大家好,我是一哥,今天分享一篇数据实时入湖的干货文章。
在构建实时数仓的过程中,如何快速、正确的同步业务数据是最先面临的问题,本文主要讨论一下如何使用实时处理引擎Flink和数据湖Apache Iceberg两种技术,来解决业务数据实时入湖相关的问题。
01 Flink CDC介绍
CDC全称是Change Data Capture,捕获变更数据,是一个比较广泛的概念,只要是能够捕获所有数据的变化,比如数据库捕获完整的变更日志记录增、删、改等,都可以称为CDC。该功能被广泛应用于数据同步、更新缓存、微服务间同步数据等场景,本文主要介绍基于Flink CDC在数据实时同步场景下的应用。
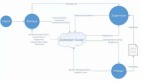
Flink在1.11版本开始引入了Flink CDC功能,并且同时支持Table & SQL两种形式。Flink SQL CDC是以SQL的形式编写实时任务,并对CDC数据进行实时解析同步。相比于传统的数据同步方案,该方案在实时性、易用性等方面有了极大的改善。下图是基于Flink SQL CDC的数据同步方案的示意图。
Oracle的变更日志的采集有多种方案,这里采用的Debezium实时同步工具作为示例,该工具能够解析Oracle的changlog数据,并实时同步数据到下游Kafka。Flink SQL通过创建Kafka映射表并指定 format格式为debezium-json,然后通过Flink进行解析后直接插入到其他外部数据存储系统,例如图中外部数据源以Apache Iceberg为例。
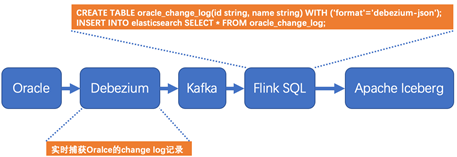
下面详细解析一下数据同步过程。首先了解一下Debezium抽取的Oracle的change log的格式,以update为例,变更日志上记录了更新之前的数据和更新以后的数据,在Kafka下游的Flink接受到这样的数据以后,一条update操作记录就转变为了先delete、后insert两条记录。日志格式如下所示,该update操作的内容的name字段从tom更新为了jerry。
{
"before": { --更新之前的数据
"id": 001,
"name": "tom"
},
"after": { --更新之后的数据
"id": 001,
"name": "jerry"
},
"source": {...},
"op": "u",
"ts_ms": 1589362330904,
"transaction": null
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
其次再来看一下Flink SQL内部是如何处理update记录的。Flink在1.11版本支持了完整的changelog机制,对于每条数据本身只要是携带了相应增、删、改的标志,Flink就能识别这些数据,并对结果表做出相应的增、删、改的动作,如下图所示changlog数据流经过Flink解析,同步到下游Sink Database。
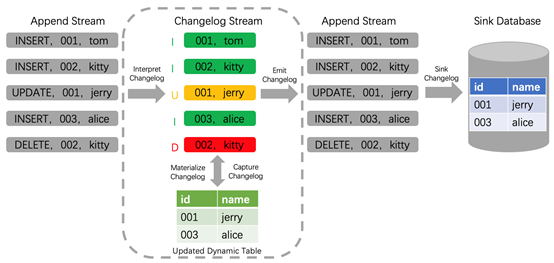
通过以上分析,基于Flink SQL CDC的数据同步有如下优点:
- 业务解耦:无需入侵业务,和业务完全解耦,也就是业务端无感知数据同步的存在。
- 性能消耗:业务数据库性能消耗小,数据同步延迟低。
- 同步易用:使用SQL方式执行CDC同步任务,极大的降低使用维护门槛。
- 数据完整:完整的数据库变更记录,不会丢失任何记录,Flink 自身支持 Exactly Once。
02 Apache Iceberg介绍
通常认为数据湖是一种支持存储多种原始数据格式、多种计算引擎、高效的元数据统一管理和海量统一数据存储。其中以Apache Iceberg为代表的表格式和Flink计算引擎组成的数据湖解决方案尤为亮眼。Flink社区方面也主动拥抱数据湖技术,当前Flink和Iceberg在数据入湖方面的集成度最高。
那么Apache Iceberg是什么呢?引用官网的定义是:Apache Iceberg is an open table format for huge analytic datasets。也就是Apache Iceberg是一个大规模数据分析的开放表格式。
Iceberg将数据分为元数据管理层和数据存储层。首先了解一下Iceberg在文件系统中的布局,第一部分是数据文件data files,用于存储具体业务数据,如下图中的data files文件。第二部分是表元数据文件(Metadata 文件),包含Snapshot文件、Manifest文件等。Snapshot表示当前操作的一个快照,每次commit都会生成一个快照,一个快照中包含多个Manifest,每个Manifest中记录了当前操作生成数据所对应的文件地址,也就是data files的地址。基于snapshot的管理方式,iceberg能够进行time travel(历史版本读取以及增量读取)。Iceberg文件系统设计特点如下图所示:
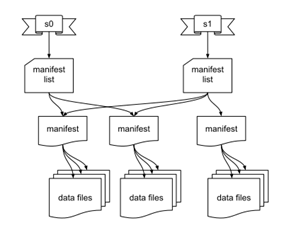
Iceberg的表格式设计具有如下特点:
- ACID:不会读到不完整的commit数据,基于乐观锁实现,支持并发commit,支持Row-level delete,支持upsert操作。
- 增量快照:Commit后的数据即可见,在Flink实时入湖场景下,数据可见根据checkpoint的时间间隔来确定的,增量形式也可回溯历史快照。
- 开放的表格式:对于一个真正的开放表格式,支持多种数据存储格式,如:parquet、orc、avro等,支持多种计算引擎,如:Spark、Flink、Hive、Trino/Presto。
- 流批接口支持:支持流式写入、批量写入,支持流式读取、批量读取。下文的测试中,主要测试了流式写入和批量读取的功能。
03 Flink CDC打通数据实时导入Iceberg实践
当前使用Flink最新版本1.12,支持CDC功能和更好的流批一体。Apache Iceberg最新版本0.11已经支持Flink API方式upsert,如果使用编写框架代码的方式使用该功能,无异于镜花水月,可望而不可及。本着SQL就是生产力的初衷,该测试使用最新Iceberg的master分支代码编译尝鲜,并对源码稍做修改,达到支持使用Flink SQL方式upsert。
先来了解一下什么是Row-Level Delete?该功能是指根据一个条件从一个数据集里面删除指定行。那么为什么这个功能那么重要呢?众所周知,大数据中的行级删除不同于传统数据库的更新和删除功能,在基于HDFS架构的文件系统上数据存储只支持数据的追加,为了在该构架下支持更新删除功能,删除操作演变成了一种标记删除,更新操作则是转变为先标记删除、后插入一条新数据。具体实现方式可以分为Copy on Write(COW)模式和Merge on Read(MOR)模式,其中Copy on Write模式可以保证下游的数据读具有最大的性能,而Merge on Read模式保证上游数据插入、更新、和删除的性能,减少传统Copy on Write模式下写放大问题。
在Apache Iceberg中目前实现的是基于Merge on Read模式实现的Row-Level Delete。在 Iceberg中MOR相关的功能是在Iceberg Table Spec Version 2: Row-level Deletes中进行实现的,V1是没有相关实现的。虽然当前Apache Iceberg 0.11版本不支持Flink SQL方式进行Row-Level Delete,但为了方便测试,通过对源码的修改支持Flink SQL方式。在不远的未来,Apache Iceberg 0.12版本将会对Row-Level Delete进行性能和稳定性的加强。
Flink SQL CDC和Apache Iceberg的架构设计和整合如何巧妙,不能局限于纸上谈兵,下面就实际操作一下,体验其功能的强大和带来的便捷。并且顺便体验一番流批一体,下面的离线查询和实时upsert入湖等均使用Flink SQL完成。
1,数据入湖环境准备
以Flink SQL CDC方式将实时数据导入数据湖的环境准备非常简单直观,因为Flink支持流批一体功能,所以实时导入数据湖的数据,也可以使用Flink SQL离线或实时进行查询。如下测试是使用Flink提供的sql-client完成的:
第一步,新建Kafka映射表,用于实时接收Topic中的changlog数据:
id STRING,
name STRING
) WITH (
'connector' = 'kafka',
'topic' = 'topic_name',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'debezium-json'
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
第二步,新建iceberg结果表,用于存储实时入湖的数据:
CREATE TABLE iceberg_catalog.default.IcebergTable ( id STRING, name STRING );
- 1.
注:
a)其中省略了配置catalog过程
b)当前iceberg 0.11默认创建表格式版本V1,通过代码更改版本为V2,以支持upsert方式导入数据湖
第三步,启动upsert方式实时入湖的Flink任务:
SET table.dynamic-table-options.enabled=true;
INSERT INTO IcebergTable /*+OPTIONS('equality-field-columns'='id')*/ SELECT * FROM KafkaTable;
- 1.
- 2.
- 3.
注:当前iceberg 0.11不支持Flink SQL形式upsert,通过修改源码达到支持配置指定字段更新功能。
第四步,离线或者实时查询统计IcebergTable表中的数据行数:
a)离线方式
SET execution.type=batch;
SELECT COUNT(*) FROM IcebergTable;
- 1.
- 2.
b)实时方式
SET execution.type=streaming;
SELECT COUNT(*) FROM IcebergTable;
- 1.
- 2.
- 3.
2,数据入湖速度测试
数据入湖速度测试会根据环境配置、参数配置、数据格式等不同有所不同,下面是列出主要配置和测试出的数据作为参考。
a)资源配置情况
TaskManager 内存4G,slot:1
Checkpoint 1分钟
测试数据列数 10列
测试数据行数 1000万
iceberg存储格式 parquet
- 1.
- 2.
- 3.
- 4.
- 5.
b)测试数据情况
数据入湖分为append和upsert两种方式。append方式只能新增数据,不能对结果数据进行更新操作;upsert方式即能够对结果数据更新。
append方式使用场景是导入数据之前已经明确该表数据不需要更新,如离线数据导入数据湖的场景,append方式下导入数据速度如下:
INSERT INTO IcebergTable SELECT * FROM KafkaTable;
并行度1 12.2万/秒
并行度2 19.6万/秒
并行度4 28.3万/秒
- 1.
- 2.
- 3.
- 4.
- 5.
update方式使用场景是既有插入的数据又有对之前插入数据的更新的场景,如数据库实时同步,upsert方式下导入数据速度,该方式需要指定在更新时以那个字段查找,类似于update语句中的where条件,一般设置为表的主键即可,如下:
INSERT INTO IcebergTable /*+OPTIONS('equality-field-columns'='id')*/ SELECT * FROM KafkaTable;
导入的数据 只有数据插入 只有数据更新
并行度1 3.2万/秒 2.9万/秒
并行度2 4.9万/秒 4.2万/秒
并行度4 6.1万/秒 5.1万/秒
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
c)结论
append方式导入速度远大于upsert导入数据速度。在使用的时候,如没有更新数据的场景时,则不需要upsert方式导入数据。
导入速度随着并行度的增加而增加。
upsert方式数据的插入和更新速度相差不大,主要得益于MOR原因。
3,数据入湖任务运维
在实际使用过程中,默认配置下是不能够长期稳定的运行的,一个实时数据导入iceberg表的任务,需要通过至少下述四点进行维护,才能使Iceberg表的入湖和查询性能保持稳定。
a)压缩小文件
Flink从Kafka消费的数据以checkpoint方式提交到Iceberg表,数据文件使用的是parquet格式,这种格式无法追加,而流式数据又不能等候太长时间,所以会不断commit提交数据产生小文件。目前Iceberg提供了一个批任务action来压缩小文件,需要定期周期性调用进行小文件的压缩功能。示例代码如下:
Table table = ...
Actions.forTable(table)
.rewriteDataFiles()
.targetSizeInBytes(100 * 1024 * 1024) // 100 MB
.execute();
- 1.
- 2.
- 3.
- 4.
- 5.
b)快照过期处理
iceberg本身的架构设计决定了,对于实时入湖场景,会产生大量的snapshot文件,快照过期策略是通过额外的定时任务周期执行,过期snapshot文件和过期数据文件均会被删除。如果实际使用场景不需要time travel功能,则可以保留较少的snapshot文件。
Table table = ...
Actions.forTable(table)
.expireSnapshots()
.expireOlderThan(System.currentTimeMillis())
.retainLast(5)
.execute();
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
c)清理orphan文件
orphan文件的产生是由于正常或者异常的数据写入但是未提交导致的,长时间积累会产生大量脱离元数据的孤立数据文件,所以也需要类似JVM的垃圾回收一样,周期性清理这些文件。该功能不需要频繁运行,设置为3-5天运行一次即可。
Table table = ...
Actions.forTable(table)
.removeOrphanFiles()
.execute();
- 1.
- 2.
- 3.
- 4.
d)删除元数据文件
每次提交snapshot均会自动产生一个新的metadata文件,实时数据入库会频繁的产生大量metadata文件,需要通过如下配置达到自动删除metadata文件的效果。
| Property | Description |
|---|---|
| write.metadata.delete-after-commit.enabled | Whether to delete old metadata files after each table commit |
| write.metadata.previous-versions-max | The number of old metadata files to keep |
4,数据入湖问题讨论
这里主要讨论数据一致性和顺序性问题。
Q1: 程序BUG或者任务重启等导致数据传输中断,如何保证数据的一致性呢?
Answer:数据一致保证通过两个方面实现,借助Flink实现的exactly once语义和故障恢复能力,实现数据严格一致性。借助Iceberg ACID能力来隔离写入对分析任务的不利影响。
Q2:数据入湖否可保证全局顺序性插入和更新?
Answer:不可以全局保证数据生产和数据消费的顺序性,但是可以保证同一条数据的插入和更新的顺序性。首先数据抽取的时候是单线程的,然后分发到Kafka的各个partition中,此时同一个key的变更数据打入到同一个Kafka的分区里面,Flink读取的时候也能保证顺序性消费每个分区中的数据,进而保证同一个key的插入和更新的顺序性。
04 未来规划
新的技术最终是要落地才能发挥其内在价值的,针对在实践应用中面临的纷繁复杂的数据,结合流计算技术Flink、表格式Iceberg,未来落地规划主要集中在两个方面,一是Iceberg集成到本行的实时计算平台中,解决易用性的问题;二是基于Iceberg,构建准实时数仓进行探索和落地。
1,整合Iceberg到实时计算平台
目前,我所负责的实时计算平台是一个基于SQL的高性能实时大数据处理平台,该平台彻底规避繁重的底层流计算处理逻辑、繁琐的提交过程等,为用户打造一个只需关注实时计算逻辑的平台,助力企业向实时化、智能化大数据转型。
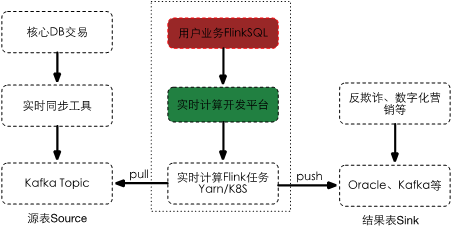
实时计算平台未来将会整合Apache Iceberg数据源,用户可以在界面配置Flink SQL任务,该任务以upsert方式实时解析changlog并导入到数据湖中。并增加小文件监控、定时任务压缩小文件、清理过期数据等功能。
2,准实时数仓探索
本文对数据实时入湖从原理和实战做了比较多的阐述,在完成实时数据入湖SQL化的功能以后,入湖后的数据有哪些场景的使用呢?下一个目标当然是入湖的数据分析实时化。比较多的讨论是关于实时数据湖的探索,结合所在企业数据特点探索适合落地的实时数据分析场景成为当务之急。
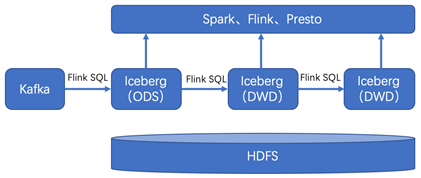
随着数据量的持续增大,和业务对时效性的严苛要求,基于Apache Flink和Apache Iceberg构建准实时数仓愈发重要和迫切,作为实时数仓的两大核心组件,可以缩短数据导入、方便数据行级变更、支持数据流式读取等。
本文转载自微信公众号「数据社」,可以通过以下二维码关注。转载本文请联系数据社公众号。