












概述
Linux 下有 3 种“拷贝”,分别是 ln,cp,mv,这 3 个命令貌似都能 copy 出一个新的文件出来。
细心的小伙伴看到我给 “拷贝” 打上了双引号?因为 Linux 的这 3 个命令有极大的区别,虽然用户看起来是拷贝出了新文件。
你是否曾经遇到过以下问题,想通原因了吗?:
- ln 创建链接文件,软链接可以跨文件系统,硬链接跨文件系统会报错,为什么?;
- mv 好像有时候快,有时候非常慢,有些时候还会残留垃圾,为什么?;
- cp 拷贝数据有时快,有时候非常慢,源文件和目标文件所占物理空间竟然不一致?
本篇文章看完,希望你以上问题不再有疑问,从容使用 ln,mv,cp 命令。
温馨提示:
以下我们只讨论文件的简单操作,关于目录操作或者复杂参数的操作不在我们本次主题以内,我们忽略;
coreutils 库的代码版本用的是 8.3;
我们来看下简单的 3 个命令操作。首先在执行以下命令之前,准备一个不小的 test 的普通文件(比如 1G )。
"拷贝"命令一:ln
- # 创建一个软链接文件
- ln -s ./test ./test_soft_link
- # 创建一个硬连接文件
- ln ./test ./test_hard_link
你会发现当前目录出现了两个新文件 test_soft_link ,test_hard_link 。并且你会发现拷贝速度好快?为什么呢?
"拷贝"命令二:mv
把 test 文件"拷贝"到 ./backup/ 目录
- mv ./test ./backup/
更神奇的是,好像 copy 一个 1 G 的文件,速度也贼快?
“拷贝”命令三:cp
把 test 文件"拷贝"到 ./backup/ 目录
- cp ./test ./backup/
上面我们看到,好像 ln,mv,cp 这 3 个命令都是“拷贝”?好像都进行了数据复制出了新的文件?
答案:当然不是。这 3 个看起来都是复制出了新文件,但其实天壤之别。我们一个个来揭秘。
在揭秘这 3 个命令之前,我们必须先复习文件的基础知识点,Linux 的文件和目录的关系。
Linux 的文件和目录
在 深度剖析 Linux cp 的秘密 一文中,我们详细剖析了文件系统的形态。有几个关键知识点:
- 文件系统内有 3 个关键区域:超级块区域,inode 区域,数据 block 区域;
- 其中一个 inode 和一个文件对应,包含了文件的元数据信息;
- 一个 inode 有唯一的编号,可以理解成就是单调递增的整数。比如 1,2,3,4,5,6,,,,;
关于上面,我们注意到 inode 其实标识的是一个平坦的结构,inode 索引到数据 data 区域,每个 inode 都有唯一编号。
问题来了:Linux 的目录是一个倒挂的树形结构呀,为什么上面说 inode 是平坦的结构?如下:
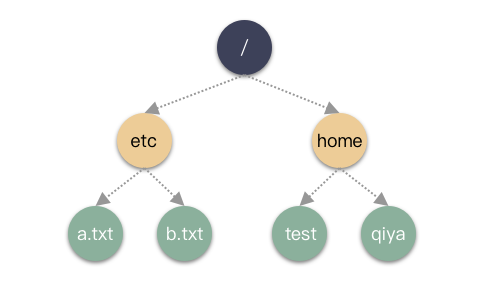
Linux 的文件确实是树形结构,inode 也确实是平坦的结构。你会感觉到因为是因为之前故意忽略了一个几个东西:目录文件和 dentry 项。这是两个非常重要的概念,我们逐个解释下。
文件系统中其实有两种文件类型,分为:
- 普通文件(这里把链接文件包含在普通文件以内)
- 目录文件
可以通过 inode->i_mode 字段,使用 S_ISREG,S_ISDIR 这两个宏来判断是哪个类型。普通文件很容易理解,就是普通的数据文件,inode 里面存储元数据,inode 可以索引到 block,block 里面存储用户的数据。目录文件 inode 存储元数据,block 里面存储的是目录条目。目录条目是什么样子的东西?
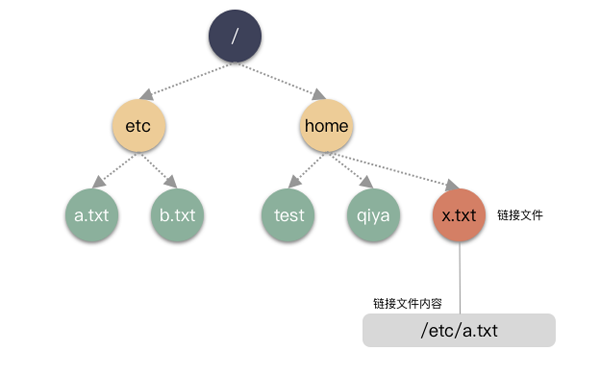
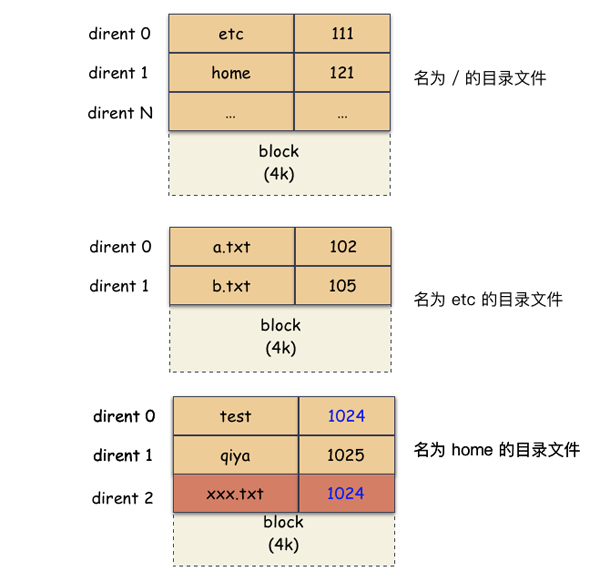
举个形象的例子:在当前 testdir 目录下,有 dir1,dir2,dir3 这三个文件。假设 dir1 的 inode 编号是 1024,dir2 是 1025,dir3 是 1026。
那么现实是这样的:
- testdir 这个目录首先会对应有一个 inode,inode->i_mode 的类型是目录,并且还会有 block 块,通过 inode->i_blocks 能索引到这些 block;
- block 里面存储的内容很简单,是一个个目录条目,内核的名字缩写为 dirent,每一个 dirent 本质就是一个 文件名字 到 inode 编号的映射,所以,testdir 这个目录文件的 block 里存了 3 条记录 [dir1, 1024],[dir2, 1025],[dir3, 1026];
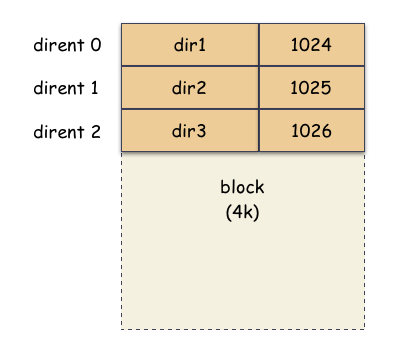
所以,目录到底是什么呢?就存储形态而已,目录也是文件,存储的是 名字 到 inode number 的映射表。dirent 其实就是 directory entry 的缩写。
好像还没讲到树形结构?
其实已经讲了一半了,树形结构的数据结构基础已经有了,就是目录文件和 dirent 的实现。
假设叶子结点的为普通文件
针对开篇的图,其实磁盘上存储了 3 个目录文件
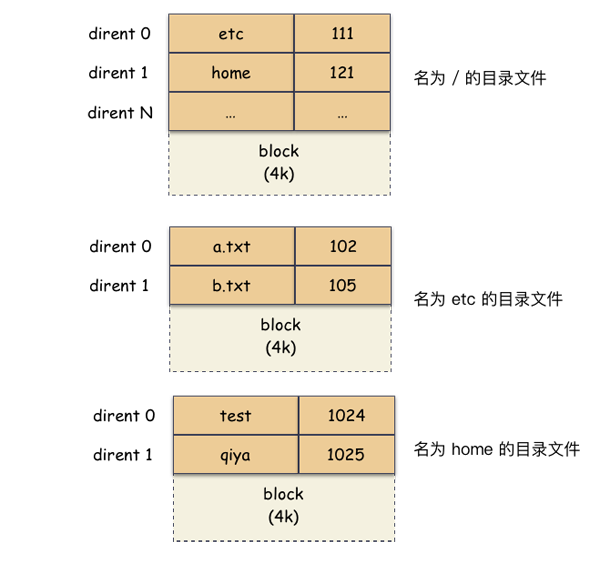
这个时候,读者朋友你是不是都可以用笔画出一个树形结构了,内存的树形结构也是这么来的。通过磁盘的映射数据构造出来。在内存中,这个树形结构的节点用 dentry 来表示(通常翻译成目录项,但是笔者认为这个翻译很容易让人误解)。
以下是笔者从内核精简出来的 dentry 结构体,通过这个总结到几个信息:
- dentry 绑定到唯一一个 inode 结构体;
- dentry 有父,子,兄弟的索引路径,有这个就足够在内存中构建一个树了,并且事实也确实如此;
- struct dentry {
- // ...
- struct dentry *d_parent; /* 父节点 */
- struct qstr d_name; // 名字
- struct inode *d_inode; // inode 结构体
- struct list_head d_child; /* 兄弟节点 */
- struct list_head d_subdirs; /* 子节点 */
- };
所以,看到现在理解了吗?父、子 指针,这就是经典的树形结构需要的字段呀。目录文件类型为树形结构提供了存储到磁盘持久化的一种形态,是一种 map 表项的形态,每一个表项我们叫做 dirent 。文件树的结构在内存中以 dentry 结构体体现。
划重点:仔细理解下 dirent 和 dentry 的概念和形态,仔细理解磁盘的数据形态和内存的数据结构形态,后面要考的。
ln 命令
ln 是 Linux 的基础命令之一,是 link 的缩写,顾名思义就是跟链接文件相关的一个命令。一般语法如下:
- ln [OPTION]... TARGET LINK_NAME
ln 可以用来创建一个链接文件,有趣的是,链接文件有两个不同的类别:
- 软链接文件
- 硬链接文件
1 什么是软链接文件?
无论是软链接还是硬链接都是“链接”文件,也就是说,通过这个链接文件都能找到背后的那个“源文件”。首先说结论:
- 软链接文件是一个全新的文件,有独立的 inode,有自己的 block ,而这个文件类型是“链接文件”的类型而已;
- 这个软链接文件的内容是一段 path 路径,这个路径直接指向源文件;
所以,你明白了吗?软链接文件就是一个文件而已,文件里面存储的是一个路径字符串。所以软链接文件可以非常灵活,链接文件本身和源解耦,只通过一段路径字符串寻路。
所以,软链接文件是可以跨文件系统创建的。
有兴趣的小伙伴可以去看源码实现,在 coreutils 库里,调用栈如下:
- main -> do_link -> force_symlinkat -> symlinkat
也就是说最终调用的是系统调用 symlinkat 来完成创建,而这个 symlinkat 系统调用在内核由不同的文件系统实现。举个例子,如果是 minix 文件系统,那么对应的函数就是 minix_symlink。minix_symlink 这个函数上来就是新建一个 inode ,然后在对应的目录文件中添加一个 dirent 。来来来,我们看一眼 minix_symlink 的主干代码:
- static int minix_symlink(struct inode * dir, struct dentry *dentry,
- const char * symname)
- {
- // ...
- // 新建一个 inode,inode 类型为 S_IFLNK 链接类型
- inode = minix_new_inode(dir, S_IFLNK | 0777, &err);
- if (!inode)
- goto out;
- // 填充链接文件内容
- minix_set_inode(inode, 0);
- err = page_symlink(inode, symname, i);
- if (err)
- goto out_fail;
- // 绑定 dentry 和 inode
- err = add_nondir(dentry, inode);
- //...
- }
划重点:软链接文件是新建了一个文件,文件类型是链接文件,文件内容就是一段字符串路径。分配新的 inode,内存对应新的 dentry ,当然了,也新增了一个 dirent 。软链文件可以跨越不同的文件系统。
2 什么是硬链接文件?
现在我们知道了,软链接文件怎么找到源文件的?通过路径找到的,路径就存储在软链接文件中。硬链接文件又怎么办到的呢?
硬链接很神奇,硬链接其实是新建了一个 dirent 而已。下面是重点:
- 硬链接文件其实并没有新建文件(也就是说,没有消耗 inode 和 文件所需的 block 块);
- 硬链接其实是修改了当前目录所在的目录文件,加了一个 dirent 而已,这个 dirent 用一个新的 name 名字指向原来的 inode number;
重点来了,由于新旧两个 dirent 都是指向同一个 inode,那么就导致了一个限制:不能跨文件系统。因为,不同文件系统的 inode 管理都是独立的。
感兴趣的同学可以试下,跨文件系统创建硬链接就会报告如下错误:Invalid cross-device link
- sh-4.4# ln /dev/shm/source.txt ./dest.txt
- ln: failed to create hard link './dest.txt' => '/dev/shm/source.txt': Invalid cross-device link
有兴趣的小伙伴可以去看源码实现,在 coreutils 库里,调用栈如下:
- main -> do_link -> force_linkat -> linkat
也就是说最终调用的是系统调用 linkat 来完成创建,而这个 linkat 系统调用在内核由不同的文件系统实现。举个例子,如果是 minix 文件系统,那么对应的函数就是 minix_link。这个函数从内存上来讲是把一个 dentry 和 inode 关联起来。从磁盘数据结构上来讲,会在对应目录文件中增加一个 dirent 项。
划重点:硬链接只增加了一个 dirent 项,只修改了目录文件而已。不涉及到 inode 数量的变化。新的 name 指向原来的 inode。
mv 命令
mv 是 move 的缩写,从效果上来看,是把源文件搬移到另一个位置。
你是否思考过 mv 命令内部是怎么实现的呢?
是把源文件拷贝到目标位置,然后删除源文件吗?所以,说 mv 貌似也是“拷贝”?
其实,并不是,准确的说不完全是。
对于 mv 的讨论,要拆分成源和目的文件是否在同一个文件系统。
1 源 和 目的 在同一个文件系统
mv 命令的核心操作是系统调用 rename ,rename 从内核实现来说只涉及到元数据的操作,只涉及到 dirent 的增删(当然不同的文件系统可能略有不同,但是大致如是)。通常操作是删除源文件所在目录文件中的 dirent,在目标目录文件中添加一个新的 dirent 项。
划重点:inode number 不变,inode 不变,不增不减,还是原来的 inode 结构体,所以数据完全没有拷贝。
mv 的调用栈如下,感兴趣的可以自己调试。
- main -> renameat2
- main -> movefile -> do_move -> copy -> copy_internal -> renameat2
我们用例子来直观看下,首先准备好一个 source.txt 文件,用 stat 命令看下元数据信息:
- sh-4.4# stat source.txt
- File: source.txt
- Size: 0 Blocks: 0 IO Block: 4096 regular empty file
- Device: 78h/120d Inode: 3156362 Links: 1
- Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
我们看到 inode 编号是:3156362 。然后执行 mv 命令:
- sh-4.4# mv source.txt dest.txt
然后 stat 看下 dest.txt 文件的信息:
- sh-4.4# stat dest.txt
- File: dest.txt
- Size: 0 Blocks: 0 IO Block: 4096 regular empty file
- Device: 78h/120d Inode: 3156362 Links: 1
- Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
发现没?inode 编号还是 3156362 。
2 源 和 目的 在不同的文件系统
还记得之前我们提过,由于硬链接是直接在目录文件中添加一个 dirent,名字直接指向源文件的 inode ,不同文件系统都是独立的一套 inode 管理系统,所以硬链接不能跨文件系统。
那么问题来了,mv 遇到跨文件系统的场景呢,怎么处理?是否还是 rename ?
举个例子,如下命令,源和目的是不同的文件系统。我虚拟机的挂载点如下:
- sh-4.4# df -h
- Filesystem Size Used Avail Use% Mounted on
- overlay 59G 3.5G 52G 7% /
- tmpfs 64M 0 64M 0% /dev
- shm 64M 0 64M 0% /dev/shm
我故意挑选 /home/qiya/testdir 和 /dev/shm/ ,这两个目录分别对应了 "/" 和 "/dev/shm/" 的挂载点的文件系统,分属两个不同的文件系统。我们先提前看下源文件的信息(主要是 inode 信息):
- sh-4.4# stat /dev/shm/source.txt
- File: /dev/shm/source.txt
- Size: 0 Blocks: 0 IO Block: 4096 regular empty file
- Device: 7fh/127d Inode: 163990 Links: 1
- Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
我们执行以下 mv 命令:
- sh-4.4# mv /dev/shm/source.txt /home/qiya/testdir/dest.txt
然后看下目的文件信息:
sh-4.4# stat dest.txt
- File: dest.txt
- Size: 0 Blocks: 0 IO Block: 4096 regular empty file
- Device: 78h/120d Inode: 3155414 Links: 1
- Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
对比有没有发现,inode 的信息是不一样的,inode number 是不一样的(是不是跟上面同一文件系统下的 mv 现象不一致)什么原因呢?我下面一一道来,从原理出剖析。
当系统调用 rename 的时候,如果源和目的不在同一文件系统时,会报告 EXDEV 的错误码,提示该调用不能跨文件系统。
- #define EXDEV 18 /* Cross-device link */
所以,rename 是不能用于跨文件系统的,这个时候怎么办?
划重点:这个时候操作分成两步走,先 copy ,后 remove 。
1. 第一步:走不了 rename ,那么就退化成 copy ,也就是真正的拷贝。读取源文件,写入目标位置,生成一个全新的目标文件副本;
- 这里调用的 copy_reg 的函数封装(要知道这个函数是 cp 命令的核心函数,在 深度剖析 Linux cp 的秘密 有深入剖析过 );
- ln,mv,cp 是在 coreutils 库里的命令,公用函数本身就是可以复用的;
2. 第二步:删除源文件,使用 rm 函数删除;
思考问题:mv 跨文件系统的时候,如果第一步成功了,第二步失败了(比如没有删除权限)会怎么样?
会导致垃圾。也就是说,目标处创建了一个新文件,源文件并没有删除。这个小实验有兴趣的可以试下。
cp 命令
cp 命令才是真正的数据拷贝命令,即拷贝元数据,也会拷贝数据。cp 命令也是我之前花了万字篇幅分析的命令,详细可见:深度剖析 Linux cp 的秘密。这里就不再赘述,下面提炼出关于拷贝的 3 种模式。
涉及到数据拷贝的,关键有个 --sparse 参数,可以控制拷贝数据的 IO 次数。
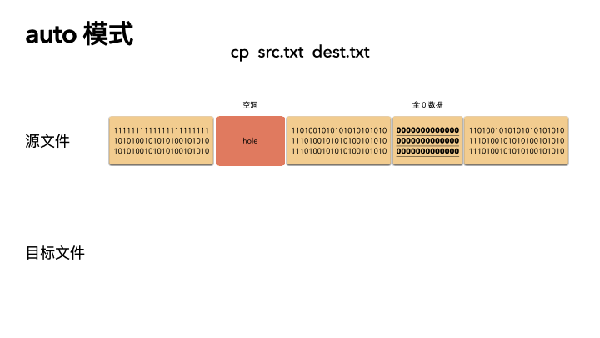
1 auto 模式
重点:跳过文件空洞。是 cp 默认的模式
- cp src.txt dest.txt
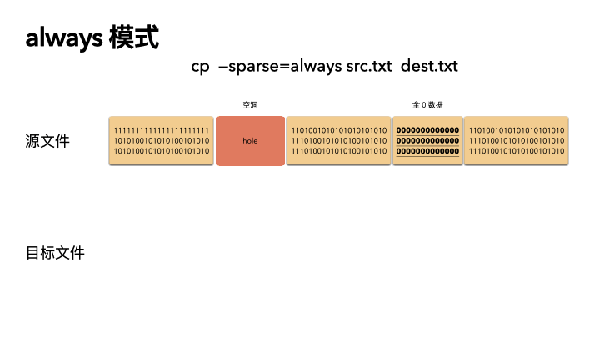
2 always 模式
重点:跳过文件空洞,还会跳过全 0 数据,是空间最省的模式。
- cp --sparse=always src.txt dest.txt
3 never 模式
重点:无脑拷贝,从头拷贝到尾,不识别物理空洞和全 0 数据,是速度最慢的一种模式
- cp --sparse=never src.txt dest.txt
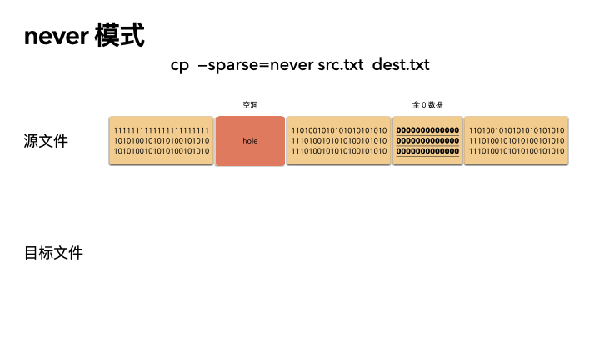
复用之前画的这 3 张图,很形象的体现了 cp 的行为。
总结
1. 目录文件是一种特殊的文件,可以理解成存储的是 dirent 列表。dirent 只是名字到 inode 的映射,这个是树形结构的基础;
2. 常说目录树在内存中确实是一个树的结构,每个节点由 dentry 结构体表示;
3. ln -s 创建软链接文件,软链接文件是一个独立的新文件,有一个新的 inode ,有新的 dentry,文件类型为 link,文件内容就是一条指向源的路径,所以软链的创建可以无视文件系统,跨越山河;
4. ln 默认创建硬连接,硬链接文件只在目录文件里添加了一个新 dirent 项 <新name:原inode>,文件 inode 还是和原文件同一个,所以硬链接不能跨文件系统(因为不同的文件系统是独立的一套 inode 管理方式,不同的文件系统实例对 inode number 的解释各有不同);
5. ln 命令貌似创建出了新文件,但其实不然,ln 只跟元数据相关,涉及到 dirent 的变动,不涉及到数据的拷贝,起不到数据备份的目的;
6. mv 其实是调用 rename 调用,在同一个文件系统中不涉及到数据拷贝,只涉及到元数据变更( dirent 的增删 ),所以速度也很快。但如果 mv 的源和目的在不同的文件系统,那么就会退化成真正的 copy ,会涉及到数据拷贝,这个时候速度相对慢一些,慢成什么样子?就跟 cp 命令一样;
7. cp 命令才是真正的数据拷贝命令,速度可能相对慢一些,但是 cp 命令有 --spare 可以优化拷贝速度,针对空洞和全 0 数据,可以跳过,从而针对稀疏文件可以节省大量磁盘 IO;















