












在我们对微服务架构有了整体的认识,并且具备了服务化的前提后,一个完整的微服务请求需要涉及到哪些内容呢?
这其中包括了微服务框架所具备的三个基本功能:
- 服务的发布与引用
- 服务的注册与发现
- 服务的远程通信
服务的发布与引用
首先我们面临的第一个问题是,如何发布服务和引用服务。具体一点就是,这个服务的接口名是啥,有哪些参数,返回值是什么类型等等,通常也就是接口描述信息。
常见的发布和引用的方式包括:
- RESTful API / 声明式Restful API
- XML
- IDL
一般来讲,不管使用哪种方式,服务端定义接口与实现接口都是必要的,例如:
- @exa(id = "xxx")
- public interface testApi {
- @PostMapping(value = "/soatest/{id}")
- String getResponse(@PathVariable(value = "id") final Integer index, @RequestParam(value = "str") final String Data);
- }
- }
具体实现如下:
- public class testApiImpl implements testApi{
- @Override
- String getResponse(final Integer index, final String Data){
- return "ok";
- }
- }
声明式Restful API
这种常使用HTTP或者HTTPS协议调用服务,相对来说,性能稍差。
首先服务端如上定义接口并实现接口,随后服务提供者可以使用类似restEasy这样的框架通过servlet的方式发布服务,而服务消费者直接引用定义的接口调用。
除此之外还有一种类似feign的方式,即服务端的发布依赖于springmvc controller,框架只基于客户端模板化http请求调用。这种情况下需接口定义与服务端controller协商一致,这样客户端直接引用接口发起调用即可。
XML
使用私有rpc协议的都会选择xml配置的方式来描述接口,比较高效,例如dubbo、motan等。
同样服务端如上定义接口并实现接口,服务端通过server.xml将文件接口暴露出去。服务消费者则通过client.xml引用需要调用的接口。
但这种方式对业务代码入侵较高,xml配置有变更时候,服务消费者和服务提供者都需要更新。
IDL
IDL是接口描述语言,常用于跨语言之间的调用,最常用的IDL包括Thrift协议以及gRpc协议。例如gRpc协议使用Protobuf来定义接口,写好一个proto文件后,利用语言对应的protoc插件生成对应server端与client端的代码,便可直接使用。
但是如果参数字段非常多,proto文件会显得非常大难以维护。并且如果字段经常需要变更,例如删除字段,PB就无法做到向前兼容。
一些tips
不管哪种方式,在接口变更的时候都需要通知服务消费者。消费者对api的强依赖性是很难避免的,接口变更引起的各种调用失败也十分常见。所以如果有变更,尽量使用新增接口的方式,或者给每个接口定义好版本号吧。
在使用上,大多数人的选择是对外Restful,对内Xml,跨语言IDL。
一些问题
在实际的服务发布与引用的落地上,还会存在很多问题,大多和配置信息相关。例如一个简单的接口调用超时时间配置,这个配置应该配在服务级别还是接口级别?是放在服务提供者这边还是服务消费者这边?
在实践中,大多数服务消费者会忽略这些配置,所以服务提供者自身提供默认的配置模板是有必要的,相当于一个预定义的过程。每个服务消费者在继承服务提供者预定义好的配置后,还需要能够进行自定义的配置覆盖。
但是,比方说一个服务有100个接口,每个接口都有自身的超时配置,而这个服务又有100个消费者,当服务节点发生变更的时候,就会发生100*100次注册中心的消息通知,这是比较可怕的,就有可能引起网络风暴。
服务的注册与发现
假设你已经发布了服务,并在一台机器上部署了服务,那么消费者该怎样找到你的服务的地址呢?
也许有人会说是DNS,但DNS有许多缺陷:
- 维护麻烦,更新延迟
- 无法在客户端做负载均衡
- 不能做到端口级别的服务发现
其实在分布式系统中,有个很重要的角色,叫注册中心,便是用于解决该问题。
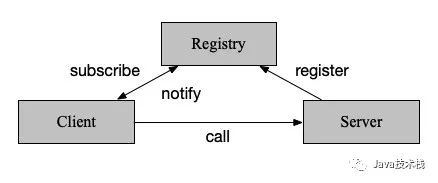
使用注册中心寻址并调用的过程如下:
- 服务启动时,向注册中心注册自身,并定期发送心跳汇报存活状态。
- 客户端调用服务时,向注册中心订阅服务,并将节点列表缓存至本地,再与服务端建立连接(当然这儿可以lazy load)。发起调用时,在本地缓存节点列表中,基于负载均衡算法选取一台服务端发起调用。
- 当服务端节点发生变更,注册中心能感知到后通知到客户端。
注册中心的实现主要需要考虑以下这些问题:
- 自身一致性与可用性
- 注册方式
- 存储结构
- 服务健康监测
- 状态变更通知
一致性与可用性
一个老旧的命题,即分布式系统中的CAP(一致性、可用性、分区容错性)。我们知道同时满足CAP是不可能的,那么便需要有取舍。常见的注册中心大致分为CP注册中心以及AP注册中心。
CP注册中心
比较典型的就是zookeeper、etcd以及consul了,牺牲可用性来保证了一致性,通过zab协议或者raft协议来保证一致性。
AP注册中心
牺牲一致性来保证可用性,感觉只能列出eureka了。eureka每个服务器单独保存节点列表,可能会出现不一致的情况。关注公众号Java技术栈,在后台回复:cloud,可以获取我整理的 Spring Cloud 系列教程,非常齐全。
从理论上来说,仅用于注册中心,AP型是远比CP型合适的。可用性的需求远远高于一致性,一致性只要保证最终一致即可,而不一致的时候还可以使用各种容错策略进行弥补。
保障高可用性其实还有很多办法,例如集群部署或者多IDC部署等。Consul就是多IDC部署保障可用性的典型例子,它使用了wan gossip来保持跨机房状态同步。
注册方式
有两种与注册中心交互的方式,一种是通过应用内集成sdk,另一种则是通过其他方式在应用外间接与注册中心交互。Spring Boot 系列教程整理好了:https://github.com/javastacks/spring-boot-best-practice
应用内
这应该就是最常见的方式了,客户端与服务端都集成相关sdk与注册中心进行交互。例如选择zookeeper作为注册中心,那么就可以使用curator sdk进行服务的注册与发现。
应用外
consul提供了应用外注册的解决方案,consul agent或者第三方Registrator可以监听服务状态,从而负责服务提供者的注册或销毁。而Consul Template则可以做到定时从注册中心拉取节点列表,并刷新LB配置(例如通过Nginx的upstream),这样就相当于完成了服务消费者端的负载均衡。
存储结构
注册中心存储相关信息一般采取目录化的层次结构,一般分为服务-接口-节点信息。
同时注册中心一般还会进行分组,分组的概念很广,可以是根据机房划分也可以根据环境划分。
节点信息主要会包括节点的地址(ip和端口号),还有一些节点的其他信息,比如请求失败的重试次数、超时时间的设置等等。
当然很多时候,其实可能会把接口这一层给去掉,因为考虑到接口数量很多的情况下,过多的节点会造成很多问题,比如之前说的网络风暴。
服务健康监测
服务存活状态监测也是注册中心的一个必要功能。在zookeeper中,每个客户端都会与服务端保持一个长连接,并生成一个session,在session过期周期内,通过客户端定时向服务端发送心跳包来检测链路是否正常,服务端则重置下次session的过期时间,如果session过期周期内都没有检测到客户端的心跳包,那么就会认为它已经不可用了,将其从节点列表中移除。
状态变更通知
在注册中心具备服务健康检测能力后,还需要将状态变更通知到客户端。在zookeeper中,可以通过监听器watcher的process方法来获取服务变更。
服务的远程通信
在上面,服务消费者已经正确引用了服务,并发现了该服务的地址,那么如何向这个地址发起请求呢?要解决服务间的远程通信问题,我们需要考虑一些问题:
- 网络I/O的处理
- 传输协议
- 序列化方式
网络I/O的处理
简单来说,就是客户端是怎么处理请求?服务端又是怎么处理请求的?关注公众号Java技术栈,在后台回复:面试,可以获取我整理的 Java 网络编程系列面试题和答案,非常齐全。
先从客户端来说,我们创建连接的时机可以是从注册中心获取到节点信息的时候,但更多时候,我们会选择在第一次请求发起调用的时候去创建连接。此外,我们往往会为该节点维护一个连接池,进行连接复用。
如果是异步的情况下,我们还需要为每一个请求编号,并维护一个请求池,从而在响应返回时找到对应的请求。当然这并不是必须的,很多框架会帮我们干好这些事情,比如rxNetty。
从服务端来说,处理请求的方式就可以追溯到unix的5种IO模型了。我们可以直接使用Netty、MINA等网络框架来处理服务端请求,或者如果你有十分的兴趣,可以自己实现一个通信框架。
传输协议
最常见的当然是直接使用Http协议,使用双方无需关注和了解协议内容,方便直接,但自然性能上会有所折损。
还有就是目前比较火热的http2协议,拥有二进制数据、头部压缩、多路复用等许多优良特性。但从自身的实践上看,http2要走到生产仍有一段距离,一个最简单的例子,升级到http2后所有的header names都变成小写,同时不是case-insenstive了,这时候就会有兼容性问题。
当然如果追求更高效与可控的传输,可以定制私有协议并基于tcp进行传输。私有协议的定制需要通信双方都了解其特性,设计上还需要注意预留好扩展字段,以及处理好粘包分包等问题。
序列化方式
在网络传输的前后,往往都需要在发送端进行编码,在服务端进行解码,这样主要是为了在网络传输时候减少数据传输量。
常用的序列化方式包括文本类的,例如XML/JSON,还有二进制类型的,例如Protobuf/Thrift等。在选择序列化的考虑上,一是性能,Protobuf的压缩大小和压缩速度都会比JSON快很多,性能也更好。二是兼容性上,相对来说,JSON的前后兼容性会强一些,可以用于接口经常变化的场景。
在此还是需要强调,使用每一种序列化都需要了解过其特性,并在接口变更的时候拿捏好边界。例如jackson的FAIL_ON_UNKNOW_PROPERTIES属性、kryo的CompatibleFieldSerializer、jdk序列化会严格比较serialVersionUID等等。













