【51CTO.com快译】近年来,一种被称为DevOps的软件工程文化已悄然在许多组织中流行起来。它旨在统一软件开发(Dev)和IT运营(Ops),并且通过持续集成(CI)和持续交付(CD)两个主要概念,在软件工程的实践中倡导自动化。如今,许多应用开发团队都能够从此类敏捷开发的实践中实现:频繁的软件交付,尽早地收到客户的反馈,拥有组织内跨职能的团队,更快地让产品面市,以及保持客户的满意度。
不过传统的数据库手动变更管理过程,正在逐渐成为持续交付的瓶颈。对此,本文将重点讨论如何将其简化到应用代码的统一交付管道中。
持续集成
作为敏捷开发过程的核心原则之一,持续集成强调的是确保由团队内多个成员所开发出的代码,能够顺畅实现集成,进而避免出现各自为政的“集成地狱”。它主要涉及到独立且自动化的构建、以及自动化的测试。可以说,持续集成促进了以测试为驱动的开发,以及对版本控制系统的基线、主分支、主干(trunk)的频繁“原子性”提交的实践。
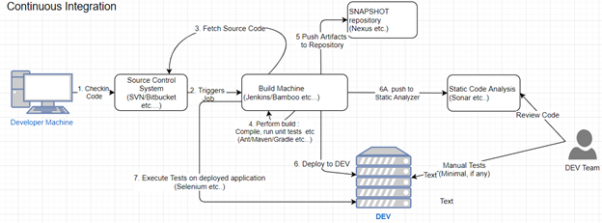
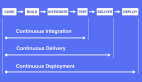
图1:典型的持续集成过程
如上图所示,开发人员一旦将代码签入源控制系统,就会触发在持续集成服务器中的配置构建作业。该作业将从版本控制系统中签出代码,进行构建,执行测试,并将生成的工件(如jar文件),部署到工件存储库(artifact repository)中。一部分定时触发的CI作业,则会将代码部署到开发环境中,将详细信息推送到静态分析工具中,对已部署的代码、或团队认为实用的自动化过程进行系统测试,进而确保代码库的运行状况良好。同时,敏捷团队有责任确保上述自动化流程在出现任何失败时,能够暂缓代码的提交,直至自动化的构建被修复。
持续交付
持续交付除了需要确保软件系统中的不同模块能够被始终集成之外,还要确保代码能够始终被部署到生产环境中。这意味着,系统除了拥有自动化的构建和测试套件之外,还具有自动化的交付过程。通常,我们只需单击按钮,便可在几分钟之内完成软件的部署。同样作为DevOps的核心原则,持续交付的优势包括:可预测的部署,降低引入新功能的风险,缩短客户反馈的周期,以及提高软件的总体质量。
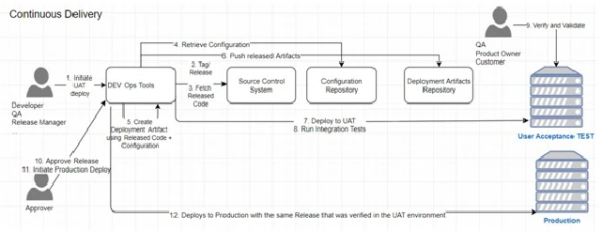
图2:典型的连续交付过程
“持续交付”的过程往往基于“持续集成”过程之上。上图包含了用户验收测试(UAT)和生产两种环境。不过,在软件进入生产环境之前,不同的组织可能会设有诸如:质量保证(QA)、负载测试、预生产等多个staging(模拟)环境。当然,所有staging环境和生产环境的部署,都是通过相同的自动化过程来执行的,并且采用的是不同环境的相同版本代码库。我们可以使用多种工具来实现配置的自动化、受控、可重复、可靠、可审核、以及可逆(或称可回滚)。
数据库变更管理的瓶颈问题
不可否认,几乎所有的项目除了交付已开发的应用代码,也会涉及到诸如schema(结构模式)变更等与数据库相关的工作。目前,我们认为在数据库的开发领域尚未采用敏捷原则,或实现持续集成。因此,此类数据库的相关工作会或多或少地拖慢整个软件产品的交付进程。
让我来看一个真实的案例。某开发团队通过遵循Scrum的敏捷方式,进行了2周的sprint(迭代)。当前的一条story(故事线)是在文档中添加一个能与下游系统交互的新字段。开发团队估计:就代码开发而言,业务事件触发应用会将文档发送到下游系统,以及后期的检索系统,这些仅涉及到数据访问层中的微小变更。因此,如果不涉及数据库(本例为关系数据库管理系统)的变更,这个仅向现有数据表中添加新列的story,很容易在当前的sprint中被实现。但是,正是因为涉及到数据库的修改,开发团队可能会对此类迭代的可行性缺乏信心。
这是为什么呢?其原因在于,他们需要将架构的变更请求发送给数据库管理员(DBA)。而DBA将会花时间去确定该变更请求的优先级,并将它与从其他开发团队处收到的变更请求进行比较。而在开发数据库完成了变更以后,DBA则会通知开发人员,并等待他们的反馈,以便将变更推广到QA或其他阶段的环境中。同时,开发人员将测试新架构中代码的变更。最后,通过开发团队与DBA的紧密协调,将应用的变更和数据库的变更共同交付到生产环境中。
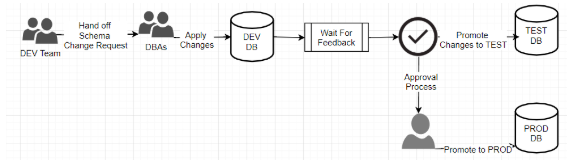
图3:交付数据库变更的手动与半自动过程
值得注意的是,在上图中,该过程并非由开发人员检入代码而触发的,而是需要两个团队之间的交互。也就是说,即使数据库侧的部署过程是自动化的,也无法与应用代码的交付管道集成在一起。虽说应用代码的变更在某种程度上直接取决于数据库的变更,但是这两个变更的生命周期是完全相互独立的。
下面,让我们来讨论如何将那些与数据库变更相关的工作(包括数据建模和schema变更等)置于CI/CD过程的范畴之内。
DBA应该成为跨职能敏捷团队的一部分
许多组织会根据:协助建立应用开发的数据库,以及维护生产环境的数据库,来区分DBA的角色。其中,服务于生产环境的DBA的主要职责是:通过监控数据库,处置升级与补丁,分配存储空间,执行备份与恢复等,以确保生产环境中数据库的可用性。而开发类DBA需要与应用开发团队紧密合作,估计存储需求,并协助他们进行数据模型的设计,将逻辑模型转换为数据库的物理schema等。
可见,为了将数据库的工作和应用开发工作整合到一个交付管道中,我们势必让开发类DBA成为开发团队的一部分,并由具有良好数据库知识的全栈开发人员来担任。
数据库作为代码(Database As Code)
为了实现将数据库变更和应用代码集成到单个管道中,我们需要对数据库中的每一项变更编写脚本,并对其予以版本控制,进而按需通过脚本自动建立一个新的数据库实例。如果我们必须将数据库的对象捕获为代码,那么需要根据脚本(即代码)的类型,对数据库进行评估与分类。具体区别标准如下:
数据库结构:
就是我们经常提到的schema(模式),它定义了数据库存储数据的结构,其中包括针对表、视图、约束、索引和类型的定义。数据字典也可以被视为数据库结构的一部分。
已存储的代码:
它们与应用代码非常相似,其不同之处在于,它们被存储在数据库中,并由数据库引擎来执行。它们包括:存储过程、函数、程序包、以及触发器等。
参考数据:
它们通常存储着被其他业务数据表所引用的一组允许值(permissible values)。在理想情况下,参考数据表中几乎没有数据记录。它们只有在某些业务流程发生变更时,才可能跟着变化,而在正常业务过程中是不会发生变更的。
应用数据或业务数据:
它们是应用程序在正常业务过程中产生的数据记录,这是任何数据库被加入到应用系统的主要目的。
总的说来,在以上四种类型的数据库对象中,前三种可以并且应该被捕获为脚本,进而被存储在版本控制系统中。
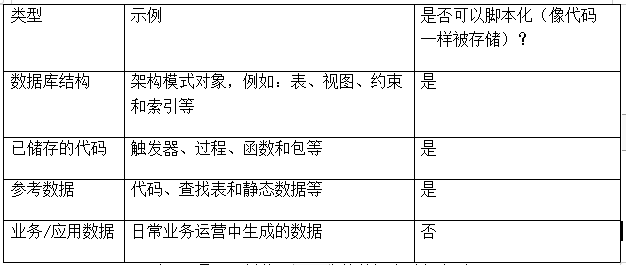
表1:是否可被编写为脚本的数据库对象类型
如上表所示,业务或应用数据是唯一不能被脚本化、或存储为代码的类型。所有回滚、修改、归档等都是由数据库本身来执行的。唯一例外的是,当schema变更导致数据发生迁移时(例如,填充了新的列,或将数据从基表移至规范化表中),迁移脚本将被视为代码,并且应当遵循与schema变更相同的生命周期。
下面,让我们以一个简单的数据模型为例(您可以认为数据建模的“Hello World”),来说明如何将脚本存储为代码。
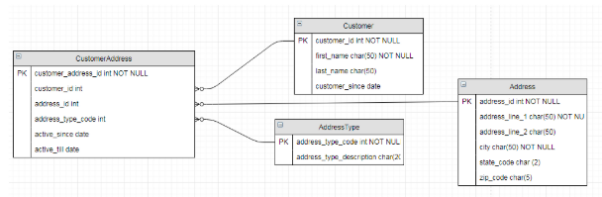
图4:该示例模型中包含了业务数据表和参考数据表
在上述模型中,客户可能与诸如:帐单地址、送货地址等多个地址相关联。AddressType表存储了诸如:帐单、送货、住所、工作等不同类型的地址。存储在AddressType中的数据可以被视为参考数据,毕竟它们在日常业务运营中不会有激增。而其他包含着业务数据的表,会随着客户的增多,而继续增长。
下面是各种示例脚本:
表:

限制条件:
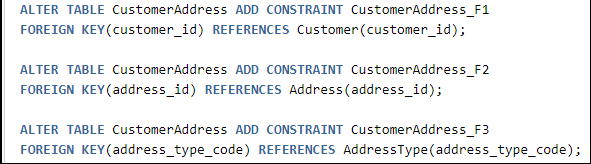
参考数据:

由上述示例可知,除了业务数据,其他所有的数据库对象都能够被捕获到SQL脚本中。
与应用代码位于同一存储库中的版本控制数据库工件:
将数据库工件与应用代码保存到版本控制系统的同一存储库中,有着诸多好处。由于在大多数情况下,数据库schema的变更往往会涉及到应用代码的变更,因此将它们标记为共同发布,可以避免应用代码和数据库出现不同步的状况。同时,由于与项目相关的所有内容都放在了一处,因此新的团队成员可以更加轻松方便的获悉与查阅,进而加快了工作效率。
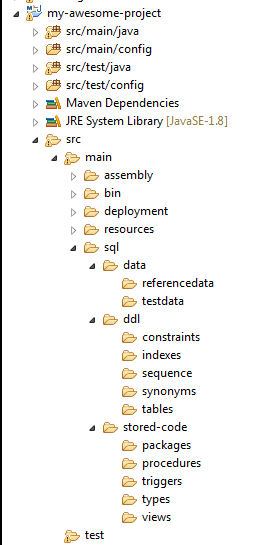
图5:包含了数据库代码的Java Maven项目的结构示例
上面的目录结构展示了如何在Java Maven项目中,将数据库脚本与应用代码一起存储。当然,这对于Ruby或.Net等应用,也是通用的。CI/CD自动化工具可以在同一处找到它们,并对其执行诸如:从头开始构建架构、生成迁移、以及产生部署脚本等必要的操作。
将数据库工件集成到构建脚本中:
为了确保数据库的变更能够与同一交付管道中的应用代码“齐头并进”,我们在构建的过程中包含数据库脚本是非常必要的。通常,数据库工件是某种形式的SQL脚本,而且大多数主流构建工具都能够支持本地、或通过插件的方式执行SQL脚本。
在此,让我们先讨论在本地环境、或CI服务器中的构建,稍后再涉及到暂存环境。其中包括的典型任务包括:
- 删除Schema。
- 创建Schema。
- 创建数据库结构(或Schema对象),包括表、约束、索引、序列和同义词。
- 部署已存储的代码,包括过程、函数、以及包等。
- 加载参考数据。
- 加载测试数据。
构建工具可以确保数据库在加载已知数据集时处于稳定的状态,并且通过充分的集成测试,以避免出现应用代码与数据模型的不同步。这是在数据库变更管理过程中,实现持续交付模型的第一步。
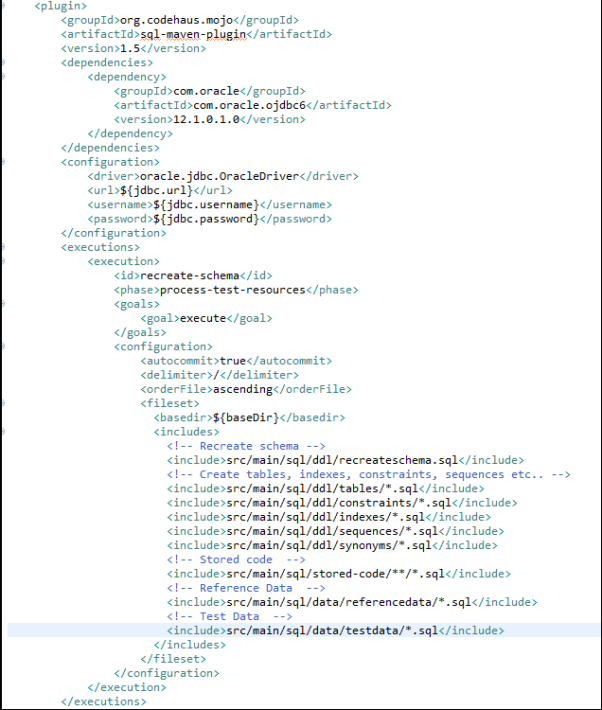
图6:该代码片段展示了用于运行数据库脚本的Maven构建
上面的代码截图说明了如何使用Maven插件来运行SQL脚本。它能够删除与重建schema,并通过运行所有的DDL脚本,来创建表、约束、索引、序列和同义词。接着,它将所有已存储的代码部署到数据库中,并最后加载所有的参考数据和测试数据。
避免共享数据库
让多个应用共享一个数据库schema并非一个好主意。除非数据库真正属于某个应用、且不被其他应用所共享,否则将应用代码和数据库变更置于同一交付管道下,将难以达到预期的效果。同时,共享数据库还会导致应用之间的紧密耦合、以及许多其他问题。
让每个提交和CI服务器都能专享Schema
开发人员总希望能够在自己的“沙箱”中工作,而不必担心诸如开发数据库实例之类通用环境等问题。而CI服务器就是这样的沙箱,它遵循了如何开发应用代码的模式。开发人员可以执行各种变更,在本地运行构建,并且在构建成功且测试通过后,再提交变更。通常,此类沙盒既可以是在开发人员本地电脑上、已安装的独立数据库实例,也可以是共享数据库实例中的其他架构。
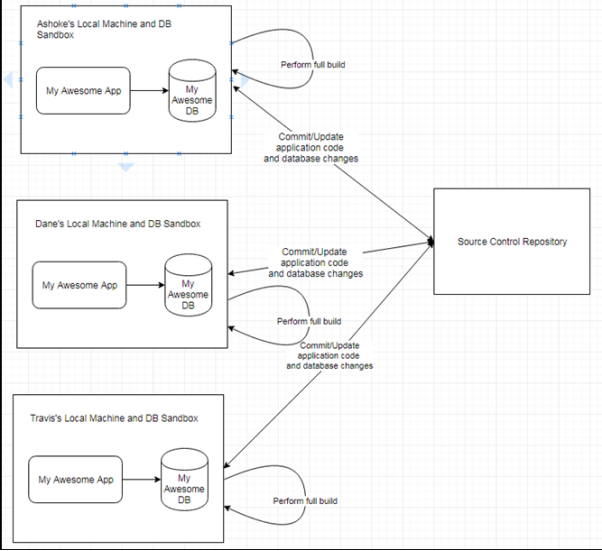
图7:开发人员在其本地环境中进行频繁的变更与提交
如上图所示,每个开发人员都拥有自己的schema副本。在执行完成构建之后,除了构建应用,它还会从头开始构建数据库的schema。其中包括:删除与重建schema,执行DDL脚本,以加载所有的schema对象(如:表、视图、序列、约束和索引)。同时,它会创建代表着已存储的代码对象,其中包括:函数、过程、包和触发器。最后,它将加载所有的参考数据和测试数据。而自动化的测试则可确保应用代码和数据库对象始终同步。值得注意的是,由于数据模型的变更不如应用代码那样频繁,因此出于构建性能的考虑,我们应当让构建脚本应具有跳过数据库构建的选项。
其实,CI构建作业也应当被设置为带有自己的数据库沙箱。毕竟,构建脚本会执行完整的构建,其中就包括了构建应用,以及从头开始构建数据库的schema。而且,它会运行一整套的自动化测试,以确保应用本身、及其与之交互的数据库能够保持同步。

图8:修改后的CI流程,集成了数据库构建和应用代码的构建
上图中描述的过程与图1中的过程较为相似。CI服务器包含了在对存储库提交时触发的构建作业。它所执行的构建包含了应用和数据库的构建。至此,数据库脚本就能够被整合为应用代码了。
处置迁移
我们在前文中已经讨论了如何针对持续集成和本地环境,从头开始构建数据库的schema对象、已存储的代码、参考数据和测试数据。那么对于生产环境中的数据库、以及QA或UAT环境又该如何处理呢?
鉴于数据库的本质就是为了支持业务数据,我们不可能对当前正在运行的业务交易数据库,采取删除schema、或从脚本中重建等操作。因此,我们需要编写增量脚本,也就是将数据库的结构从已知的状态(所谓“软件定制版”)变更过渡,或将数据迁移到所需的状态。例如,为了标准化,我们可能需要通过脚本将一个表中的数据迁至一到多个子表中。而schema的变更,则可以在源代码存储库中,通过脚本的编写,使其成为构建的一部分。这些脚本既可以在主动开发的过程中手工被编写,也可以由一些自动化工具来完成。其中的一种工具是Flyway,它可以生成迁移脚本,将数据结构从一种状态转换为另一种状态。Schema的变更可以在源代码存储库中被编写脚本并进行维护,以使它们成为构建的一部分。

图9:schema迁移与回滚的自动化
在上图中,左侧显示了与应用先前版本(1.0.1)同步的数据库状态。右侧显示了数据库所需的下一版本状态。我们在版本控制系统中既可以捕获并标记左侧的状态,又可以将捕获到的右侧状态作为基线、主分支或主干。两者之间的区别正是我们需要让数据库在staging环境和生产环境中保持不同的状态。上图展示了Flyway工具通过创建迁移脚本,将数据库从先前的版本过渡到新的版本;以及通过回滚脚本,将数据库过渡回先前版本的自动化过程。这些生成的脚本将会被标记,并与其他部署工件一起被存储。因此,我们通过将该自动化过程与持续交付的过程相集成,以确保可重复、可靠、且可逆(通过回滚)的数据库变更。
将数据库变更并入连续交付
现在,我们可以将上述各部分整合到一起了,即:通过一个现有的持续集成过程,来重建数据库和应用代码;通过一个并入部署工件的过程,为数据库生成迁移脚本。DevOps工具将使用这些已发布的工件,来构建任何staging环境或生产环境。该部署工件还将包含回滚脚本,以便在出现任何问题时,我们都可以重新部署应用的先前版本,通过运行数据库的回滚脚本,将数据库的schema转换为与应用代码的先前版本相同步的状态。
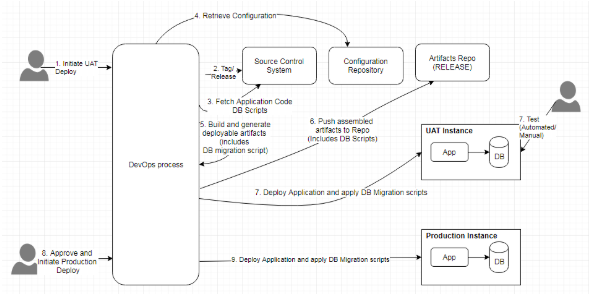
图10:包含了数据库变更的持续交付
上图描述了将数据库变更管理并入持续交付的过程。此处假设已经存在一个持续集成过程。在启动了UAT(或测试、QA等其他staging环境)的部署后,自动化流程将负责在源代码控制存储库中创建标签,并从带标签的代码库中构建可部署的应用工件,生成数据库迁移脚本,组装工件,并执行部署。整个部署的过程包括:应用的部署,以及将迁移脚本应用到数据库中。按照审批流程,应用程序会通过相同的工件被部署到生产环境中。若要回滚至先前版本,则需重新部署应用程序,并运行数据库的回滚脚本。
市场上的可用工具
前面我们主要介绍了如何在涉及数据库变更的项目中,实现CI/CD的过程。而在实践中,我们往往会根据不同的需求,使用不同的工具,例如:针对构建自动化的Maven或Gradle,针对持续集成的Jenkins或TravisCI,以及针对配置管理的Chef或Puppet等本地解决方案。下面,我为您罗列出针对数据库DevOps的自动化通用工具:
小结
诚然,持续集成和持续交付的流程为组织带来了诸如:缩短产品的面市时间,可靠的发布,以及提高软件整体质量等巨大的好处。鉴于手动执行数据库变更管理会带来的交付瓶颈,本文和您讨论了如何将数据库的变更,带入与应用代码相同的交付管道中,以及市场上能够配合此类实践的各种实用工具。
原文标题:Continuous Integration and Continuous Delivery for Database Changes,作者: Ashoke Bhowmick
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】