














本文转载自微信公众号「zartbot」,作者扎波特的网线钳。转载本文请联系zartbot公众号。
昨天在公司看到一张PPT,上面写着两行大字:
SR for Anything, Network as a Computer
不用打听写这个ppt的人是谁,也不评价对错惹是非,下面只想给网络工程师技术扶贫一下可计算性和图灵完备的知识,留给各位自己判断.
图灵机
图灵机是英国数学家阿兰·图灵在1936年的文章《On Computable Numbers, with an Application to the Entscheidungsproblem》中提出的抽象计算模型.

在论文的第三章讲述了一个计算机的例子,即一个机器包含了一条无限长的纸带,纸带被分成一些Square,然后上面有一些二进制编码的symbol。存在一个事先约定好的指令, 例如R表示机器将扫描右侧的Square,同理L表示左侧,E表示擦除,P表示打印等.计算即根据读写头和规则表决定动作,当读写头停机时,打印输出的就是计算结果:
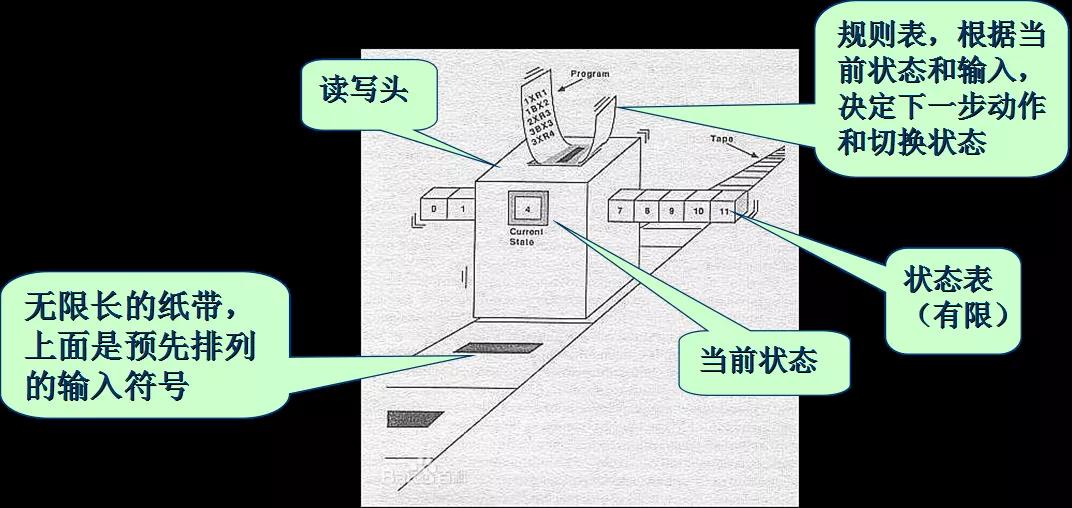
图灵完备
图灵完备是指,当你设计了一套操作数据的规则后,这套指令集或者语言能够模拟图灵机,那么就说这套规则是图灵完备的。通常很多编程语言的图灵完备性影响主要需要考虑分支Branch和循环loop的问题。当然有一些语言故意设计成非图灵完备的,例如很多区块链的合约执行指令不支持分支跳转和循环,主要的目的是它使用的场景和安全性考虑决定的。
SR的图灵完备
SR本身的编码上来看,并不是图灵完备的. 因为SR Label只能顺序执行。当然也可以做一些特殊的处理,例如Binding-SID可以看做是一个特殊的函数调用,然后借用MPLS Stack的结构,可以实现函数入栈. 同时我们也可以定义一些特殊的Label行为来进行Label跳转, 但又有另一个缺陷,处理报文的时候,我们并没有设计相应的状态机。如果要设计,又会成为一个Stateful的forwarding feature,需要相应的流表和动态状态更新。
某种意义上来讲,MPLS-SR因为有栈的结构,入栈和弹出标签相对容易。而SRv6则是一个工程上的灾难,由于必须保留报文的源IP地址,一方面有uRPF的缺陷,另一方面维持IP头并要同时操作SRH产生了一系列问题,例如交换机通常没法同时处理这么大量的数据,SRv6标签栈深度受限。
而针对栈结构,SRv6的SRH在报文中间。入栈和出栈对于P4一类的交换机容易,Deparser上插进去或者砍掉就好。但是传统的CPU架构而言,都需要大量的memory move的操作,我还在开玩笑,Intel啥时候能够出一个批量操作I/O的deparser呢,集成在网卡上或者CPU上都行....
在设计的时候,如果能丢弃原有的IPv6头,根据SRH的信息重建便是一个更好的解决方案,这样标签入栈出栈的处理相对容易很多,uRPF的缺陷也可以避免。所以反过来你就能明白RFC8663 MPLS-SR over UDP的能够在很多场景被接受的原因。但是很抱歉MPLS-SR的问题来自于标签栈的长度,以及没有类似于SRv6那样定义的
P4的图灵完备
我们来看另一个问题,P4设计之初是完全基于硬件能力的,一旦涉及分支Branch极易带来流水线的Stall,因此P4早期的MAU并没有打算支持分支预测,更多的是采用match不同的表产生新的action来将流量分担到另一个MAU实现的。Torfino-2增加了一些功能,而为了实现更加灵活多样的计算,Pensando的实现中直接增加了寄存器/PC/Branch器件.
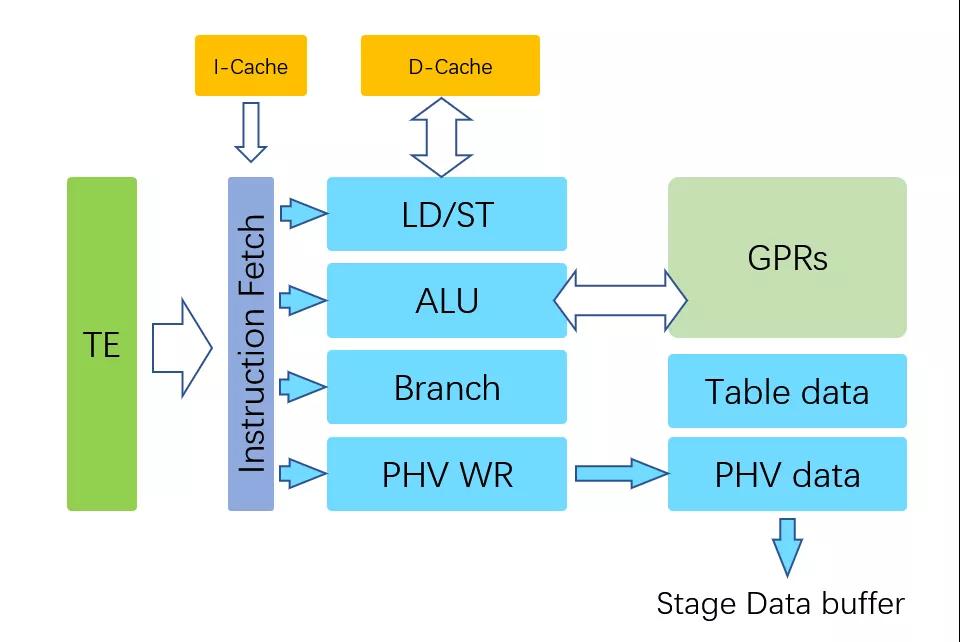
而NanoPU更是直接把一个处理器堆到了P4 MAU旁边。
网络是否需要图灵完备编程
很多人总是喜欢一招鲜打遍天下,但真的有必要什么都做么?前段时间有个某云的同学发了一个朋友圈说什么指标都要追求世界第一, 我补了一句那么价格肯定也世界第一。成年人有足够的支持时可以轻松的说不需要选择,都要。但是技术总是需要取舍的。加法容易减法难,就是这个道理。
计算、存储、网络这三者的组合有其内在的精妙,存内计算(In Memory Computing)和边缘计算提出的算力网络都是为了解决冯诺依曼架构的缺陷,使得计算规模能够再上一个台阶。但是另一个可信计算的问题又会困扰大家。
架构上我并不认同网络能够实现大量的图灵完备的计算,而是可以通过一系列组合为计算和存储搭起一个更好的桥梁。


















