












一 背景
随着云时代的到来,数据库也开始拥抱云数据库时代,各类数据库系统(OLTP、OLAP、NoSQL等)在各内外云平台(AWS、Azure、阿里云)百花齐放,有开源的MySQL、PostgreSQL、MongoDB,传统数据库厂商的SQLServer、Oracle,云厂商自研的Aurora、Redshift、PolarDB、AnalyticDB、AzureSQL等。有些数据库还处于Cloud Hosting阶段,仅仅是将原有架构迁移到云主机上,利用了云的资源。有些数据库则已经进入了Cloud Native阶段,基于云平台IAAS层的基础设施,构建弹性、serverless、数据共享等能力。
本文主要介绍阿里云云原生数据仓库AnalyticDB MySQL版(以下简称AnalyticDB)过去几年在弹性方向上的探索和成果。
二 为什么要计算存储分离
MPP(Massive Parallel Processing)架构为OLAP类数据库最普遍采用的技术架构。在MPP架构下,计算存储共享一个节点,每个节点有自己独立的CPU、内存、磁盘资源,互相不共享。数据经过一定的分区规则(hash、random、range),打散到不同的节点上。处理查询时,每个节点并行处理各自的数据,互相之间没有资源争抢,具备比较好的并行执行能力。
这种将存储资源、计算资源紧密耦合的架构,不太容易满足云时代不同场景下的不同workload需求。例如数据导入类的任务,往往需要消耗比较大的IO、网络带宽,而CPU资源消耗不大。而复杂查询类任务往往对CPU的资源消耗非常大。因此面对这两种不同的workload,在选择资源规格时,需要结合不同的workload分别做不同的类型选择,也很难用一种资源规格同时满足这两种类型。因为业务不停在发展,workload也不停在变化,比较难提前做好规划。
当业务发展,对CPU资源提出了更高的需求,我们扩容集群扩充CPU资源时,也会引发数据的reshuffle,这会消耗比较大的网络带宽、以及CPU资源。即便是基于云平台构建的数据仓库,在查询低峰期时,也无法通过释放部分计算资源降低使用成本,因为这同样会引发数据的reshuffle。这种耦合的架构,限制了数据仓库的弹性能力。
而通过分离存储资源、计算资源,可以独立规划存储、计算的资源规格和容量。这样计算资源的扩容、缩容、释放,均可以比较快完成,并且不会带来额外的数据搬迁的代价。存储、计算也可以更好的结合各自的特征,选择更适合自己的资源规格和设计。
三 业界趋势
1 Redshift
作为AWS上最热门的数据仓库产品,Redshift采用的是MPP架构,它也一直往弹性方向演进。Redshift于2018年11月推出的Elastic resize功能,相比于classic resize,其扩缩容时间大幅下降。在2019年11月进一步推出了elastic resize scheduling让用户配置扩缩容计划来达到自动弹性。此外,Redshift在2019年12月正式推出了RA3形态,它采用了计算存储分离的架构,数据存储在S3上,计算节点使用高性能SSD作为本地缓存,加速对数据的访问。在这个架构下,计算存储可以独立弹性,具备较好的弹性能力。
2 Snowflake
Snowflake从诞生的第一天起就采用计算存储分离架构,作为跨云平台的云数据仓库,它的存储层由对象存储构成(可以是AWS S3、Azure Blob等),计算层由virtual warehouse(简称VW)构成,每个用户可以创建一个或多个对应的VW,每个VW是由若干个EC2(AWS上的虚拟主机)组成的集群。这样可以灵活地根据不同workload,为不同用户创建不同规格的VW,且用户之间具备非常好的隔离性。基于VW的灵活性,Snowflake支持了VW auto suspend、resume以及auto scale能力,通过计算存储分离带来的弹性能力,给用户带来“pay-as-you-go”的使用体验。
四 AnalyticDB弹性模式
与Redshift类似,AnalyticDB最初也是基于传统的MPP架构来构建的。2020年5月,AnalyticDB推出了计算存储分离架构的弹性模式。AnalyticDB弹性模式分为接入层、计算层、存储层,其中接入层兼容了MySQL协议,包含了权限控制、优化器、元数据、查询调度等模块,负责数据实时写入、查询。
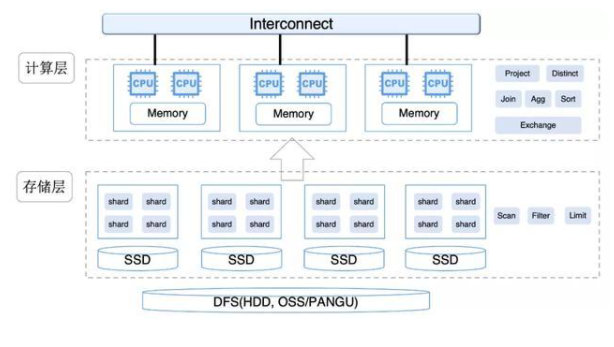
1 存储层
在弹性架构下,存储层负责数据的实时写入、索引构建、数据扫描、下推的谓词计算(过滤、列裁剪、分区裁剪等),不再负责查询的计算任务。数据在存储层依然采用MPP的方式组织,数据以hash、random的方式在分区(shard)间均匀打散,以分区(shard)方式可以非常方便地实现数据的实时写入强一致,而在数据扫描的时候可以实现shard级的并发读以保证并发。同时存储层提供一体化的冷热分层存储能力,数据可以热表的方式存在本地SSD、冷表的方式存储在底层DFS,亦或是以冷热混合表的形式存放,实现冷热数据的自动迁移,《数据仓库分层存储技术揭秘》一文中有详细介绍。
2 计算层
在弹性模式下,计算层由若干个计算节点组成,计算节点负责接收接入层下发的物理执行计划,并根据物理执行计划转换成对应的算子。计算层采用了vectorized的执行模型,算子之间数据以pipeline的方式进行交互,若干行(一般为几千行)数据组成一个batch,batch内部数据以列存的形式组织。此外,计算层的JIT模块会根据查询计划,动态生成代码,加速计算,包括expression计算、排序、类型比较等。JIT模块还以计划的pattern为key,缓存动态生成的代码,以此减少交互式查询下动态生成代码的代价。
3 执行计划
计算存储分离架构下,计算层新增了Resharding算子,负责从存储层加载数据。数据以batch、列存的方式在存储层与计算层之间传递,单次请求,会传输多个batch的数据,一般不大于32MB。由于存储层依旧保留了MPP数据预分区的方式,优化器在生成执行计划的时候会根据这个分布特征,在join、agg运算时,减少不必要的数据repartition。此外,优化器也会判断查询中的filter是否可利用存储层索引,尽量把可被存储层识别的filter下推至存储层利用索引加速过滤,减少与计算层之间的数据传输。而不可被下推的filter依然保留在计算层进行过滤。

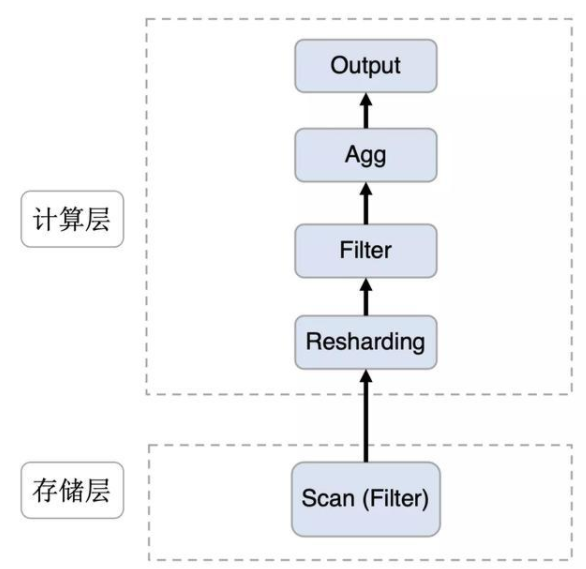
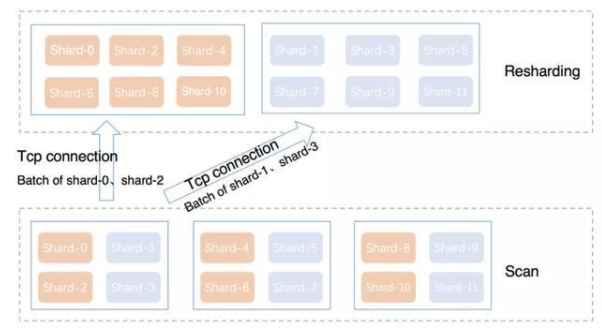
4 分区动态重分布
Resharding算子与Scan算子之间,分区(shard)遵循以下原则进行重分布:
来自同一个存储节点的多个分区,尽量打散到不同的计算节点上。
同一个查询内,不同表的相同分区,会被映射到相同的计算节点上。
同一个分区,在不同查询之间,随机分配到不同的计算节点。
与Snowflake、Redshift不同,计算节点与分区之间没有固定的映射关系,因为计算节点没有本地的cache,数据访问的加速完全依赖于存储层的SDD、内存cache。这种动态重分布的方式,可以大大缓解分区不均匀、分区内数据倾斜等问题,不会造成固定计算节点的热点。
5 数据加载优化
相比较于原有架构,计算存储分离多了一次远程的数据访问,这对查询的延迟、吞吐会有比较大的影响。我们做了如下几个方面的优化:
合并网络连接。如图三所示,通过合并连接,减少小数据量查询的网络交互次数,降低查询延迟。
数据压缩。batch内基于列存格式进行压缩,减少网络带宽的消耗,有效提升Resharding算子加载吞吐。
异步读取。网络模块异步加载,将数据放入buffer中,Resharding算子从buffer中获取数据,让CPU、网络IO充分并行。
6 性能测试
本节将探究计算存储分离架构对AnalyticDB大数据量分析场景的查询吞吐影响。
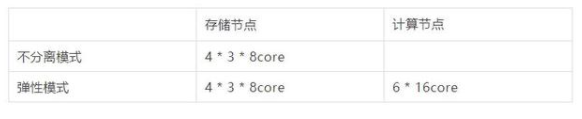
测试环境
实例1:不分离模式,4组存储节点,存储节点负责数据扫描、查询计算。
实例2:弹性模式,4组存储节点 + 6个计算节点。存储节点负责数据扫描,计算节点负责查询计算。两个实例分别导入tpch 1TB数据作为测试数据集。
测试场景
我们选取TPCH Q1作为测试SQL,Q1为单表聚合查询,具备非常高的收敛度,存储层与计算层之间传输的数据量约为260GB。我们以单并发顺序执行的方式,执行TPCH Q1,取查询的平均执行时间。
select l_returnflag, l_linestatus, sum(l_quantity) as sum_qty, sum(l_extendedprice) as sum_base_price, sum(l_extendedprice * (1 - l_discount)) as sum_disc_price, sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) as sum_charge, avg(l_quantity) as avg_qty, avg(l_extendedprice) as avg_price, avg(l_discount) as avg_disc, count(*) as count_orderfrom lineitemwhere l_shipdate <= date '1998-12-01' - interval '120' daygroup by l_returnflag, l_linestatusorder by l_returnflag, l_linestatus;
- 1.
测试数据

测试结论
从上面的测试数据可以看到,TPCH Q1在弹性模式的执行时间略好。粗看这个结果比较惊讶,计算存储分离后,性能更好了。我们可以仔细分析下,弹性模式与不分离模式具有相同的存储节点数,确保分离模式存储节点不会成为瓶颈。从执行时的资源消耗来看,分离模式的总资源消耗(19.5% + 97%)是不分离模式(98%)的1.19倍,这多消耗的CPU来自于网络传输、序列化、反序列化等。对于计算层来说,只要存储层能够提供足够的数据吞吐,确保计算层的CPU能够打满,那么计算存储分离不会降低查询的处理吞吐,当然相比于不分离模式,会多消耗资源。
五 总结
在AnalyticDB弹性模式的基础之上,未来我们会进一步去深耕我们的弹性能力,包括计算资源池化、按需弹性能力、存储层基于共享存储的快速扩缩容能力。通过这些弹性能力,更好满足客户对于云数据仓库的诉求,也进一步降低客户的使用成本。
参考文献
[1] https://levelup.gitconnected.com/snowflake-vs-redshift-ra3-the-need-for-more-than-just-speed-52e954242715
[2] https://www.snowflake.com/
[3] https://databricks.com/session/taking-advantage-of-a-disaggregated-storage-and-compute-architecture
[4] Dageville B , Cruanes T , Zukowski M , et al. The Snowflake Elastic Data Warehouse.[C]// ACM. ACM, 2016.
[5] Gupta A , Agarwal D , Tan D , et al. Amazon Redshift and the Case for Simpler Data Warehouses[C]// Acm Sigmod International Conference. ACM, 2015.
[6] Vuppalapati M, Miron J, Agarwal R, et al. Building an elastic query engine on disaggregated storage[C]//17th {USENIX} Symposium on Networked Systems Design and Implementation ({NSDI} 20). 2020: 449-462.
















