本文转载自微信公众号「大数据技术与数仓」,作者西贝。转载本文请联系大数据技术与数仓公众号。
ODS层辨析
ODS全称是Operational Data Store,即操作数据存储。
Inmon VS Kimball
Bill.Inmon的定义:ODS是一个面向主题的、集成的、可变的、当前的细节数据集合,用于支持企业对于即时性的、操作性的、集成的全体信息的需求。常常被作为数据仓库的过渡,也是数据仓库项目的可选项之一。
而Kimball的定义:操作型系统的集成,用于当前、历史以及其它细节查询(业务系统的一部分);为决策支持提供当前细节数据(数据仓库的一部分)。
ODS VS DB VS EDW
ODS是用于支持企业日常的全局应用的数据集合,ODS的数据具有面向主题、集成的、可变的以及数据是当前的或是接近当前的特点。同样也可以看出ODS是介于DB和DW之间的一种过渡存储。
值得注意的是,Kimball所说的ODS是物理落地关系型数据库中,但是在实际生产应用中,ODS往往是物理落地在数据仓库中,比如Hive。
通常来说ODS是在数据仓库中存储业务系统源数据,所以从数据粒度、数据结构、数据关系等各个方面都与业务系统的数据源保持一致。但是,也不能仅仅将ODS层看做是业务系统数据源的一个简单备份,ODS和业务系统数据源的差异主要是由于两者之间面向业务需求是不同的,业务系统是面向多并发读写同时有需要满足数据的一致性,而ODS数据通常是面向数据报表等批量数据查询需求。
ODS层的设计思路
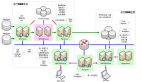
ODS层数据同步
上文提到ODS的数据来源于业务系统,且ODS落地的系统通常和业务系统是不同的,比如常见的将数据落到Hive中。所以,首先我们就需要将业务系统的数据抽取到ODS表中。一般来说,数据同步的方式大概可以分为三大类:文件抽取、数据库表的抽取和原始日志的抽取。
文件抽取
通常情况下,ODS层表的存储位置与业务系统表的存储位置是不一样的,比如业务表存在MySQL中,而ODS层存储在Hive中。另外,有的时候,ODS层需要对接多个不同类型的业务系统库,比如DB2、Oracle、Mysql等等,一种比较简单实用的做法是和各个业务系统约定好数据接口,并让业务系统按照数据接口格式生成数据文件和完结标示文件给到ODS。
这种方式有两个明显的优势:一方面可以降低ODS处理多种类型数据库系统能力需求,另一方面也减少了对业务系统的性能影响。但是这种方式也存在一些不足:数据的抽取过程和加载过程是分开的,由业务系统和ODS分别负责,同时接口新增和变更比较麻烦,需要较大的沟通维护成本,另外,数据落地到文件增加了额外的上传下载工作,会造成效率比较低。
在实际的生产过程中,这种方式的数据同步也很少被使用。
直连同步
直连同步是指通过定义好的规范接口API和基于动态链接库的方式直接连接业务库,比如ODBC/JDBC等规定了统一的标准接口,不同的数据库基于这套标准提供规范的驱动,从而支持完全相同的函数调用和SQL实现。比如经常使用的Sqoop就是采取这种方式进行批量数据同步的。
直连同步的方式配置十分简单,很容易上手操作,比较适合操作型业务系统的数据同步,但是会存在以下问题:
- 数据同步时间:随着业务规模的增长,数据同步花费的时间会越来越长,无法满足下游数仓生产的时间要求。
- 性能瓶颈:直连数据库查询数据,对数据库影响非常大,容易造成慢查询,如果业务库没有采取主备策略,则会影响业务线上的正常服务,如果采取了主备策略,虽然可以避免对业务系统的性能影响,但当数据量较大时,性能依然会很差。
- 抽取增量数据需要依靠修改业务系统,新增时间戳字段,并且按时间戳增量抽取的数据准确性不能得到保障,业务系统做数据补丁不更新时间戳字段将会导致漏数;
- 实时性差,只能在某个时刻抽取数据,不能满足准实时数据需求;
在实际的生产过程中,这种方式的数据同步经常被使用,值得注意的是:数据库直连抽取比较适用于小批量表的数据抽取,对于大批量的数据而言,性能会比较差。
日志解析
据库日志抽取是指通过分析数据库日志,将业务系统的DDL和DML语句在一个镜像系统还原,并通过数据流的方式对外提供实时数据服务。
所谓日志解析,即解析数据库的变更日志,比如MySQL的Binlog日志,Oracle的归档日志文件。通过读取这些日志信息,收集变化的数据并将其解析到目标存储中即可完成数据的实时同步。这种读操作是在操作系统层面完成的,不需要通过数据库,因此不会给源数据库带来性能上的瓶颈。
由于是数据库日志抽取是获取所有的变更记录,落地到ODS表的时候我们需要根据主键去重按照日志时间倒排序获取最后状态的变化情况。通常使FULL OUTER JOIN全外连接的方式进行Merge数据。
数据库日志解析的同步方式可以实现实时与准实时的同步,延迟可以控制在毫秒级别的,其最大的优势就是性能好、效率高,不会对源数据库造成影响,目前,从业务系统到数据仓库中的实时增量同步,广泛采取这种方式。
当然,任何方式都不是完美的,使用日志解析的方式进行数据同步也会存在一些已知的问题:比如在业务系统做批量补数时会造成数据更新量超过处理的能力,从而导致数据延迟。另外,这种方式需要额外补数一个实时抽取的系统,从而也增加了投入和处理的复杂性。
该如何选择同步方式
在实际的生产环境中,直连同步和日志解析是非常普遍的两种数据同步方式,随着实时技术的发展,使得实时数据同步的方式变得越来越方便,越来越多的企业开始尝试使用日志解析的方式进行数据同步。这里需要注意的是,每种方式都有其优缺点及适用的场景,找到合适的方式就是最好的方式,切不可一味的追求狂拽酷炫的同步技术,这也是很多技术人员经常犯的错误,应用和钻研新技术是技术人的追求,但是过犹不及,在解决具体问题的时候,要多方面权衡。
另外,数仓的建设是为业务服务的,应该把时间和精力放在如何支持业务、如何发挥数仓的价值、如何用数据为业务提供支持决策上来。笔者认为,数仓的建设不是一堆大数据技术的简单堆砌,深入理解业务和数据才是数仓建设的第一要义。
ODS层数据清洗
关于ODS层是否做数据清洗一直是存在争议的,但有一点是可以确定的,对于比较重的清洗工作是要留到后面数仓的ETL过程中进行处理。
但是,有这么一种情况:我们在长期的生产实际过程中,发现部分已知的数据问题的处理可以通过自动化的方式来处理,这种方式通常在数据入库之前,做额外的加工处理后再做入库操作。
数据清洗的主要工作是处理那些不符合要求的数据,从而提升数据质量,比如一些常见的问题:错误的数据、重复的数据
- 错误的数据
这种错误通常是业务系统处理不够健全造成的,比如字符串数据后面有回车空格、日期格式不正确、日期越界等等,这些问题如果不在ODS层做处理,后续的解析处理过程中也是要留意处理的
- 重复的数据
例如,一些前端系统迁移过后的新老表融合可能会存在大量的重复历史数据,这也可以在数据清洗这一步骤中完成消除重复数据的操作。需要注意的是,在数据清洗后还需要对ODS的数据做稽核,还需要对脏数据做稽核校验,脏数据的校验主要集中在数据量上,如果数据量波动特别大则需要人工介入处理。
其实,在大多数的情况下,是不需要做数据清洗处理的,可以把这个清洗环节放到后面的明细层ETL中进行处理。
ODS层表设计
通常而言,ODS层表跟业务系统保持一致,但又不完全等同于业务系统。在设计ODS物理表时,在表命名、数据存储等方面都需要遵循一定的准则。
命名
比如:不管是表命名还是字段命名尽量和业务系统保持一致,但是需要通过额外的标识来区分增量和全量表,”_delta”来标识该表为增量表。
存储
另外,为了满足历史数据分析需求,我们需要在ODS表中加一个时间维度,这个维度通常在ODS表中作为分区字段。如果是增量存储,则可以按天为单位使用业务日期作为分区,每个分区存放日增量的业务数据。如果是全量存储,只可以按天为单位使用业务日期作为分区,每个分区存储截止到当前业务时间的全量快照数据。
ODS层常见的问题
实时和准实时数据需求、数据飘移处理、巨型数据量表处理、如何有效控制数据存储。
实时性
实时数据仓库的主要思想就是:在数据仓库中,将保存的数据分为两类,一种为静态数据,一种为动态数据,静态数据满足用户的查询分析要求;而动态数据就是为了适应实时性,数据源中发生的更新可以立刻传送到数据仓库的动态数据中,再经过响应的转换,满足实时的要求。
由于实时处理的特殊性及复杂性,很多情况下实时分析是建立在ODS上而不是数据仓库上,因为ODS处理逻辑简单,数据链路相对较短,产出更快。
根据表的刷新频率,可以将ODS层的表分为三大类:
- 实时ODS
接近实时地与业务库的数据保持同步刷新,主要用于实时分析计算,比如实时的反欺诈,天猫双11实时大屏等等。这类表的ETL是实时进行的,一般情况下,这类表会存储在消息中间件中,比如Kafka,指的注意的是:要求涉及的业务过程不能过多,处理的业务逻辑不能过于复杂。这类ODS的表一般只是用于实时计算,相比批处理的表而言,其维护成本是相对较高的。
- 准实时ODS
例如15分钟到1小时刷新一次,这类ODS比实时ODS成本要低些,基本可以满足大部分的准实时需求。并且可以根据实际需求调整刷新频率,具有较好的灵活性。在做处理这类准实时的ODS表时,需要特别注意ETL任务的产出效率,通常这类任务的产出时间最多不能超过ODS表的刷新周期时间。例如小时级别的表,任务不能超过1个小时。
- 传统ODS
这是离线数仓最常见的一种表,即T+1,其数据一天刷新一次,可以利用业务系统的空闲时间进行刷新(通常是每天凌晨0-2点),可实现所有业务系统的数据集成和刷新。刷新频率的下降也给系统有更多的时间进行数据更正和清洗。该类ODS层的表是最容易维护的。
数据漂移
所谓数据漂移,指的是这样一种现象:ODS表的同一个业务日期数据中包含前一天或后一天凌晨附近的数据或者丢失当天的变更数据。
由于ODS需要承接面向历史的细节数据查询需求,这就需要物理落地到数据仓库的ODS表按时间段来切分进行分区存储,通常的做法是按某些时间戳字段来切分,实际往往由于时间戳字段的准确性问题导致数据飘移问题的发生。
一般情况下,我们使用的时间戳分为三类:
- 数据库表中用来标示数据记录更新的时间戳字段(即数据记录的update时间,如modified_time)
- 数据库日志中标示数据记录的更新时间的时间戳字段(如log_time)
- 数据库表中的用来记录具体业务过程的发生时间(如proc_time)
在实际的生产过程中,以上三个时间戳往往会存在差异:比如由于网络或者系统压力问题,log_time或者modified_time会晚于proc_time。
当时用数据库记录更新时间或者数据库日志更新时间进行切分数据分区时,有可能会导致凌晨时间产生的数据记录漂移到后一天,如果使用业务时间进行限制,则会遗漏很多其他过程的变化记录。
那么,该如何解决上述的问题呢?常见的方式有两种:
- 多冗余数据
基本原则是宁多勿少,即ODS每个时间分区中向前向后都多冗余一些数据,具体的数据切分让下游根据自身不同的业务场景根据不同的业务时间proc_time来限制。这种情况同样也会存在一些误差:比如一个订单是在6.1日支付的,但在6.2号凌晨申请退款关闭了该条订单,那该条订单记录就会被更新,下游再统计支付订单状态时会错误统计。
- 多个时间戳字段限制时间来获取相对准确的数据
- 首先确保数据不遗漏,根据log_time分别冗余前一天最后15分钟的数据和后一天凌晨开始15分钟的数据,并用modified_time过滤非当天数据,此时会过滤掉一部分后一天凌晨开始15分钟的数据,但是还是会冗余一部分前一天的数据,由于log数据保存了多个状态的数据,所以还需要根据log_time进行降序排列,获取最新状态的记录,这样就去掉了中间状态的数据。
- 下一步就是处理漂移到后一天的数据,根据log_time取后一天的15分钟数据;针对此数据,按照主键根据log_time作升序排列去重。因为我们需要获取的最接近当天记录变化情况(数据库日志数据将保留所有变化的数据,但是落地到ODS的表是需要根据主键去重获取最后状态的变化情况),这样就会把漂移到后一天的最初状态的数据筛选出来了。
- 最后将前两步的结果数据作全外连接,限定业务时间proc_time来获取我们需要的数据
数据存储
- 避免重复抽取数据,
这种情况在中小公司基本上不会存在,但是在大型的集团公司,不同的数据团队负责不同的数据集市或者业务,会存在重复同步数据源的情况,解决这类问题的首要措施不是技术上而是管理上的,必须建立统一的ODS层,收拢权限,由专门的团队统一管控。
- 表的生命周期管理
一般而言,全量表保存3~7天,增量表要永久保存
- 无下游任务的表
比如一些表上源表不产生数据了,或者该表没有被下游任务使用,这种情况下要及时下线同步任务,避免造成资源的浪费。