













1、概念介绍
MySQL:关系型数据库,主要面向OLTP,支持事务,支持二级索引,支持sql,支持主从、Group Replication架构模型(本文全部以Innodb为例,不涉及别的存储引擎)。
HBase:基于HDFS,支持海量数据读写(尤其是写),支持上亿行、上百万列的,面向列的分布式NoSql数据库。天然分布式,主从架构,不支持事务,不支持二级索引,不支持sql。ElasticSearch:简称ES是一款分布式的全文检索框架,底层基于Lucene技术实现,虽然ES也提供存储,检索功能,但我一直不认为ES是一款数据库,但是随着ES功能越来越强大,与数据库的界限也越来越模糊。分布式,P2P架构,但不支持事务,采用倒排索引提供全文检索。
2、数据存储方式
假设有这样一张人员信息表:
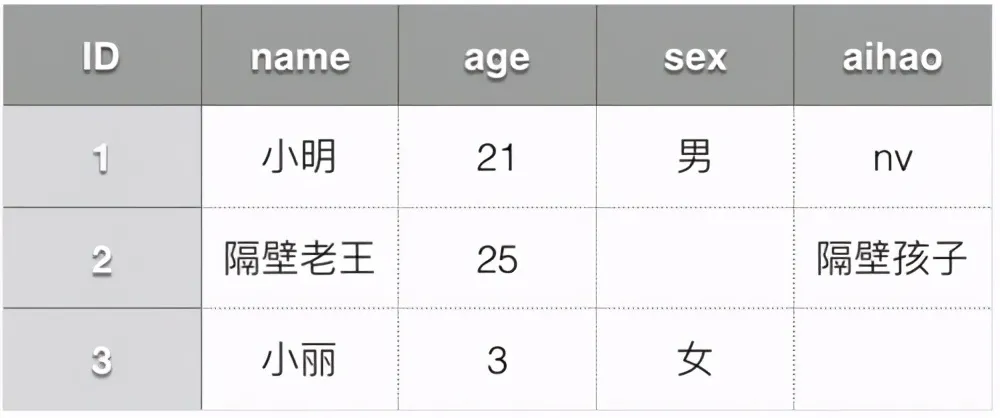
MySQL数据库要提前定义表结构,数据表共有多少列(属性)需要提前定义好,并且同时需要定义好每个列所占用的存储空间。数据以行为单位组织在一起的,假如某一行的某一列没有数据,也需要占用存储空间。
HBase则是以列为单位存储数据,每一列就是一个key-value,HBase的表列(属性)不需要提前定义,而且列可以动态扩展,比如人员信息表中需要添加一个新的“address”字段,MySQL需要提前alter表增加字段,HBase可以直接插入即可。
ES比较灵活,索引中的field类型可以提前定义(定义mapping),也可以不定义,如果不定义,会有一个默认类型,不过出于可控性考虑,关键字段建议提前定义好。(Solr中必须提前定义好schema.xml文件)
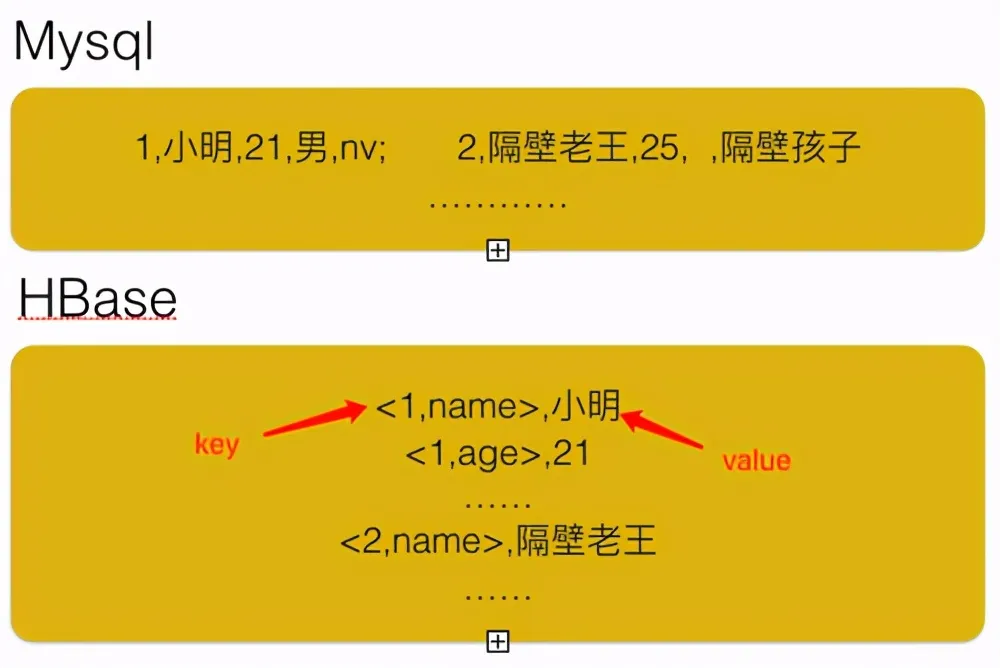
上图展示了数据在MySQL和HBase中存储差异(和真实的情况还有差距),可以看到即使第二条记录的sex字段为空,MySQL依然会为该字段保留空间,因为后续有可能会有update语句来更新该记录,补上sex内容。而HBase则是把每一列都看做是一条记录,row+列名作为key,data作为value,依次存放。假如某一行的某一个列没有数据,则直接跳过该列。针对稀疏矩阵的大表,HBase能大大节省存储空间。
看到这里,大家是否会有一个疑问:使用HBase存储时,假如此时需要添加第二行的sex内容,如何实现呢,数据是否连续?后面介绍读写流程会解释。
不一样的ES
ES的存储方式和上面两个都不一样,MySQL和HBase是将数据按不同的方式进行存储,好歹它们存的还是数据,而ES则存的是倒排索引。我们先来了解一下什么是倒排索引,以及为什么需要倒排索引(Inverted Index):我们肯定都会这样的经历:偶然看到一段很好的文字,但是却不知道出处,这时候去图书馆,一个一个翻找,无疑是大海捞针,这个时候便有了全文检索这项技术,而它最核心的就是倒排索引。假如有如下文档:

我们想要知道有哪些文档含有you这个关键字,首先可以创建一个倒排索引,格式如下:
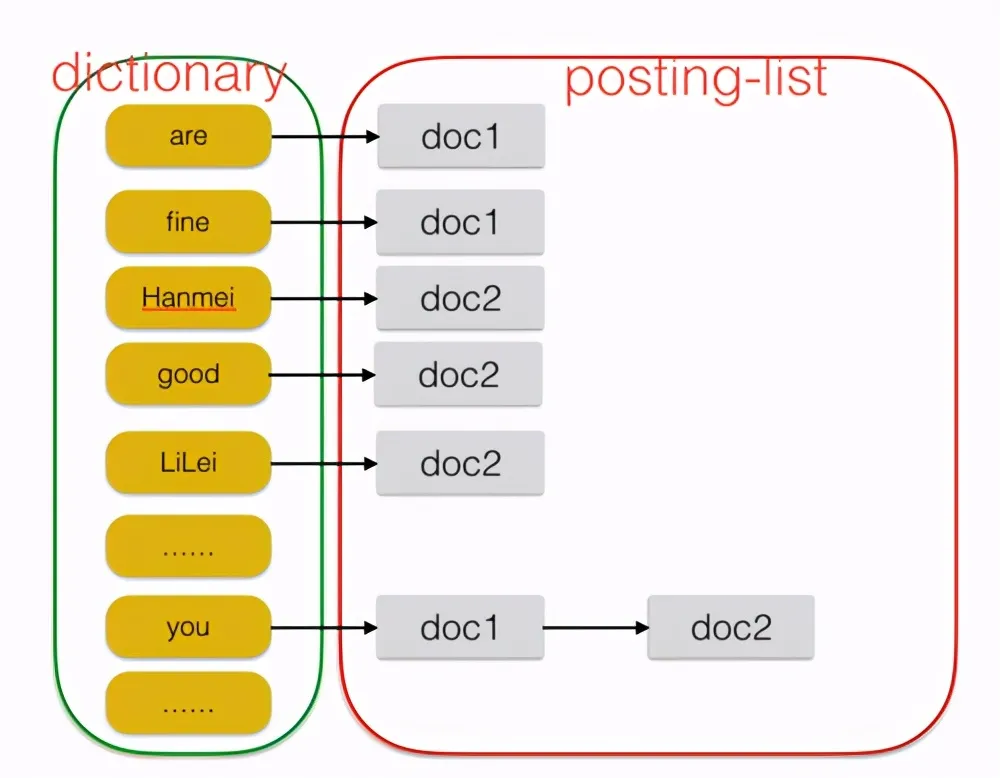
前面的部分叫做dictionary(字典),里面的每个单词叫做term,后面的文档列表叫做psoting-list,list中记录了所有含有该term的文档id,两个组合起来就是一个完成的倒排索引(Inverted Index)。能够看出,假如需要查找含有“you”的文档时,根据dictionary然后找到对应的posting-list即可。
而全文检索中,创建Inverted Index是最关键也是最耗时的过程,而且真正的Inverted Index结构也远比图中展示的复杂,不仅需要对文档进行分词(ES里中文可以自定义分词器),还要计算TF-IDF,方便评分排序(当查找you时,评分决定哪个doc显示在前面,也就是所谓的搜索排名),压缩等操作。每接收一个document,ES就会将其信息更新在倒排索引中。
可以看出ES和MySQL、HBase的存储还是有很大的区别。而且ES不仅包含倒排索引,默认同时还会把文档doc存储起来,所以当我们使用ES时,也能拿到完整的文档信息,所以某种程度上,感觉就像在使用数据库一样,但是也可以配置不存储文档信息,这时只能根据查询条件得到文档id,并不能拿到完整的文档内容。
总结:
MySQL:行存储的方式比较适合OLTP业务。HBase:列存储的方式比较适合OLAP业务,而HBase采用了列族的方式平衡了OLTP和OLAP,支持水平扩展,如果数据量比较大、对性能要求没有那么高、并且对事务没有要求的话,HBase可以考虑。ES:ES默认对所有字段都建了索引,所以比较适合复杂的检索或全文检索。
3、容灾对比
3.1 MySQL
单节点:
现在的数据库普遍采用write ahead log策略来避免数据丢失,wal机制简单的解释就是:在提交CUD操作,数据写入内存的同时,也要写一份到log文件中,而且要保证log数据落盘成功后才能向client返回操作成功,假如此时数据库宕机,已经提交到内存的数据还没来得及刷回磁盘,重启数据库后可以通过回放log文件来恢复内存中的数据。
问题又来了:写log的话,对性能影响会不会很大?其实多少还是有点影响的,不过log文件是顺序写入,相对来说为了保证数据完整性,这点性能损失还是可以接受的。
单机情况下,MySQL的innodb通过redo log和checkpoint机制来保证数据的完整性。因为怕log越写越大,占用过多磁盘,而且当log特别大的时候,恢复起来也比较耗时。而checkpoint的出现就是为了解决这些问题。
checkpoint机制保证了之前的log数据一定已经刷回磁盘,当数据库宕机时,只需要将checkpoint之后的log回放即可,数据库会定时做checkpoint,这样就保证了数据库恢复的效率。
但是考虑到如果硬件故障时机器无法启动,或者磁盘故障时数据无法恢复,checkpoint+redo log方案也就不起作用了,为了防止这种故障,MySQL还提供了master-slave和group replication 集群级别的容灾方案。
Master-Slave架构主要思路是:master负责业务的读写请求,然后通过binlog复制到slave节点,这样如果主库因为不可抗拒因素无法恢复时,从库可以提供服务,这里我们用了“复制“这个词,而不是”同步“,因为基于binlog复制的方案并不能做到主从数据强一致,这种主从同步方式会导致主库挂掉之后从库有可能丢失少量的数据。
正是因为主从架构存在数据不一致的问题,所以MySQL5.7出现了Mysql Group Replication方案,mgr采用paxos协议实现了数据节点的强同步,保证了所有节点都可以写数据,并且所有节点读到的也是最新的数据。
3.2 HBase
HBase的容灾和MySQL的单机容灾有些类似,但具体实现上还是很有自己的特点。
在介绍HBase容灾前,我们先来了解一下HBase和HDFS的关系:HBase中的数据都是存放在HDFS上,可以简单理解HBase分为两层:
一层为NoSql service(即提供分布式检索服务)
一层是分布式文件系统(数据真正存放的位置,目前采用HDFS)。HBase中region分布在不同的regionserver上,client端通过meta表来定位数据在在哪个regionserver的region上,然后获取数据,但是数据有可能并不一定在该regionserver本地保存,每个region都知道自己对应的数据在HDFS的哪些数据块上,最后通过访问HDFS来获取数据,尤其当HBase和HDFS部署在不同的集群上时,数据的读写完全是通过RPC来实现,为了减少RPC的开销,保证服务稳定,往往会将HBase和HDFS部署在同一个集群。
同理,当一个regionserver挂了,region可以快速切换到别的regionserver上,因为只涉及到回放Log,并不会移动已经落盘的数据,而且HBase也会控制log的大小,来减少恢复时间。
HBase也是采用写log的方式防止数据丢失,数据写内存的同时,同时也会写入HLog,HLog也是存储在HDFS上,写入HLog后才会认为数据写成功,某个regionserver挂掉之后,master将故障机器上的regions调度到别的regionserver上,regionserver通过回放HLog来恢复region的数据,恢复成功后,region重新上线,由于log是直接写在HDFS上,所以不用担心单个节点挂掉log数据丢失的问题。
这里引出一个问题:回放HLog的时候,正在被恢复的region会短时间不可用,直到HLog回放成功。HBase1.0版本中加入了region replicas功能,也就是提供一个slave region,当主region挂掉的时候,依然可以通过slave replicas来读数据,但是slave不提供write,而且slave replicas和primary region并不是强同步的,并不一定总能读到最新的数据,所以开启该功能时,也要考虑自己业务是否必须要求强一致。
HBase也提供了cluster replication,目的是为了做机房级的容灾,boss说现在cluster replication功能还有些bug,目前也在积极优化改进,相信以后会cluster replication会越来越完善。
3.3 ES:
ES的容灾也是采用写log的方式,与HBase不同的是,ES的节点保存各自的log,这点跟MySQL类似,log是存放在本地的,这也就存在和MySQL一样的问题,假如机器宕机或硬盘故障,log数据也会丢失,所以index每个shard也有主备,默认配置是一个primary shard,一个replica shard,当然也可以配置多个replica。
默认情况下:primary shard首先接收client端发送过来的数据,然后将数据同步到replica shard中,当replica shard也写入成功后,才会告知client数据已正确写入,这样就防止数据还没写入replica shard时,primary挂掉导致的数据丢失。
又到了提问环节,如果有一个replica节点出了问题,比如网络故障无法写入,那岂不是数据一直写入不成功了?所以ES的master维护了一个in-sync set,里面保存了目前存活、且与primary同步的replica集合,只要set中的replica同步完成即认为数据写入成功。考虑到一种情况:所有的replica因为网络故障都下线了,in-sync set此时为空,数据只在primary中保留一份,很有可能因primary故障而导致丢数据,所以ES新增了wait_for_active_shards参数,只有当存活的replica数大于该参数时,才能正常写入,若不满足,则停止写服务。
(这是5.X版本的实现,由于ES版本更新过快,这和2.X之前的版本有些差异,5.X中in-sync set的方式和Kafka的容灾模式非常类似,但和Kafka有一点区别:ES的primary负责写服务,但是primary和replica都可以提供读服务,而Kafka只有primary partition提供读写服务,replica只是同步primary上的数据,并不提供读。
4、读写方式
4.1 Mysql
MySQL的Innodb中的数据是按主键的顺序依次存放,主键即为聚簇索引(对聚簇索引和非聚簇索引不了解同学可以看看这篇文章),索引采用B+树结构进行组织。
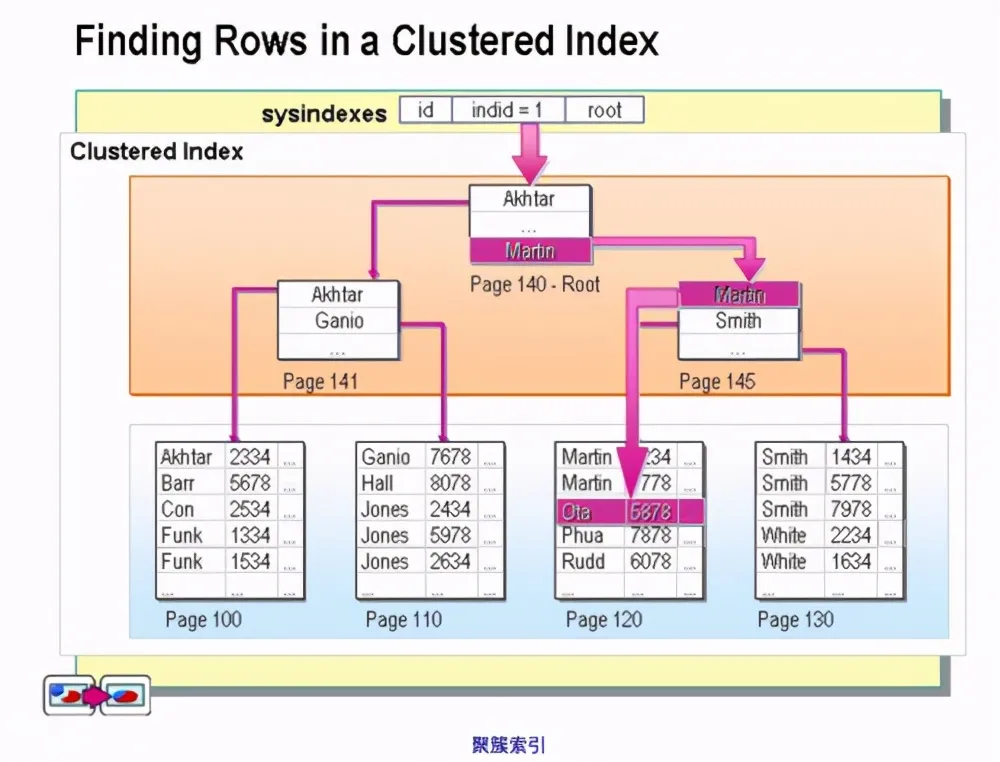
从图中可以看出,数据是按聚簇索引顺序依次存放,假设下面一些场景:
1.查询
Innodb中主键即为聚簇索引,假如根据主键查询,聚簇索引的叶子节点存放就是真正的数据,可以直接查到相应的记录。假如是二级索引查询,那么需要先通过二级索引找到该记录的主键,然后根据主键通过聚簇索引找到对应的记录,这里多了一个索引查找的过程。
2.插入
顺序插入:因为Innodb的数据是按聚簇索引的顺序依次存放的,如果是根据主键索引的顺序插入,即插入的数据的主键是连续的,因为是顺序io,所以插入效率会较高。
随机插入:假如每次插入的数据主键是不连续的,MySQL需要取出每条记录对应的物理block,会引起大量的随机io,随机io操作和顺序io的性能差距很大,尤其是机械盘。
(Kafka官网提到一个机械盘的顺序写能达到600M/s,而随机写可能只有100k/s。As a result the performance of linear writes on aJBODconfiguration with six 7200rpm SATA RAID-5 array is about 600MB/sec but the performance of random writes is only about 100k/sec—a difference of over 6000X.这也是为什么HBase、ES将所有的insert、update、delete操作都统一看成顺序写操作,避免随机io)
note:这也是为什么MySQL的主键通常定义为自增id,不涉及业务逻辑,这样新数据插入时能保证是顺序io。另外MySQL为了提高随机io的性能,提供了insert buffer的功能。
3.更新 & 删除
update和delete如果不是顺序的话,也会包含大量的随机io,当然MySQL都针对随机io都进行了一些优化,尽量减少随机io带来的性能损失。
4.2 HBase
HBase不支持二级索引,它只有一个主键索引,采用LSM树。
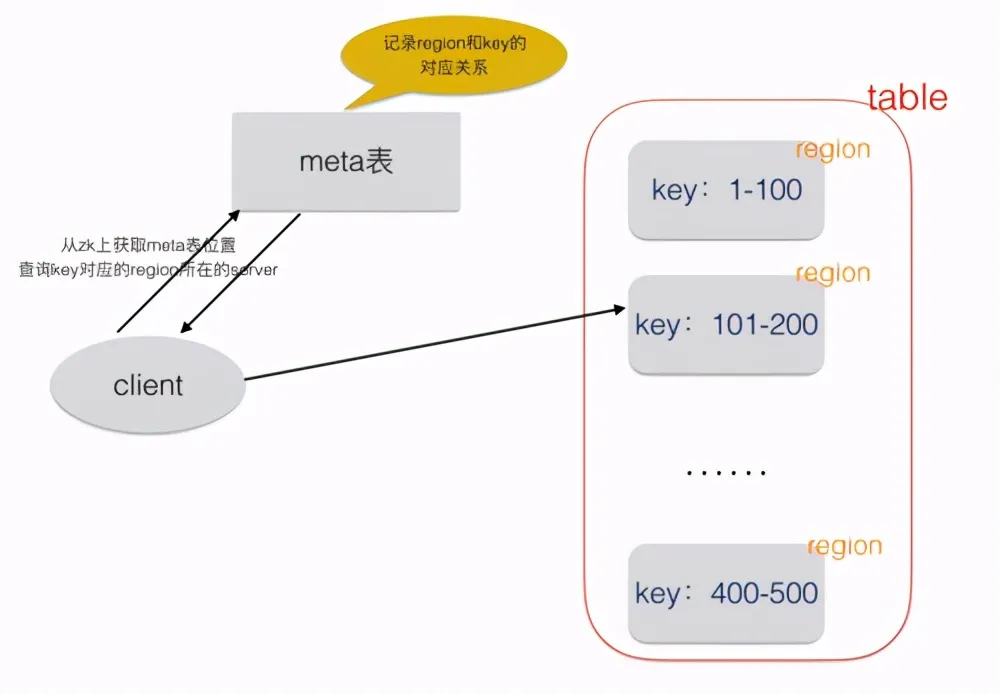
HBase是一个分布式系统,这点跟MySQL不同,它的数据是分散不同的server上,每个table由一个或多个region组成,region分散在集群中的server上,一个server可以负责多个region。这里有一点需要特别注意:table中各个region的存放数据的rowkey(主键)范围是不会重叠的,可以认为region上数据基于rowkey全局有序,每个region负责它自己的那一部分的数据。
1.查询
假如我们要查询rowkey=150的这条记录,首先从zk中获取hbase:meta表(存放region和key的对应关系的元数据表)的位置,通过查询meta表得知rowkey=150的数据在哪个server的哪个region上。
2.插入
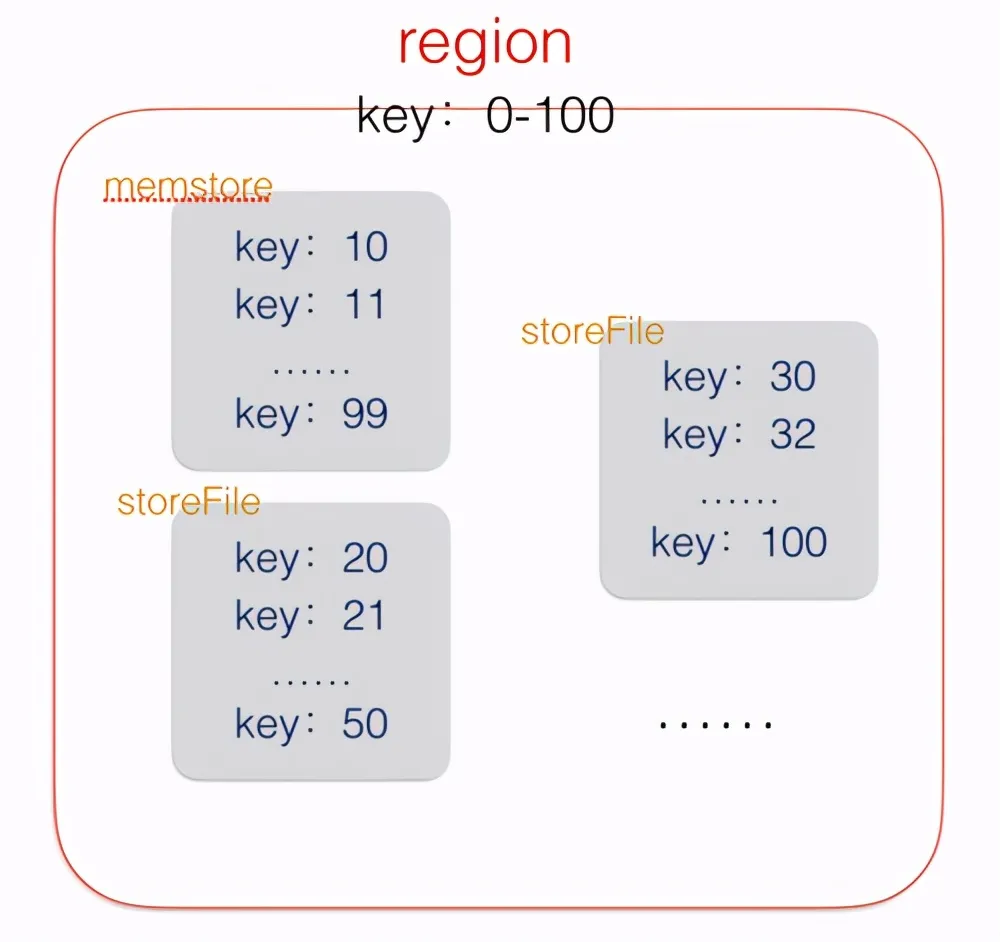
上图粗略的展示了HBase的region的结构,region不单单是一个文件,它是由一个memstore和多个storeFile组成(storeFile上的上限可以配置)。插入数据时首先将数据写入memstore,当memstore大小达到一定阈值,将memstore flush到硬盘,变成一个新的storeFile。flush的时候会对memstore中的数据进行排序,压缩等操作。可以看到单个storeFile中的数据是有序的,但是region中的storeFile间的数据不是全局有序的。
这样有的好处就是:不管主键是否连续,所有的插入一律变成顺序写,大大提高了写入性能。
看到这里大家可能会有一个疑问:这种写入方式导致了一条记录如果不是一次性插入,很可能分散在不同的storeFile中,那在该region上面查询一条记录时,怎么知道去找哪个storeFile呢?答案就是:全部查询。HBase会采用多路归并的方式,对该region上的所有storeFile进行查询,直到找到符合条件的记录。所以HBase的拥有很好的写入性能,但是读性能较差。
当然HBase也做了很多优化,比如每个storeFile都有自己的index、用于过滤的bloom filter、compaction:按可配置的方式将多个storeFile合并成一个,减少检索时打开的文件数。
3.更新 & 删除
HBase将更新和删除也全部看做插入操作,用timestamp和delete marker来区分该记录是否是最新记录、是否需要删除。也正是因为这样,除了查询,其他的操作统一转换成了顺序写,保证了HBase高效的写性能。
4.3 ES
ES的也是一个分布式系统,与ES类似的还有一个叫Solr的项目,都是基于Lucene的全文检索分布式框架,有兴趣的可以去Lucene官网了解,这里就不做对比了。
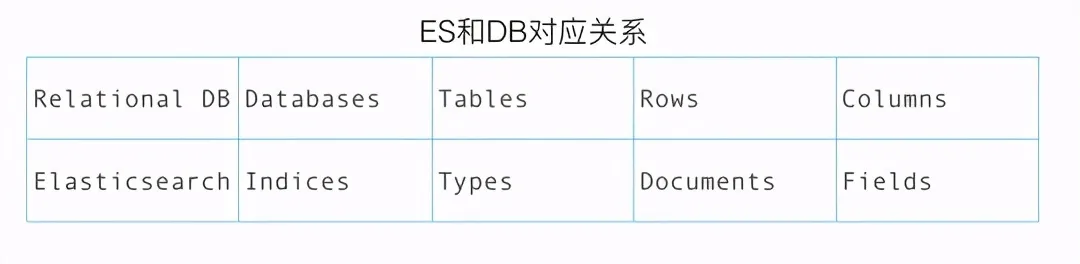
上如展示了ES和传统数据库的概念对比。下面的介绍中,统一使用index对应DB中table,doc对应table中的记录,field对应row中的一列。
ES集群由一个或多个node组成,一个node即为一个ES服务进程。一个index由多个分片shard组成,shard分散在各个node上面,每个shard都采用Lucene来创建倒排索引,维护各自的索引数据。
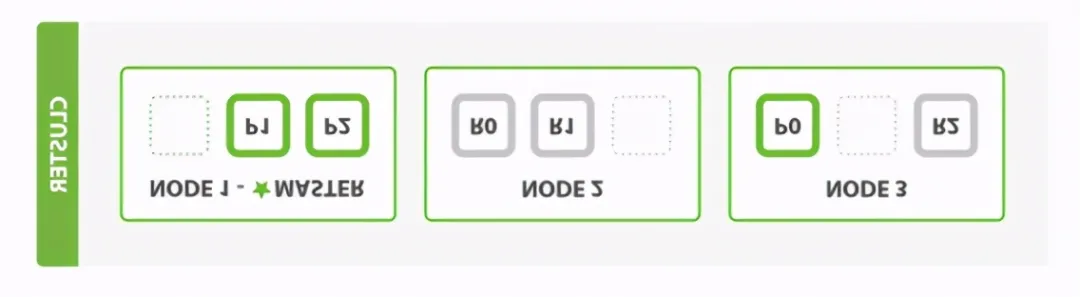
图中的一个小方框即为一个shard,出于容灾考虑,每个shard都会有多副本,副本个数可以配置,默认为2,绿色的即为primary shard,灰色的即为replica shard。
1.插入
先来说说写入吧,由于有多个shard,请求过来时,如何判断写入到哪个shard呢,ES中每个doc都会有一个唯一id,默认会对id取hash值,根据shard的个数mode到对应的shard上,默认情况下shard中的数据id不是全局有序的,这点和Mysql、HBase有很大区别。
ES的写入和HBase有些类似,也是将所有的写操作变成顺序写,也是先将数据写入内存,然后一段时间后会将内存数据flush到磁盘,磁盘的索引文件会定时进行merge,保证索引文件不会过多而影响检索性能。
另外提一点,数据存入ES后并不是立马就能检索到,这点跟MySQL和HBase,或者说跟数据库系统是完全不一样的。主要是因为由于Inverted Index结构的复杂,需要一个专门的indexReader来查询数据,但是indexReader是以snapshot的方式打开的索引,也就是说indexReader看不到之后的新数据。所以ES提供了一个refresh功能,refresh会重新打开indexReader,使其能够读到最新的数据。默认refresh的间隔是1s,所以ES自称是近实时检索功能。
说到顺序写,这时候大家可能会想:那ES的写入速度和HBase差不多喽?那,其实不是的,不止不如而且差的还不是一点点,因为ES多了两个最关键的步骤:build index和refresh index!这两个过程是很耗时的: build index时需要分词、计算权重等复杂的操作(对inverted index创建,检索感兴趣的,可以参考《信息检索导论》)。而refresh会重新打开index,这两个过程加起来导致ES接收文档的速率并不高(可以通过bulk方式来加快数据导入)。但也正是因为这些过程才使ES有强大的检索功能。(虽然我insert慢,但是我花样多呀^ ^)
2.读取
每个node都可以接收读request,然后该node会把request分发到含有该index的shard的节点上,对应的节点会查询、并计算出符合条件的文档,排序后结果汇聚到分发request的node(所以查询请求默认会轮循的将发送到各个节点上,防止请求全部打到一个节点),由该node将数据返回给client。(ES也支持指定shard查询,默认是根据文档id进行路由,相当于主键查询,但是假如不能确定数据在哪个shard上时,还是需要查询所有shard)
这里要强调一下,由于ES支持全文检索,根据Inverted Index的特性,大部分情况下,一个关键字对应了很多的doc,如果全部返回,数据量较大,会对集群造成较大压力,所以ES默认只返回权重最高的前20条记录(可配置),也可以通过scroll功能获取全部数据。类似的场景跟我们平时使用baidu、google是一样的,我们使用搜索引擎时,往往是希望得到关联性最强的top N文档,并不关心全部文档有多少个,这也是为什么要计算权重的原因。
现在的ES的功能越来越丰富,不仅仅包含全文检索的功能,而且还有统计分析等功能,说它是全文检索框架吧,它比全文检索功能要丰富,说它是数据库吧,但是它不支持事务,只能说现在各个框架之间的界限越来越模糊了。
3.更新 &删除
ES的更新和删除和HBase类似,也是全部看做是插入操作,通过timestamp和delete marker来区分。
又到了问题环节 :D :既然这种将更新删除统一变成顺序写的方式能够提高写性能,那它难道没有什么坏处吗?
答案是肯定有的呀,这种方式能够有效的提升写性能,但是存在一个很大的问题就是后台经常会需要merge,而merge是一个非常耗资源的过程,对于某些稳定性要求较高的业务来说,这是不能接受的,但是不merge的话,又会降低查询性能(过多的小文件影响查询性能)。目前通用的做法是尽量选择业务低峰期进行merge操作。
5、使用场景
说了这么多,其实还是希望对MySQL,HBase,ES各自的实现做下对比,方便我们根据业务特点选择最合适的存储、检索方案。下面说一下笔者在工作中使用的经验:
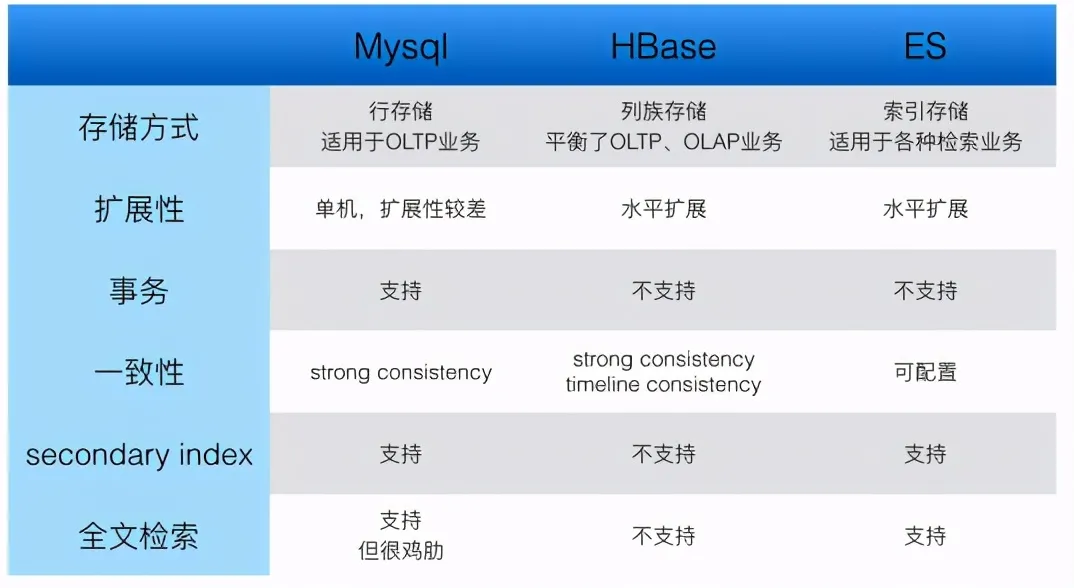
5.1 MySQL
MySQL在三款中最为成熟,而且支持事务,支持二级索引,容灾备份方案也最为成熟,所以线上核心业务Mysql是不二之选(当然如果不差钱,Oracle也挺不错,而且出问题自己解决不了的话,打电话就可以了,手动斜眼)。
5.2 HBase
HBase因为其强大的写入能力和水平扩展能力,比较适合存储日志,用户行为等数据量比较大的数据,这种数据一般不涉及事务级别的读写,对二级索引的需求也不是很高。而且HBase的主键不像Mysql,往往是涉及到业务逻辑的,如果查询条件单一的话,可以把直接把需要查询的字段作为主键的一部分,类似MySQL的联合索引,来提供检索功能。
5.3 ES
ES现在不仅提供全文检索,还提供统计功能,并且提供的Restful接口非常好用,配上Kibana还可以进行图形化展示,第三方插件也很丰富。虽然ES可以水平扩展,但是考虑到ES的大部分检索都会检索该index的所有shard,如果单个index数据过大,性能多少也会受到影响,所以单个index的大小最好控制在一定的范围,比如存储用户行为日志的index,可以每隔一段时间归一次档,创建新的index,做到冷热分离。而且ES也可以作为MySQL或HBase的索引来使用,虽然Mysql也有索引功能,但是过多的索引往往会拖累MySQL的性能,并且线上MySQL数据库一般也不允许执行统计类的sql,这时可以用ES辅助实现统计,HBase因为只有主键检索,所以更需要二级索引的功能。
举一个笔者前司组合使用的场景:trace系统的log数据以HBase作为主要存储,同时最近三个月的数据也在ES里面保留一份,ES主要用来完成各种复杂检索、统计。但数据同步需要业务自己实现,当然trace业务对一致性要求不那么高,也可以忽略这个问题。
tip:将数据库的数据向ES中同步的时候,因为网络延迟等问题,到达的顺序可能会乱序,这时老数据有可能会覆盖新的数据,ES提供了一个version功能,可以将数据的timestamp作为version值,防止旧version的数据覆盖新version的数据。
总结
传统的关系型数据库有着强大的事物处理能力,满足了大部分线上业务需求,但是水平扩展性一直是一个头疼的问题,NoSql数据库虽然解决了水平扩展问题,但是功能太单一,现在越来越多的公司开始着手研究新一代NewSQL数据库,结合了关系型数据库的优点外还拥有水平扩展能力,比如淘宝的Oceanbase,PingCAP的TiDB,国外的CockroachDB,让我们做好拥抱NewSQL的准备吧。















