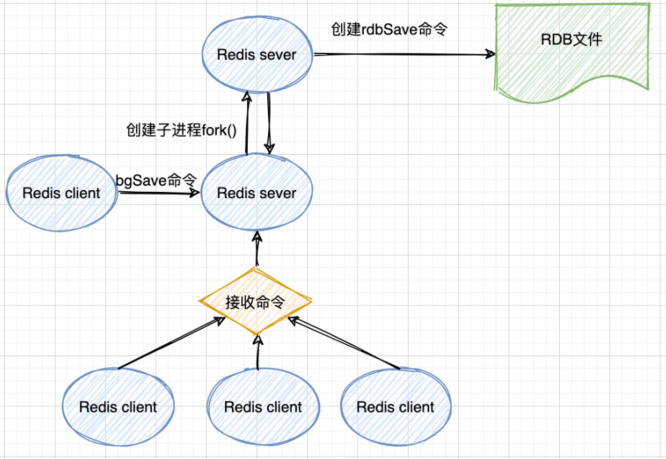
bgSave命令
载入
载入工作在服务器启动时自动执行。
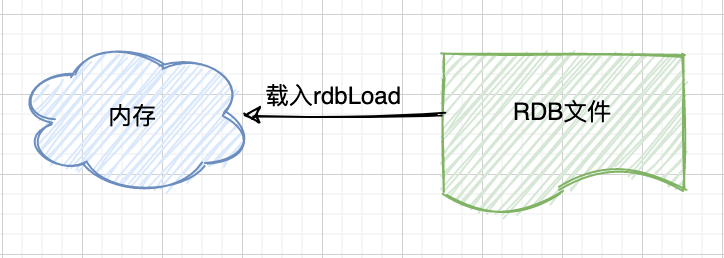
载入
服务器在载入 RDB 文件期间,会一直处于阻塞状态,直到载入工作完成为止。
主要设置
Redis 允许用户通过设置服务器配置的 save 选项,让服务器每隔一段时间自动执行一次 BGSAVE 命令。
设置保存条件
提供配置如下:
- save 900 1
- save 300 10
在这种情况下,只要满足以下条件中的一个,BGSAVE 命令就会被执行:
- 服务器在 900 秒之内,对数据库进行了至少 1 次修改了;
- 服务器在 300 秒之内,对数据库进行了至少 10 次修改。
saveparams
服务器程序会根据 save 选项所设置的保存条件,设置服务器状态 redisServer 结构的 saveparams 属性。
- saveparams 属性是一个数组;
- 数组中的每一个元素都是一个 saveparam 结构;
- 每个 saveparam 结构都保存了一个 save 选项设置的保存条件。
- struct saveparam {
- // 秒数
- time_t seconds;
- // 修改数
- int changes;
- }
dirty
dirty 计数器记录距离上一次成功执行 SAVE 命令或 BGSAVE 命令之后,服务器对数据库状态进行了多少次修改(包括写入、删除、更新等操作)。
lastsave
是一个 UNINX 时间戳,记录了服务器上一次成功执行 SAVE 命令或者 BGSAVE 命令的时间。
检查保存条件是否满足
服务器周期性操作函数 serverCron (该函数对正在运行的服务器进行维护)默认每隔 100 毫秒就会执行一次,其中一项工作就是检查 save 选项所设置的保存条件是否已经满足,满足的话就执行 BGSAVE 命令。
代码示例:
- def serverCron():
- # ....
- # 遍历所有保存条件
- for saveparam in server.saveparams:
- # 计算距离上次执行保存操作有多少秒
- save_interval = unixtime_now() - server.lastsave
- # 如果数据库状态的修改次数超过条件所设置的次数
- # 如果距离上次保存的时间超过条件所设置的时间
- if server.dirty >= saveparam.changes and save_interval > saveparam.seconds:
- BGSAVE()
默认配置
RDB 文件默认的配置如下:
- ################################ SNAPSHOTTING ################################
- #
- # Save the DB on disk:
- #在给定的秒数和给定的对数据库的写操作数下,自动持久化操作。
- # save <seconds> <changes>
- #
- save 900 1
- save 300 10
- save 60 10000
- #bgsave发生错误时是否停止写入,一般为yes
- stop-writes-on-bgsave-error yes
- #持久化时是否使用LZF压缩字符串对象?
- rdbcompression yes
- #是否对rdb文件进行校验和检验,通常为yes
- rdbchecksum yes
- # RDB持久化文件名
- dbfilename dump.rdb
- #持久化文件存储目录
- dir ./
AOF
简介
AOF全称为 Append Only File(追加日志文件)。日志是写后日志,Redis 是先执行命令,把数据写入内存,然后才记录日志。
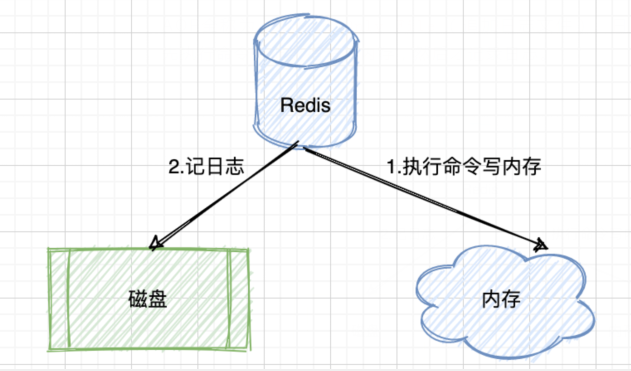
写后日志
- 通过保存 Redis 服务器所执行的写命令来记录数据库状态;
- 写入 AOF 文件的所有命令都是以 Redis 的命令请求协议格式保存的。
实现
AOF 持久化流程实现主要是通过以下流程来实现的:

AOF流程
命令追加
若 AOF 持久化功能处于打开状态,服务器在执行完一个命令后,会以协议格式将被执行的写命令追加到服务器状态的 aof_buf 缓冲区的末尾。
文件同步
服务器每次结束一个事件循环之前,都会调用 flushAppendOnlyFile 函数,这个函数会考虑是否需要将 aof_buf 缓冲区中的内容写入和保存到 AOF 文件里。
flushAppendOnlyFile 函数执行以下流程:
- WRITE:根据条件,将 aof_buf 中的缓存写入到 AOF 文件;
- SAVE:根据条件,调用 fsync 或 fdatasync 函数,将 AOF 文件保存到磁盘中。
这个函数是由服务器配置的 appendfsync 的三个值:always、everysec、no来影响的,也被称为三种策略。
Always
每条命令都会 fsync 到硬盘中,这样 redis 的写入数据就不会丢失。
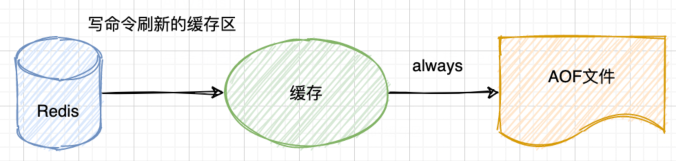
Always
everysec
每秒都会刷新缓冲区到硬盘中(默认值)。
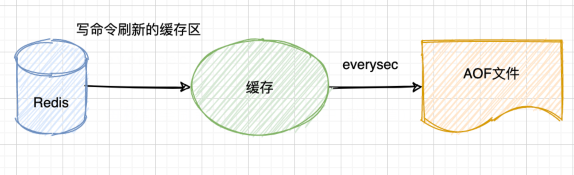
everysec
no
根据当前操作系统的规则决定什么时候刷新到硬盘中,不需要我们来考虑。
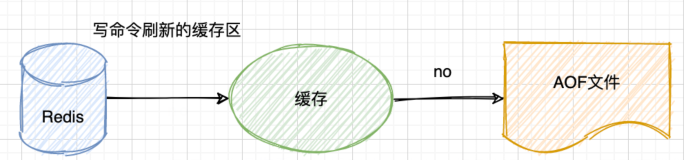
no
数据加载
- 创建一个不带网络连接的伪客户端;
- 从 AOF 文件中分析并读取出一条写命令;
- 使用伪客户端执行被读出的写命令;
- 一直执行步骤 2 和 3,直到 AOF 文件中的所有写命令都被处理完毕为止。
文件重写
为何需要文件重写:
- 为了解决 AOF 文件体积膨胀的问题;
- 通过重写创建一个新的 AOF 文件来替代现有的 AOF 文件,新的 AOF 文件不会包含任何浪费空间的冗余命令。
实现
文件重写的实现原理:
- 不需要对现有的 AOF 文件进行任何操作;
- 从数据库中直接读取键现在的值;
- 用一条命令记录键值对,从而代替之前记录这个键值对的多条命令。
后台重写
为不阻塞父进程,Redis 将 AOF 重写程序放到子进程里执行。
在子进程执行 AOF 重写期间,服务器进程需要执行三个流程:
- 执行客户端发来的命令;
- 将执行后的写命令追加到 AOF 缓冲区;
- 将执行后的写命令追加到 AOF 重写缓冲区。
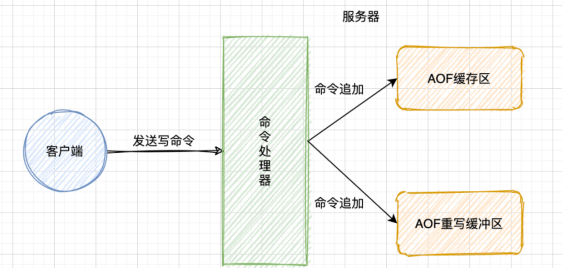
服务器流程
默认配置
AOF 文件默认的配置如下:
- ############################## APPEND ONLY MODE ###############################
- #开启AOF持久化方式
- appendonly no
- #AOF持久化文件名
- appendfilename "appendonly.aof"
- #每秒把缓冲区的数据fsync到磁盘
- appendfsync everysec
- # appendfsync no
- #是否在执行重写时不同步数据到AOF文件
- no-appendfsync-on-rewrite no
- # 触发AOF文件执行重写的增长率
- auto-aof-rewrite-percentage 100
- #触发AOF文件执行重写的最小size
- auto-aof-rewrite-min-size 64mb
- #redis在恢复时,会忽略最后一条可能存在问题的指令
- aof-load-truncated yes
- #是否打开混合开关
- aof-use-rdb-preamble yes
总结
通过以上的简介,想必大家都对 Redis 持久化有了大致的了解,那么这两种方式,我们该如何选择呢?
- 对于大中型的应用,我们既想保证数据完整性又想保证高效率,就应该结合使用 RDB 和 AOF 两种方式;
- 如果只是需要保证数据的完整性,保护数据不会丢失,那么优先使用 AOF 方式;
- 如果是处理大规模的数据恢复,追求更高更快的效率的话,优先使用 RDB 方式。
也可以参照下图进行选择:
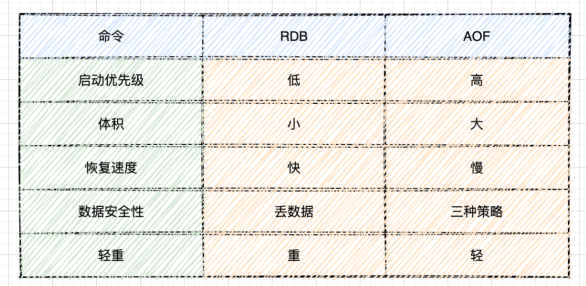
主要对比
本文转载自微信公众号「浅羽的IT小屋」,可以通过以下二维码关注。转载本文请联系浅羽的IT小屋公众号。